






Datawhale干货
作者:邓恺俊,Datawhale成员
项目代码可见:unlock-deepseek/Datawhale-R1(https://github.com/datawhalechina/unlock-deepseek),欢迎关注和 star!
其余所有开源内容见文末。
各位同学好,我是来自 Unlock-DeepSeek 团队的邓恺俊。
之前有同学问:主播主播,你们团队的复现的 R1 Zero 确实很强,但是还是太耗算力资源,没 3 张 A800 啊,还有没有更经济更简单的方式来学习 R1 Zero 的复现呢?
有的,兄弟,有的有的,像这样的方案还有九个(开玩笑)。今天我们来介绍一个有趣的方法,能够让你在单卡复现 DeepSeek R1 Zero,甚至只用一块 4090 显卡也能轻松实现!
为什么单卡就能复现?
你可能会问:“原来需要 3 张 A800,如今怎么只需单卡?这其中有什么黑科技?” 答案就在于我们引入了 Unsloth + LoRA。
Unsloth 的核心优势在于:
强化学习算法优化:集成了多种强化学习(RL)算法,并通过底层代码优化(如优化计算图、减少冗余操作),显著提升了大模型在推理和微调时的性能。
最新量化技术:大幅降低显存消耗,使得原本需要多卡的大模型也能在单卡上运行。
完整的 LoRA 和 QLoRA 微调支持:即使显存有限,也能通过少量资源复现 R1 Zero。
这就为我们提供了一个成本更低、实现更简单的方案。Unsloth 官方博客提到:仅需 7G VRAM,就能训练 Qwen2.5-1.5B 的模型。
Unsloth GitHub:https://github.com/unslothai/unsloth
环境搭建
安装 Unsloth
环境搭建部分在之前的公众号文章中已有详细说明,这里只需在原有基础上补充安装 Unsloth 及指定版本的 trl 库即可。
补充说明:在之前公众号发布的多卡训练代码中,错误的引入了“思考长度奖励函数”,并且没有在代码中使用 flash-attn,Unlock-DeepSeek 团队已经修复代码,请使用仓库中的最新代码,我们同时更新一版训练示意图。
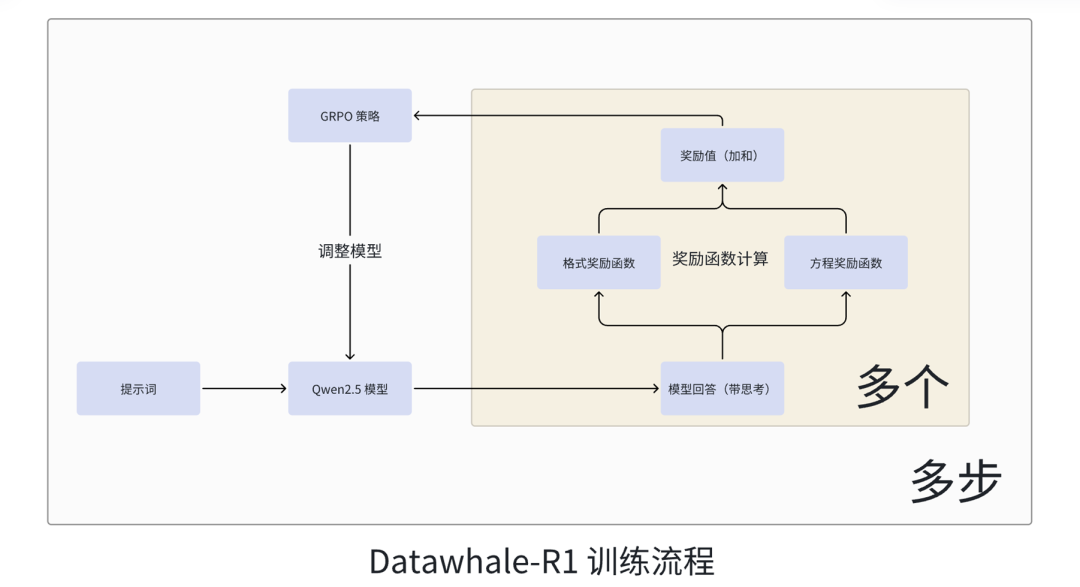
本文中仅展示与前文有差异的代码部分,同时我们提供了完整的训练代码,请在文末获取。
注意:为了兼容 Unsloth,我们需要安装特定版本的 trl。具体命令如下:
# 安装 unsloth 和 vllm
pip install unsloth vllm
# 安装指定版本的 trl(兼容 unsloth)
pip install trl==0.15.0参考自:https://docs.unsloth.ai/get-started/unsloth-notebooks配置文件修改
大部分配置与之前的 Datawhale-R1.yaml 文件保持一致。为了支持单卡复现 R1 Zero,我们做了如下调整:
LoRA 参数设置:启用 LoRA 微调,调整 LoRA 秩数(lora_r)为 64(常用的选择有 8、16、32、64、128 等),并设置 lora_alpha 为 32。
限制回答长度:将 max_completion_length 设置为 1024,以控制输出长度。
优化器调整:优化器设置为 adamw_8bit,以加速训练。
注意:为了更节省内存,这里的 max_completion_length 被设置为 1024,但是这可能会影响模型的发挥,如果你的资源充足,设置更高(4096、8196)可能会获得更好的效果,但是也会加重资源消耗。若内存不足可以调节 vllm_gpu_memory_utilization,适当降低。除此之外,如果有更多资源,可以考虑将优化器 optim 调整为 adamw_torch,这有助于更好地复现模型。
# LoRA 参数调整
lora_r: 64 # LoRA 秩数,选择任意大于 0 的数字!建议使用 8, 16, 32, 64, 128
lora_alpha: 32 # LoRA alpha 值
# 训练参数
learning_rate: 1.0e-5 # 学习率,调整为1e-5
# GRPO 算法参数
beta: 0.001 # KL 惩罚因子
optim: adamw_8bit # 使用 8bit 优化器以加速训练
max_prompt_length: 256 # 输入 prompt 的最大长度
max_completion_length: 1024 # 输出回答长度,包含推理思维链
num_generations: 4
use_vllm: true # 启用 vLLM 加速推理
vllm_gpu_memory_utilization: 0.4 # vLLM 的 GPU 内存利用率(内存紧张时可适当降低)LoRA微调参考:https://zhuanlan.zhihu.com/p/663557294
启动训练
启动训练的代码很简单,由于我们只需要单卡,不需要涉及到配置复杂的 Accelerate 库,直接运行以下代码即可运行。
python train_Datawhale-R1_unsloth.py --config Datawhale-R1_unsloth.yaml训练代码优化解读
基于 Unsloth 框架,我们对原始代码做了简化和优化。主要思路有两点:
打补丁提升训练速度
在执行强化学习训练的代码之前,我们添加了两行代码,利用 PatchFastRL 函数对某些 RL 算法(如 GRPO)进行“打补丁”。这个操作实际上在底层优化了计算图、减少了冗余计算,从而加速训练过程。
from unsloth import FastLanguageModel, PatchFastRL
PatchFastRL("GRPO", FastLanguageModel) # 对 GRPO 算法打补丁GRPO 训练函数的改进
除此之外,我们还改进了 grpo_function 里面的函数,在这之中进行了一些优化,具体在代码的 14~34 行中,具体来说,我们加入以下两个方式:
模型加载:通过 FastLanguageModel.from_pretrained 方法加载预训练模型,并启用 vLLM 快速推理,同时支持 4 位加载(或 LoRA 16 位)。
PEFT 微调:利用 get_peft_model 方法对模型应用 LoRA 微调,指定了目标模块、LoRA 参数以及梯度检查点,确保在有限显存条件下依然能有效训练。
# 定义 GRPO 训练函数
def grpo_function(
model_args: ModelConfig,
dataset_args: DatasetArguments,
training_args: GRPOConfig,
callbacks: List,
):
# 记录模型参数
logger.info(f"Model parameters {model_args}")
# 记录训练/评估参数
logger.info(f"Training/evaluation parameters {training_args}")
# 从预训练模型加载模型和分词器
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_args.model_name_or_path, # 模型名称或路径
fast_inference=True, # 启用 vLLM 快速推理
load_in_4bit=True, # 是否以 4 位加载模型,False 表示使用 LoRA 16 位
max_lora_rank=model_args.lora_r, # 设置 LoRA 的最大秩
max_seq_length=training_args.max_completion_length, # 设置最大序列长度
gpu_memory_utilization=training_args.vllm_gpu_memory_utilization, # GPU 内存利用率,若内存不足可减少
attn_implementation=model_args.attn_implementation, # 设置注意力实现方式 flash attention
)
# PEFT 模型
model = FastLanguageModel.get_peft_model(
model,
r = model_args.lora_r,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj", # 如果 OOM 内存不足,可以移除 QKVO
"gate_proj", "up_proj", "down_proj",
],
lora_alpha = model_args.lora_alpha, # 设置 LoRA 的 alpha 值
use_gradient_checkpointing = "unsloth", # 启用 unsloth 的梯度检查
random_state = training_args.seed, # 设置随机种子
)如果遇到 Out of Memory 显存不足问题,可以移除 target_modules 中的 "q_proj", "k_proj", "v_proj", "o_proj"。
参考自:https://unsloth.ai/blog/r1-reasoning
模型量化参考:LLM量化综合指南(8bits/4bits)https://zhuanlan.zhihu.com/p/671007819
训练结果与一些思考
以下是训练结果的部分截图,大致与我们复现 Tiny Zero 和 Mini R1 的结果类似,这里就不再做详细分析。

接下来分享一些学习 R1 Zero 过程中的思考(非严谨学术研究,个人观点,仅供参考)。
Aha moment 是 RL 训练的结果吗?
在开始研究之前,我对 Aha moment(顿悟时刻)这个概念充满好奇,这仿佛是 DeepSeek 在经过 RL 训练后突然获得的超能力。但深入学习阅读了 oat 的文章后,发现 Aha moment 并不是凭空出现的,它可能在 base 模型和 SFT 阶段就已经埋下了种子。RL 训练做的事情,更像是一个"放大器",通过设计的奖励机制,最大化了模型产生顿悟时刻的概率。换句话说,RL 训练将模型原本浅层的自我反思能力,转化为更有深度和效果的思考过程。
参考OAT文章:There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study:https://oatllm.notion.site/oat-zero
思考长度越长越有效吗?
在社区中有一种普遍的看法:RL 训练让模型的输出变得更长,从而提升效果。这个观点确实有一定道理,因为 RL 强化了模型的思考过程,生成更多的 token 是自然的结果。
然而,问题是:更长的思考真的意味着更好的结果吗?
在复现 Tiny Zero 的过程中,我观察到一个有趣的现象:token 数量呈现先降后升的趋势。这个现象可以这样解释:最初,由于存在格式奖励(format reward),模型必须保证格式正确,然而长度过长的输出比较难学习到答案的格式,并且会包含很多对解决任务无用的 token,所以 token 数量自然先会下降,模型先学简单的格式,保留有利于正确计算的 token,再去学复杂的计算,先简后繁;随着训练的进行,模型开始进行更多的尝试和反思以得出正确答案,输出长度逐渐增加并趋于稳定。这一观察也印证了 OAT 的结论:输出长度与自我反思的质量并不一定存在线性关联。
S1 文章的一些结论和思考
最近我也看了李飞飞团队的 S1 文章,详细分析了其方法和 R1 Zero 的不同。总的来说,S1 通过少量高质量数据(约 1k + SFT + 设计 Prompt)进行训练,而 R1 Zero 则是通过基础训练(Base)加 RL 强化训练完成的。在 S1 中,他们采用了 budget forcing 方法,在测试时强制设定最大和最小的思考 token 数量。具体而言:
通过添加 "end-of-thinking token 分隔符" 和 "Final Answer" 来控制思考上限;
通过禁止生成分隔符并添加 "wait" 提示词来控制思考下限。
实验结果表明,适度增加思考 token 数量确实能够提升模型在 AIME24 基准测试上的表现。然而,他们也发现,过度抑制思考结束反而会导致模型陷入无效循环。这个发现非常符合直觉:就像人类的思考一样,简单问题(比如数一个单词中的字母数量)并不需要过度思考,而真正需要延长思考时间的,往往是那些较为复杂的问题。
s1参考阅读:16张H100训26分钟,超越o1-preview!李飞飞等用1K样本,揭秘测试时Scaling
总结与展望
首先再次感谢 Unsloth 的优化和社区小伙伴的努力,这不仅使得大模型的训练和推理更加高效,还大幅降低了显存消耗,使得即便是仅一块显卡,也能轻松完成 R1 Zero 的复现,这也提供了一个更经济、更简便的复现方案,也为低资源环境下的大模型应用开辟了新的可能。
同时我们也计划深入探讨 R1 的蒸馏方法,以进一步降低模型的计算需求并提高其可扩展性。此外,我们也将持续优化代码和算法,推动更多开源社区的创新和合作。我们欢迎大家参与讨论和分享,期待和大家一起在开源社区中共创更多精彩内容。
完整文件获取
Unlock-DeepSeek 团队后续会陆续发布更多关于 DeepSeek 相关工作解读的文章,敬请关注,我们下次再见!
Unlock-DeepSeek 项目主页:https://datawhalechina.github.io/unlock-deepseek/
Github 仓库:https://github.com/datawhalechina/unlock-deepseek
Gitee 国内仓库:https://gitee.com/anine09/unlock-deepseek
Swanlab 实验数据:https://swanlab.cn/@Kedreamix/Datawhale-R1-by_Kedreamix/runs/sqxeo1i3v8hgzclm3nwkk
复现文件在 Datawhale-R1 文件夹,请仔细阅读 Datawhale-R1/README.md。
Unlock-DeepSeek 项目目前并不完善,并且正在快速迭代,请持续关注。
 一起“点赞”三连↓
一起“点赞”三连↓

















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









