







岭回归在寻找参数的时候,需要考虑到惩罚项:

那么,这里的gamma最好是多少呢?在sklearn中,常常用alpha表示这个参数。
Sklearn岭回归参数优化
1.生成数据集
from sklearn.datasets import make_regression
reg_data, reg_target = make_regression(n_samples = 100, n_features = 2, effiective_rank = 1. noise = 10)
2. 留一法交叉验证
linear_models模块有个函数是RidgeCV(), 代表ridge cross-validation,它本质上就是一种留一法交叉验证leave-one-out-cross-validation(LOOCV)
from sklearn.linear_model import RidgeCV
rcv = RidgeCV(alphas = array([0.1, 0.2, 0.3, 0.4]))
rcv.fit(reg_data, reg_target)
当我们fit数据以后,最佳的alpha就出来了:
rcv.alpha_
3. 如果,你想自定义loss函数
如图,定义好MAD代价函数

使用sklearn制作loss函数

make_scorer函数用于制作代价函数,将自定义的代价函数通过RidgeCV的scoring参数指定
获取最小的alpha:
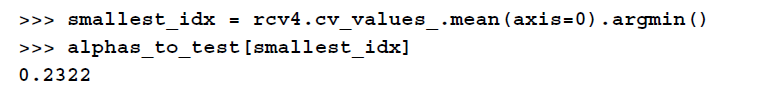














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









