







前言
在上一章【课程总结】day28:大模型之深入探索RAG流程中,我们对RAG流程中 文档读取(LOAD) -> 文档切分(SPLIT) -> 向量化(EMBED) -> 存储(STORE) 进行了深入了解,本章将接着深入了解 解析(Retrieval) 的使用
解析器简介
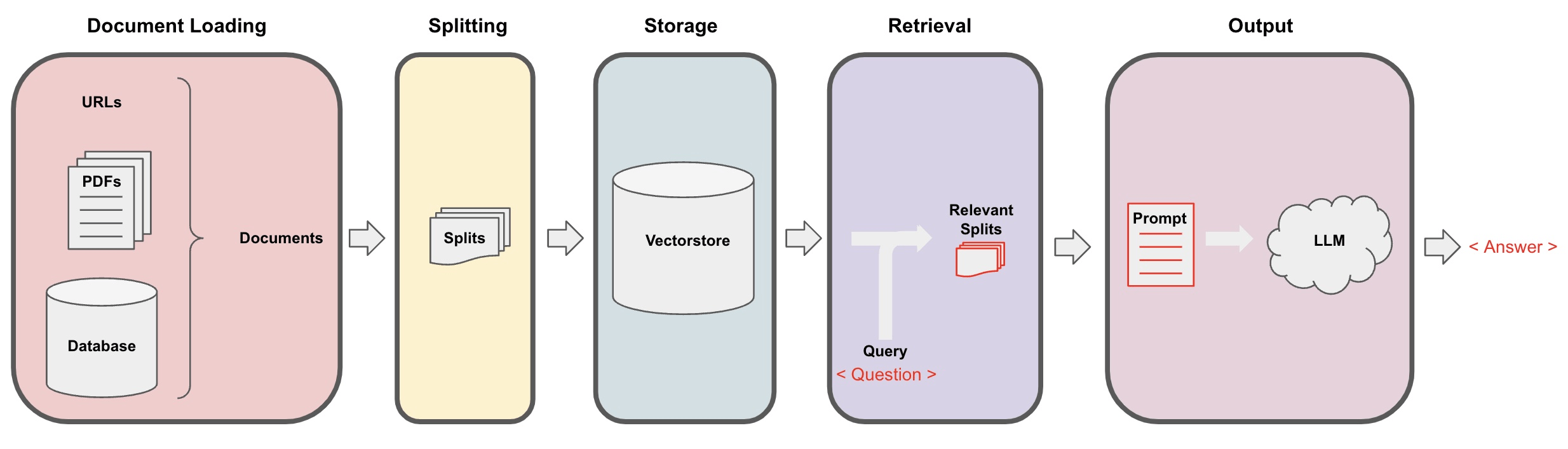
简介:在 RAG(Retrieval-Augmented Generation)流程中,Retrieval(检索)是关键环节,其主要目标是从大量文档或知识库中提取与用户查询相关的信息。
目的:
- 信息获取:根据用户的查询,从外部知识库中获取相关文档或片段,以增强生成模型的上下文信息。
- 提高准确性:通过提供具体的、相关的信息,帮助生成模型(如语言模型)产生更准确和上下文相关的回答。
流程
- 用户查询:用户输入一个查询或问题。
- 检索器:使用检索算法(如 BM25、TF-IDF 或基于嵌入的检索)搜索知识库,找到与查询最相关的文档。
- 文档评分:对检索到的文档进行评分,通常依据相关性得分来排序。
- 返回结果:将最相关的文档或片段返回给生成模型。
解析器的基础使用
创建知识库
第一步:启动Chroma数据库
chroma run --path chroma_xiyou --port 8000
第二步:使用RAG基础流程:Load->Split->EMBED->STORE创建一个知识库
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders import PyMuPDFLoader
from langchain_chroma import Chroma
from chromadb import Settings
from chromadb import Client
from utils import get_ernie_models
import chromadb
# 连接大模型
llm_ernie, chat_ernie, embed_ernie = get_ernie_models()
# 初始化 HuggingFaceEmbeddings
embedding_function = HuggingFaceEmbeddings(model_name="bert-base-chinese")
# 加载文档
pdf_loader = PyMuPDFLoader("testfiles/西游记.pdf")
documents = pdf_loader.load()
# 切分文档
spliter = RecursiveCharacterTextSplitter(chunk_size=128, chunk_overlap=64)
docs = spliter.split_documents(documents)
# 配置连接信息
client = chromadb.HttpClient(host='localhost', port=8000)
chroma_db = Chroma(
embedding_function=embedding_function,
client=client
)
batch_size = 6 # 每次处理的样本数量
# 分批入库
for i in range(0, len(docs), batch_size):
batch = docs[i:i + batch_size] # 获取当前批次的样本
print(f'Processing batch {
i} to {
i + batch_size}, total {
len(batch)} samples')
chroma_db.add_documents(documents=batch) # 入库
说明:
- 向量化说明:由于Qwen和百度千帆的向量接口限制较多,对于向量化西游记这本书来说,经常会遇到超出限制等问题,所以此处我将向量化接口换为HuggingFaceEmbeddings(),该接口可能会存在被Ban的风险,请自行更换向量化接口。
- 测试文档:西游记下载地址请见夸克网盘:西游记
创建解析器
第三步:创建一个解析器
retriever = chroma_db.as_retriever()
创建chain链
创建chain链有两种方法:一种是管道符连接,一种是使用 create_retrieval_chain 。本章我们两种方法都做尝试,以便对比代码的写法。
方式一:传统的管道符构建chain
# RAG系统经典的 Prompt
prompt = ChatPromptTemplate.from_messages([
("human", """You are an assistant for question-answering tasks. Use the following pieces
of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:""")
])
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# RAG 链
rag_chain = (
{
"context": retriever | format_docs,
"question": RunnablePassthrough()}
| prompt
| chat_ernie
| StrOutputParser()
)
rag_chain.invoke(input="孙悟空三打白骨精时,白骨精分别变成了哪些形态?")
运行结果:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











