







【K8S学习笔记-004】Pod详解(原理,init container,Pod调度,健康检查,生命周期)
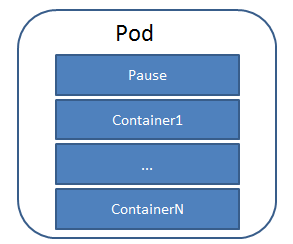
Pod
每个Pod都有一个特殊的被称为“根容器”的Pause容器。除此之外,每个Pod还包含一到多个紧密相关的用户业务容器。
为什么 Kubernetes会设计出一个全新的Pod的概念并且Pod有这样特殊的组成结构呢?
- 在一组容器作为一个单元的情况下,我们难以对“整体”简单地进行判断及有效地进行行动。
比如容器死亡了,此时算是整体死亡么?是N/M的死亡率么?
引入业务无关并且不易死亡的Pause容器作为Pod的根容器, 以它的状态代表整个容器组的状态,就简单巧妙地解决了这个难题。 - Pod里的多个业务容器共享 Pause容器的IP, 共享 Pause容器挂载的 Volume
这样既简化了密切关联的业务容器之间的通信问题,也很好地解决了它们之间的文件共享问题。 - Kubernetes为每个Pod都分配了唯一的IP地址,称之为 Pod IP,一个Pod里的多个容器共享PodP地址。
Kubernetes要求底层网络支持集群内任意两个Pod之间的TCP/IP直接通信,这通常采用虚拟二层网络技术来实现,例如 Flannel、 Openvswitch等。
Pod有两种类型: 普通的Pod及静态Pod( static Pod)
- 静态Pod:比较特殊, 它并不存放在Kubernetes的etcd存储里, 而是存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动运行。
- 普通Pod:一旦被创建,就会被放入到etcd中存储,随后会被 Kubernetes master调度到某个具体的Node上并进行绑定( Binding),随后该Pod被对应的Node上的 kubelet进程实例化成一组相关的 Docker容器并启动起来。在默认情况下,当Pod里的某个容器停止时Kubernetes会自动检测到这个问题并且重新启动这个Pod(重启Pod里的所有容器),如果Pod所在的Node宕机,则会将这个Node上的所有Pod重新调度到其他节点上。
# yaml格式的pod定义文件完整内容:
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清楚,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure]#Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
————————————————
原文链接:https://blog.csdn.net/random_w/article/details/80612881

Pod原理
为什么要有pod?
前面我们说过, Pod 是 Kubernetes 项目中最小的 API 对象。
那, 为什么我们会需要 Pod 呢? 为什么不直接以 Container 为调度单位呢?
首先, 我们要明确一点:容器的本质是进程
在一个真正的操作系统里,进程并不是“孤苦伶仃”地独自运行的,而是以进程组的方式,“有原则地”组织在一起。
例如我们执行 pstree -g :
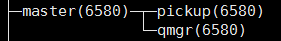
可以看到:主程序master, 和pickup, qmgr同属6580进程组, 它们相互协作,共同完成 master 程序的职责。
PS: 这里提到的进程, 如master 对应的 pickup, qmgr , 严格意义上来说,其实是 Linux 操作系统语境下的“线程”。
这些线程,或者说,轻量级进程之间,可以共享文件、信号、数据内存、甚至部分代码,从而紧密协作共同完成一个程序的职责。
同理,这里提到的“进程组”,对应的也是 Linux 操作系统语境下的“线程组”。
这种命名关系与实际情况的不一致,是 Linux 发展历史中的一个遗留问题。
对这个话题感兴趣的同学,可以阅读这篇技术文章来了解一下:https://www.ibm.com/developerworks/cn/linux/kernel/l-thread/index.html
Kubernetes 项目所做的,其实就是将“进程组”的概念映射到了容器技术中,并使其成为了这个云计算“操作系统”里的“一等公民”。
如果事先没有“组”的概念,有些运维关系就会非常难以处理.
例如:
有A,B,C三个进程, 每个进程需要配额1G的内存, 它们必须要运行在同一台机器上.
如果要对这三个进程容器化, 由于受限于容器的 “单进程模型” , 也必须要做三个容器.
PS:强调一下, 容器的单进程模型并不是指容器里只能运行“一个”进程,而是指容器没有管理多个进程的能力。
因为容器里 PID=1 的进程就是应用本身,其他的进程都是这个 PID=1 进程的子进程。
我们的应用不能够像操作系统里的 init 进程或者 systemd 那样拥有进程管理的功能。
比如,你的应用是一个 Java Web 程序(PID=1),然后你执行 docker exec 在后台启动了一个 Nginx 进程(PID=3)。
可是,当这个 Nginx 进程异常退出的时候,你该怎么知道呢?这个进程退出后的垃圾收集工作,又应该由谁去做呢?
假设我们的 Kubernetes 集群上有两个node节点:node1 上有 3 GB 可用内存,node2 有 2.5 GB 可用内存。
这时,假设我要用 Docker Swarm 来运行这三个程序。
为了能够让这三个容器都运行在同一台机器上,我必须在另外两个容器上设置一个 affinity=A(与 main 容器有亲密性)的约束,即:它们俩必须和 main 容器运行在同一台机器上。
然后,我顺序执行:docker run A docker run B 和 docker run C,创建这三个容器。
这样,这三个容器都会进入 Swarm 的待调度队列。然后,A容器被调度到了node2上 (这种情况太正常了 !)
接下来, 由于亲密性约束, B也被调度到node2上.
当 C 容器出队开始被调度时,Swarm 就懵了:node2 上的可用资源只有 0.5 GB 了,并不足以运行 C 容器;可是,根据 affinity=A 的约束,C 容器又只能运行在 node2 上。
这就是一个典型的成组调度 gang scheduling没有被妥善处理的例子。
在工业界和学术界,关于这个问题的讨论可谓旷日持久,也产生了很多可供选择的解决方案。
比如,Mesos 中就有一个资源囤积(resource hoarding)的机制,会在所有设置了 Affinity 约束的任务都达到时,才开始对它们统一进行调度。而在 Google Omega 论文中,则提出了使用乐观调度处理冲突的方法,即:先不管这些冲突,而是通过精心设计的回滚机制在出现了冲突之后解决问题。
可是这些方法都谈不上完美。资源囤积带来了不可避免的调度效率损失和死锁的可能性;而乐观调度的复杂程度,则不是常规技术团队所能驾驭的。
不过,在 Kubernetes 项目里,这样的问题就迎刃而解了:Pod 是 Kubernetes 里的原子调度单位。
这就意味着,Kubernetes 项目的调度器,是统一按照 Pod 而非容器的资源需求进行计算的。
所以,像 A, B, C 这样的三个容器,正是一个典型的由三个容器组成的 Pod。
Kubernetes 项目在调度时,自然就会去选择可用内存等于 3 GB 的 node1 节点进行绑定,而根本不会考虑 node2。
像这样容器间的紧密协作,我们可以称为“超亲密关系”。这些具有“超亲密关系”容器的典型特征包括但不限于:互相之间会发生直接的文件交换、使用 localhost 或者 Socket 文件进行本地通信、会发生非常频繁的远程调用、需要共享某些 Linux Namespace(比如,一个容器要加入另一个容器的 Network Namespace)等等。
但是,并不是所有有“关系”的容器都属于同一个 Pod。
比如,PHP 应用容器和 MySQL 虽然会发生访问关系,但并没有必要、也不应该部署在同一台机器上,它们更适合做成两个 Pod。
另外, Pod 在 Kubernetes 项目里还有更重要的意义,那就是:容器设计模式。
为了理解这一层含义,我们需要先了解一下 Pod 的实现原理:
Pod,其实是一组共享了某些资源的容器
具体的说:Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。
如此看来, 通过docker run 的一些选项不就可以实现吗? 如:
# docker run --net=container:B --volumes-from=B --name=A image-A ...
但是,你有没有考虑过,如果真这样做的话,容器 B 就必须比容器 A 先启动,这样多个容器就不是对等关系,而是拓扑关系了。
所以,在 Kubernetes 项目里,Pod 的实现需要使用一个中间容器,这个容器叫作 Infra 容器。
Pod 中,Infra(pause) 容器一定是第一个被创建的容器,其他容器通过 Join Network Namespace 的方式,与 Infra 容器关联在一起
Infra 容器占用极少的资源,它使用的是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。(早期叫作/pod-infrastructure)
这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。
而在 Infra 容器“Hold 住”Network Namespace 后,用户容器就可以加入到 Infra 容器的 Network Namespace 当中了。所以,如果你查看这些容器在宿主机上的 Namespace 文件,它们指向的值一定是完全一样的。
因此,对于同一 Pod 里的容器 A 和容器 B 来说:
• 它们可以直接使用 localhost 进行通信;
• 它们看到的网络设备跟 Infra 容器看到的完全一样;
• 一个 Pod 只有一个 IP 地址,也就是这个 Pod 的 Network Namespace 对应的 IP 地址;
• 当然,其他的所有网络资源,都是一个 Pod 一份,并且被该 Pod 中的所有容器共享;
• Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
而对于同一个 Pod 里面的所有用户容器来说,它们的进出流量,也可以认为都是通过 Infra 容器完成的
如果你要开发一个网络插件时,应该重点考虑的是如何配置这个 Pod 的 Network Namespace,而不是每一个用户容器如何使用你的网络配置
有了这个设计之后,共享 Volume 就简单多了:Kubernetes 项目只要把所有 Volume 的定义都设计在 Pod 层级即可。
Pod 里的容器只要声明挂载这个 Volume,就一定可以共享这个 Volume 对应的宿主机目录。
如下面这个例子:
apiVersion: v1
kind: Pod
metadata:
name: two-containers
spec:
restartPolicy: Never
volumes:
- name: shared-data
hostPath:
path: /data
containers:
- name: nginx-container
image: nginx
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
- name: debian-container
image: debian
volumeMounts:
- name: shared-data
mountPath: /pod-data
command: ["/bin/sh"]
args: ["-c", "echo Hello from the debian container > /pod-data/index.html"]
在这个例子中,debian-container 和 nginx-container 都声明挂载了 shared-data 这个 Volume。
shared-data 是 hostPath 类型。它对应在宿主机上的目录是/data。这个目录,被同时绑定挂载进了上述两个容器当中。
因此,这里的nginx-container 可以从它的 /usr/share/nginx/html 目录中,读取到 debian-container 生成的 index.html 文件内容。
容器设计模式
明白了 Pod 的实现原理后,我们再来讨论“容器设计模式”:
当我们想在一个容器里跑多个功能并不相关的应用时,应该优先考虑它们是不是更应该被描述成一个 Pod 里的多个容器。
为了能够掌握这种思考方式,你就应该尽量尝试使用它来描述一些用单个容器难以解决的问题。
示例: 容器的日志收集
例如有一个应用,把日志文件记录到容器的 /var/log 目录中, 可以把 Pod 里的一个 Volume 挂载到应用容器的 /var/log 目录上
在这个 Pod 里同时运行一个 sidecar 容器,它也声明挂载同一个 Volume 到自己的 /var/log 目录上。
sidecar 容器只需要做一件事,就是不断地从自己的 /var/log 目录里读取日志文件,转发到 Elasticsearch 中存储起来。
这样,一个最基本的日志收集工作就完成了。
Pod 是 Kubernetes 项目与其他单容器项目相比最大的不同,也是一位容器技术初学者需要面对的第一个与常规认知不一致的知识点。
事实上,直到现在,仍有很多人把容器跟虚拟机相提并论,他们把容器当做性能更好的虚拟机,喜欢讨论如何把应用从虚拟机无缝地迁移到容器中。
但实际上,无论是从具体的实现原理,还是从使用方法、特性、功能等方面,容器与虚拟机几乎没有任何相似的地方;也不存在一种普遍的方法,能够把虚拟机里的应用无缝迁移到容器中。因为,容器的性能优势,必然伴随着相应缺陷,即:它不能像虚拟机那样,完全模拟本地物理机环境中的部署方法。
所以,这个“上云”工作的完成,最终还是要靠深入理解容器的本质,即:进程。
实际上,一个运行在虚拟机里的应用,哪怕再简单,也是被管理在 systemd 或者 supervisord 之下的一组进程,而不是一个进程。这跟本地物理机上应用的运行方式其实是一样的。这也是为什么,从物理机到虚拟机之间的应用迁移,往往并不困难。
可是对于容器来说,一个容器永远只能管理一个进程。更确切地说,一个容器,就是一个进程。这是容器技术的“天性”,不可能被修改。所以,将一个原本运行在虚拟机里的应用,“无缝迁移”到容器中的想法,实际上跟容器的本质是相悖的。
所以,我们现在可以这么理解 Pod 的本质:
Pod,实际上是在扮演传统基础设施里“虚拟机”的角色;而容器,则是这个虚拟机里运行的用户程序。
当你需要把一个运行在虚拟机里的应用迁移到 Docker 容器中时,一定要仔细分析到底有哪些进程(组件)运行在这个虚拟机里。
然后,你就可以把整个虚拟机想象成为一个 Pod,把这些进程分别做成容器镜像,把有顺序关系的容器,定义为 Init Container。
这才是更加合理的、松耦合的容器编排诀窍,也是从传统应用架构,到“微服务架构”最自然的过渡方式。
init container
在很多应用场景中,应用在启动之前都需要进行如下初始化操作,如:
- 等待其他关联组件正确运行(例如数据库或某个后台服务〉。
- 基于环境变量或配置模板生成配置文件。
- 从远程数据库获取本地所需配置,或者将自身注册到某个中央数据库中。
- 下载相关依赖包 , 或者对系统进行一些预配置操作。
Kubernetes v1.3 引入了 一个 Alpha 版本的新特性 init container (在 Kubemetes v1.5 时被更新为 Beta 版本),用于在启动应用容器( app container )之前启动一个或多个“初始化 ”容器,完成应用容器所需的预置条件,如图 所示。 Init container 与应用容器本质上是一样的 ,但它们是仅运行一次就结束的任务,并且必须在成功执行完成后,系统才能继续执行下一个容器。根据 Pod 的重启策略( Res tartPolicy ),当 init container 执行失败,在设置了 RestartPolicy=Never时, Pod 将会启动失败: 而设置 RestartPolicy=Always 时, Pod 将会被系统自动重启
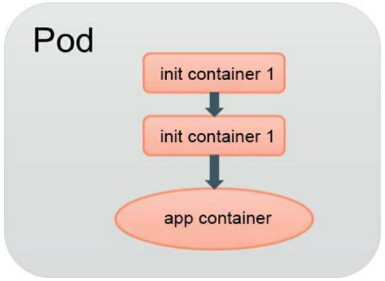
示例一: 要用Tomcat容器发布WAR包, 应该如何设计 ?
如果用单容器来解决, 我们很容易想到, 有以下两种方案:
- 方案一: 把 WAR 包直接放在 Tomcat 镜像的 webapps 目录下,做成一个新的镜像运行起来.
- 方案二: 只运行 Tomcat 的容器, 将WAR包放在宿主机目录中, 挂载到 Tomcat 容器中的webapp目录中去.
对于方案一, 如果要更新 WAR 包的内容,或者要升级 Tomcat 镜像,就要重新制作一个新的发布镜像,非常麻烦。
方案二也有个问题, 如何让每一台宿主机,都预先准备好这个存储有 WAR 包的目录呢? 只能再维护一套分布式存储系统或是共享存储了。
有了 Pod 之后,我们又有了第三种解决方案: 把 WAR 包和 Tomcat 分别做成镜像,然后把它们作为一个 Pod 里的两个容器组合在一起:
apiVersion: v1
kind: Pod
metadata:
name: javaweb
spec:
initContainers:
- image: registry.cn-shenzhen.aliyuncs.com/leedon/war-liuyanban
name: war
command: ["cp", "/liuyanban.war", "/app"]
volumeMounts:
- mountPath: /app
name: app-volume
containers:
- image: registry.cn-shenzhen.aliyuncs.com/leedon/tomcat7
name: tomcat
volumeMounts:
- mountPath: /opt/tomcat/webapps
name: app-volume
ports:
- containerPort: 8080
hostPort: 8001
volumes:
- name: app-volume
emptyDir: {}
访问目录:/liuyanban
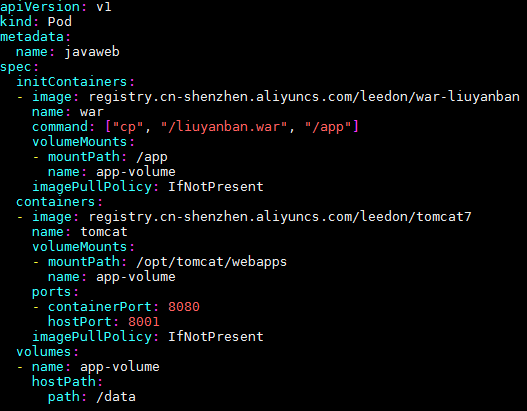
在这个 Pod 中,我们定义了两个容器:
第一个容器使用的镜像是 war-liuyanban,这个镜像里只有一个 WAR 包(liuyanban.war)放在根目录下。第二个容器使用的是一个标准的 Tomcat 镜像。
有一点你可能已经注意到: WAR 包容器是一个 Init Container 类型的容器。
在 Pod 中,所有 Init Container 定义的容器,都会比 spec.containers 定义的用户容器先启动。
并且,Init Container 容器会按顺序逐一启动,直到它们都启动并且退出了,用户容器才会启动。
例子中,这个 Init Container 类型的 WAR 包容器启动后,执行"cp /liuyanban.war /app",把应用的 WAR 包拷贝到 /app 目录下,然后退出。
这个 /app 目录,挂载了一个名叫 app-volume 的 Volume。
而Tomcat 容器,同样声明了挂载 app-volume 到自己的 webapps 目录下。
所以,等 Tomcat 容器启动时,它的 webapps 目录下就一定会存在 liuyanban.war 文件:这个文件正是 WAR 包容器启动时拷贝到这个 Volume 里面的,而这个 Volume 是被这两个容器共享的。
像这样,我们就用一种“组合”方式,解决了 WAR 包与 Tomcat 容器之间耦合关系的问题。
实际上,这个所谓的“组合”操作,正是容器设计模式里最常用的一种模式,它的名字叫:sidecar。
sidecar 是指在一个 Pod 中,启动一个辅助容器,来完成一些独立于主进程(主容器)之外的工作。
比如,在我们的这个应用 Pod 中,Tomcat 容器是我们要使用的主容器,而 WAR 包容器的存在,只是为了给它提供一个 WAR 包而已。
所以,我们用 Init Container 的方式优先运行 WAR 包容器,扮演了一个 sidecar 的角色。
Pod基本用法
静态Pod
Pod调度
在 Kubernetes 中, Pod 在大部分场景下只是容器的载体,通常需要通过Deployment、RC、Job 等对象来完成一组 Pod 的调度与自动控制功能。
最早的Kubernetes 版本里并没有那么多 Pod 副本控制器,只有一个 Pod 副本控制器 RC ,这个控制器时这样设计实现的:
RC 独立于所控制的 Pod ,并通过 Label 标签 这个松耦合关联关系 控制目标 Pod 实例的创建和销毁。
随后 RC 出现的新的继承者——Deployment 。用于更加自动的完成 Pod 副本的部署、版本更新、回滚等功能。
严谨来说, RC 的继任者其实并不是 Deployment, 而是 ReplicaSet,因为 ReplicaSet 进一步增强了RC 标签选择器的灵活性。
kubernetes的调度分为:
控制器自动调度:
- Deployment或RC —— 全自动调度,后面详细介绍
- DaemonSet —— 在每个Node上调度,后面详细介绍
手动调度:
- NodeName —— 定向调度,最简单的节点选择方式,直接指定节点,跳过调度器。
- NodeSelector —— 定向调度,早期的简单控制方式,直接通过键—值对将 Pod 调度到具有特定 label 的 Node 上。
- Taint/Toleration —— 污点和容忍,通过 Pod 有洁癖的特性进行调度
- NodeAffinity —— Node亲和性调度,NodeSelector 的升级版,支持更丰富的配置规则,使用更灵活。
- PodAffinity —— Pod亲和性调度,根据已在节点上运行的 Pod 标签来约束当前 Pod 可以调度到哪些节点,而不是根据 node label。
NodeName
nodeName 是 PodSpec 的一个字段,用于直接指定调度节点,并运行该 pod。
调度器在工作时,实际选择的是 nodeName 为空的 pod 并进行调度然后再回填该 nodeName,所以直接指定 nodeName 实际是直接跳过了调度器。
换句话说,指定 nodeName 的方式是优于其他节点选择方法。
方法很简单,直接来个官方示例

注意:如果选择的节点不存在,或者资源不足,那该 pod 会运行失败
NodeSelector
Kubernetes Master 上的 Scheduler 服务负责实现 Pod 的调度,整个调度过程通过执行一系列复杂的算法,最终为每个 Pod 计算出一个最佳的目标节点,这一过程是自动完成的,通常我们无法知道 Pod 最终会被调度到哪个节点上。
在实际情况中,也可能需要将 Pod 调度到指定的一些 Node 上,可以通过 Node 的标签( Label) 和 Pod 的 nodeSelector 属性相匹配,来达到上述目的。
(1) 通过 kubectl label 命令给目标 Node 打上一些标签
语法: kubectl label nodes =
例如,我们为 k8s-node-1 节点打上一个 zone=north 的标签, 表明它是“北方”的一个节点 :
# kubectl label nodes k8s-node-1 zone=north
(2) 在 Pod 的定义中加上 nodeSelector 的设置,以 redis-master-controIler. yaml 为例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
matchLabels:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
containers:
- name: master
image: daocloud.io/library/redis
ports:
- containerPort: 80
nodeSelector:
zone: north
运行 kubectl apply -f 命令创建 Pod , scheduler 就会将该 Pod 调度到拥有 zone=north 标签的Node 上 。
使用 kubectl get pods -o wide 命令可以验证 Pod 所在的 Node:
# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE node
redis-master-forqj 1/1 Running 0 19s k8s-node-1
Taint/Toleration
默认情况下 Master 节点是不允许运行用户 Pod 的,原因在于 Taint/Toleration 机制:
一旦某个节点被加上了一个 Taint,即被上了“污点”,那么所有 Pod 就都不能在这个节点上运行,因为 Pod 有"洁癖"。
Taint
查看master的Taint:
[root@master1 k8s-yaml]# kubectl describe node master # 可以看到 master 角色有这样一个 Taints

为node节点打Taints
语法:
kubectl taint nodes NODE_NAME KEY=VALUE:EFFECT
例如:
# kubectl taint nodes node1 foo=bar:NoSchedule
此时,node1 节点上就会增加一个键值对格式的 Tain:foo=bar:NoSchedule。
effect 的 NoSchedule,表示这个 Taint 只会在调度新 Pod 时产生作用,不影响已经在 node1 上运行的 Pod
effect的值有”NoSchedule“、”PreferNoSchedule“、”NoExecute“
实验一
以下实验每个步骤都是在空负载集群中操作
1)运行一个deployment,副本数量等于Node节点数量,观察Pod分布情况;
2)空负载的情况下给其中一个Node节点打上污点(每种效果都分别打一次),再重新运行上述deploy,观察Pod分布情况;
3)将deploy的副本数量增加1倍,重复实验2,观察有什么区别(重点观察”PreferNoSchedule“)
实验二
以下实验步骤的操作背景:所有节点无污点,集群运行着一个deployment,副本数量与节点数量相同
1)给其中一个节点加上污点,effect是NoSchedule,观察Pod变化情况;
2)给其中一个节点加上污点,effect是NoExecute,观察Pod变化情况。
自己动手做上面两个实验,总结出这三种effect的特点:
- NoSchedule:
- PreferNoSchedule:
- NoExecute:
删除污点:
kubectl taint nodes NODE_NAME KEY=VALUE:EFFECT- # effect级别的删除
kubectl taint nodes NODE_NAME KEY- # key级别的删除
在 KEY 后面加上了一个短横线"-",意味着移除所有以 KEY 为键的 Taint。
Toleration
是不是只要节点上有了污点, 就一定不能运行pod了呢? 不一定
如果 Pod 声明自己能容忍这个"污点",即声明了 Toleration,它就可以在这个节点上运行。
Pod 声明 Toleration
我们只要在 Pod 的.yaml 文件中的 spec 部分,加入 tolerations 字段即可:
apiVersion: v1
kind: Pod
...
spec:
tolerations:
- key: "foo"
operator: "Equal"
value: "bar"
effect: "NoSchedule"
...
这个 Toleration 的含义是,这个 Pod 能容忍所有键值对为 foo=bar,effect为 NoSchedule 的 Taint。
回到我们上面看到的master的Taint, 我们会发现这个污点只有键"node-role.kubernetes.io/master", 没有值
对于这样的污点我们要用 “Exists” 操作符:
apiVersion: v1
kind: Pod
...
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
...
toleration有如下特点:
- 空的 “key” 配合 “Exists” 能匹配所有的键和值;
- “operator” 的默认值为 “Equal”;
- 空的 “effect” 能匹配所有的 effect。
NodeAffinity
NodeAffinity 意为 Node 亲和性的调度策略,是用于替换 NodeSelector 的全新调度策略 。
Node affinity跟NodeSelector很像, 相对于NodeSelector主要有以下几个优点:
• 匹配有更多的逻辑组合,不只是字符串的完全相等
• 调度分成软策略(soft)和硬策略(hard),在软策略下,如果没有满足调度条件的节点,pod会忽略这条规则,继续完成调度。
nodeAffinity 属性:
requiredDuringSchedulingIgnoredDuringExecution: 调度时必须满足, 运行时如果节点标签不再满足指定的条件,pod仍继续运行
preferredDuringSchedulingIgnoredDuringExecution: 优选条件,如果没有满足条件的节点,就忽略这些条件
比如下面的例子中的 Pod 将调度到这样的节点上:
requiredDuringSchedulinglgnoredDuringExecution 要求只运行在 amd64或 arm64 的节 点上( kubernetes.io/arch In amd64 ) 。
preferredDuringSchedulinglgnoredDuringExecution 的要求是尽量运行在 “磁盘类 型为ssd”(disk-type In ssd )的节点上。

从上面的配置中可以看到 In 操作符, NodeAffinity 语法支持的操作符包括 In、NotIn、Exists、DoesNotExist 、Gt 、Lt 。
虽然没有节点排斥的功能, 但是用 NotIn 和 DoesNotExist 就可以实现排斥 的 功能了。
NodeAffinity 规则设置的注意事项如下。
- 如果同时定义了 nodeSelector 和 nodeAffinity ,那么必须两个条件都得到满足, Pod 才能最终运行在指定的 Node 上。
- 如果 nodeSelectorTerms 中有多个 matchExpressions , 那么只需要其中一个能够匹配成功即可 。
- 如果 matchExpressions 中有多个 key , 则一个节点必须满足所有 key 才能运行该 Pod 。
硬策略适用于 pod 必须运行在某种节点,否则会出现问题的情况,比如集群中节点的架构不同,而运行的服务必须依赖某种架构提供的功能;
软策略适用于满不满足条件都能工作,但是满足条件更好的情况,比如服务最好运行在某个区域,减少网络传输等。
这种区分是按用户的具体需求决定的,并没有绝对的技术依赖。
PodAffinity
nodeSelector & nodeAffinity 都是基于 node label 进行调度。
有时候我们希望调度的时候能考虑 pod 之间的关系,而不只是 pod 和 node 的关系。
举个例子,希望服务 A 和 B 部署在同一个机房、机架或机器上,因为这些服务可能会对网路延迟比较敏感,需要低延时;
再如,希望服务 C 和 D 尽量分开部署,即使一台主机甚至一个机房出了问题,也不会导致两个服务一起挂而影响服务可用性,提升故障容灾的能力。
podAffinity 会基于节点上已经运行的 pod label 来约束新 pod 的调度。
其规则就是“如果 X 已经运行了一个或者多个符合规则 Y 的 Pod,那么这个 Pod 应该(如果是反亲和性,则是不应该)调度到 X 上”。
这里提到的 X 是指一个拓扑域, 类似于 node、rack、zone、cloud region 等等,是指 k8s 内置 Node 标签 ,当然也可以自定义。
内置 Node 标签
Kubernetes 内置了一些节点标签:
• kubernetes.io/hostname
• beta.kubernetes.io/instance-type
• beta.kubernetes.io/os
• beta.kubernetes.io/arch
• failure-domain.beta.kubernetes.io/zone
• failure-domain.beta.kubernetes.io/region
有些标签是对云提供商使用。
还有些表示 node role 的 labels(可以指定 master、lb 等):
• kubernetes.io/role
• node-role.kubernetes.io
podAffinity 属性:
podAffinity: 亲和性, 将 Pod 调度到有运行着的满足条件的 Pod 所在的 拓扑域
podAntiAffinity: 反亲和性, 不要将 Pod 调度到有运行着的满足条件的 Pod 所在的 拓扑域
requiredDuringSchedulingIgnoredDuringExecution: 功能类似于 nodeAffinity
preferredDuringSchedulingIgnoredDuringExecution: 功能类似于 nodeAffinity
例如: 下面的 Pod 会调度到这样的节点上:
• 与 security=S1 的 Pod 为同一个 zone
• 不与 app=nginx 的 Pod 为同一个 Node
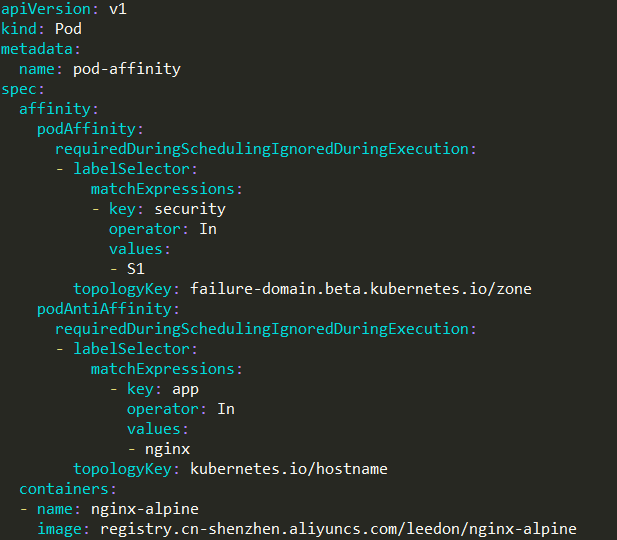
与节点亲和性类似, Pod 亲和性的操作符也包括 In、NotIn 、Exists 、DoesNotExist 、Gt 、Lt 。
PodAffinity 规则设置的注意事项如下 。
- 除了设置 Label Selector 和 topologyKey ,用户还可 以指定 namespace 列表来进行限制,同样,使用 Label Selector 对 namespace 进行选择。 namespace 的定义和 Label Selector 及 topologyKey 同级。省略 namespace 的设置,表示使用定义了 affnity/anti-affinity 的Pod 所在的 namespace 。如果 namespace 设置为空值,则表示所有 namespace 。
- 在所有关联 requiredDuringSchedulinglgnoredDuringExecution 的 matchExpressions 全都满足之后,系统才能将 Pod 调度到某个 Node 上。
更多关于 Pod 亲和性和互斥性调度的信息可参考文档:https://github.com/kubemetes/kubemetes/blob/master/docs/design/podaffinity.md
TopologyKey
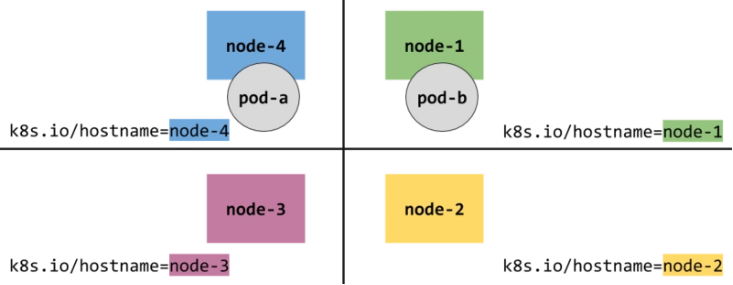
TopologyKey 用于定义 “in the same place”,就是同一拓扑域. 例如:
-
如果我们使用k8s.io/hostname,则意味着同一个 node,那下图的 pod-a 和 pod-b 就不在一个 place:
-
如果我们使用failure-domain.k8s.io/zone ,那下图的 pod-a 和 pod-b 就表示在一个 zone
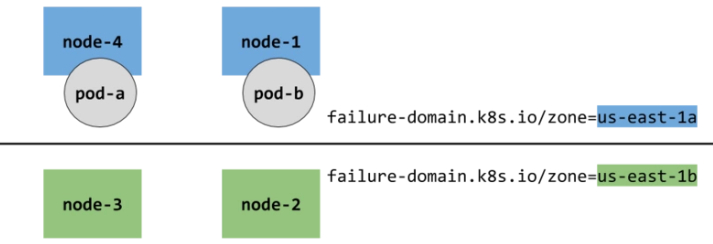
-
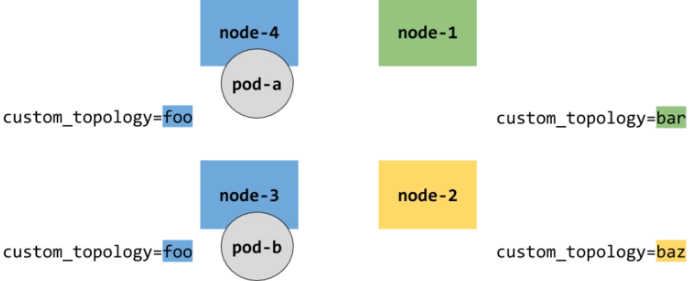
如果我们自定义 node labels 作为 TopologyKey,那下图的 pod-a 和 pod-b 表示在同一个 place
原则上, topologyKey 可以使用任何合法的标签 Key 赋值,但是出于性能和安全方面的考虑,对 topologyKey 有如下限制:
• 对于亲和性和反亲和性的 requiredDuringSchedulingIgnoredDuringExecution 模式,topologyKey 不能为空
• pod 反亲和性 requiredDuringSchedulingIgnoredDuringExecution 模式下,LimitPodHardAntiAffinityTopology 权限控制器会限制 topologyKey 只能设置为 kubernetes.io/hostname。当然如果你想要使用自定义 topology,那可以简单禁用即可。
• pod 反亲和性 preferredDuringSchedulingIgnoredDuringExecution 模式下,topologyKey 为空则表示所有的拓扑域。截止 v1.12 版本,所有的拓扑域还只能是 kubernetes.io/hostname, failure-domain.beta.kubernetes.io/zone 和 failure-domain.beta.kubernetes.io/region 的组合。
如果不是上述情况,就可以采用任意合法的 topologyKey了 。
Pod健康检查机制
在 Kubernetes 中,你可以为 Pod 里的容器定义一个健康检查“探针”(Probe)。
这样,kubelet 就会根据这个 Probe 的返回值决定这个容器的状态,而不是直接以容器进行是否运行(来自 Docker 返回的信息)作为依据。
这种机制,是生产环境中保证应用健康存活的重要手段。
对 Pod 的健康状态检查可以通过两类探针来检查: LivenessProbe 和 ReadinessProbe 。kubelet 定期执行这两种探针来诊断容器的健康状况 。
-
LivenessProbe :用于判断容器是否存活( running 状态),如果 LivenessProbe 探针探测到容器不健康,则 kubelet 将杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含 LivenessProbe 探针,那么 kubelet 认为该容器的 LivenessProbe 探针返回的值永远是“ Success"
-
ReadinessProbe:用于判断容器是否启动完成( ready 状态),可以接收请求。如果 ReadinessProbe 探针检测到失败,则 Pod 的状态将被修改。 系统将从Service 的 Endpoint 中删除包含该容器所在 Pod 的 Endpoint 。 这样就能保证客户端在访问 Service时 在访问 Service 时不会被转发到服务不可用的Pod实例上
LivenessProbe 和 ReadinessProbe 均可配置以下三种实现方式
- ExecAction :在容器内部执行一个命令 ,如果该命令的返回码为 0 ,则表明容器健康 。
在下面的例子中,通过执行“ test -f /tmp/healthy ”命令来判断一个容器运行是否正常。而该Pod 运行之后,在创建/tmp/healthy 文件的 30s 之后将删除该文件,而 LivenessProbe 健康检查的初始探测时间( initialDelaySeconds )为 15s ,探测结果将是 Fail ,将导致 kubelet 杀掉该容器井重启它。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-test
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command: # 执行LivenessProbe的命令,返回值为0,则说明容器是健康的
- test
- -f
- /tmp/healthy
initialDelaySeconds: 15 # 容器启动 15s后开始执行
periodSeconds: 5 # 每 5s执行一次
在这个文件中, 我们定义了容器启动之后在 /tmp 目录下创建一个healthy 文件, 以此作为自己已经正常运行的标志, 30s 后它会把这个文件删除掉。
我们启动这个Pod

[root@master1 k8s-yaml]# kubectl apply -f liveness-test.yaml
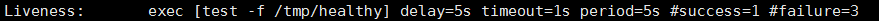
[root@master1 k8s-yaml]# kubectl describe po liveness-test
…
#可以看到在pod的描述中已经有了Liveness
过30s后,再describe, 可以看到在Events里面会有Warning,这是因为探针执行的命令返回值变成了非0

再看pod状态,还是running, 但是restart的值却变成了1, 原来kubernetes已经重建了容器

这种发现异常自动重建的功能就是 Kubernetes 里的Pod 恢复机制,也叫 restartPolicy。
它是 Pod 的 Spec 部分的一个标准字段(pod.spec.restartPolicy),默认值是 Always,即:任何时候这个容器发生了异常,它一定会被重新创建。
有一点需要注意的是Pod 的恢复过程,永远都是发生在当前节点上,而不会跑到别的节点上去。
如果你希望 Pod 可以被调度到其他的可用节点上,就必须使用 Deployment 这样的“控制器”来管理 Pod,哪怕你只需要一个 Pod 副本。
注意:Kubernetes 中并没有 Docker 的 Stop 语义。所以虽然是 Restart(重启),但实际却是重新创建了容器。
- TCPSocketAction :通过容器的 IP 地址和端口号执行 TCP 检查,如果能够建立 TCP 连接,则表明容器健康。
在下面的例子中,通过与容器内的 localhost:80 建立 TCP 连接进行健康检查。
apiVersion: v1
kind: Pod
metadata:
name: pod-with-healthcheck
spec:
containers:
- name: nginx
image: daocloud.io/library/nginx
ports:
- containerPort: 80
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 30
timeoutSeconds: 1
- HTTPGetAction : 通过容器的 IP 地址、端口号及路径调用 HTTP Get 方法,如果响应的状态码大于等于 200 且小于 400,则认为容器状态健康。在下面的例子中, kubelet 定时发送 HTTP 请求到 localhost:80/_status/healthz 来进行容器应用的健康检查。
apiVersion: v1
kind: Pod
metadata:
name: pod-with-healthcheck
namespace: default
spec:
containers:
- name: pod-with-healthcheck
image: daocloud.io/library/nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
livenessProbe:
httpGet:
port: 80
path: /_status/healthz
initialDelaySeconds: 30
periodSeconds: 3
Pod生命周期
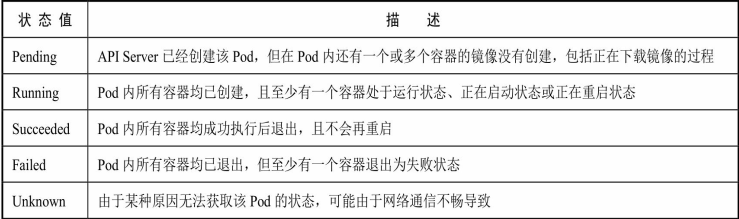
Pod 在整个生命周期过程中被系统定义为各种状态,熟悉 Pod 的各种状态对于我们理解如何设置 Pod 的调度策略、重启策略是很有必要的。
Pod 状态如表所示:
Pod 的重启策略( RestartPolicy )应用于 Pod 内的所有容器,并且仅在 Pod 所处的 Node 上由 kubelet 进行判断和重启操作。
当某个容器异常退出或者健康检查失败时, kubelet 将根据 RestartPolicy 的设置来进行相应的操作 。
Pod 的重启策略包括 Always 、 OnFailure 和 Never , 默认值为 Always 。
- Always : 当容器失效时,由 kubelet 自动重启该容器。
- OnFailure : 当容器终止运行且退出码不为 0 时,由 kubelet 自动重启该容器。
- Never :不论容器运行状态如何, kubelet 都不会重启该容器。
在实际使用时,我们需要根据应用运行的特性,合理设置这三种重启策略。
比如
1)一个 Pod 只需要完成某个任务后退出,变成 Succeeded 状态。此时如果用 restartPolicy=Always 强制重启这个 Pod 的容器没有任何意义。
2)如果关心容器退出后的环境,比如日志、文件等,就需要将 restartPolicy 设置为 Never。因为一旦容器被自动重新创建,这些内容就有可能丢失掉了(被垃圾回收了)。
restartPolicy 和 Pod 里容器的状态对应关系:
- 只要 Pod 的 restartPolicy 指定的策略是Always,那么这个Pod 就会保持 Running 状态,并进行容器重启。
- 对于包含多个容器的 Pod,只有它里面所有的容器都进入异常状态后,Pod 才会进入 Failed 状态。
kubelet 重启失效容器的时间间隔以 sync-frequency 乘以 2n 来计算;例如 1、 2 、 4 、 8 倍等,最长延时 5min ,并且在成功重启后的 10min 后重置该时间。
Pod 的 重启策略与控制方式息息相关,当前可用于管理 Pod 的控制器包括RC 、 Job 、 DaemonSet 及直接通过 kubelet 管理(静态 Pod ) 。
每种控制器对 Pod的重启策略要求如下:
- RC 和 DaemonSet :必须设置为 Always ,需要保证该容器持续运行。
- Job: OnFailure 或 Never ,确保容器执行完成后不再重启。
- kubelet : 在 Pod 失效时自动重启它,不论将 RestartPolicy 设置为什么值,也不会对 Pod进行健康检查。
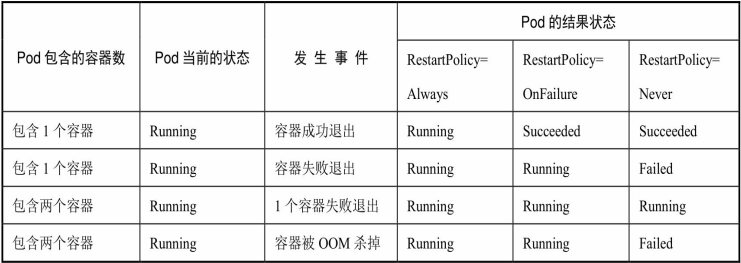
结合 Pod 的状态和重启策略,下表列出一些常见的状态转换场景。
PodHook
我们知道Pod是Kubernetes集群中的最小单元,而 Pod 是由容器组成的,所以在讨论 Pod 的生命周期的时候我们可以先来讨论下容器的生命周期。
实际上 Kubernetes 为我们的容器提供了生命周期钩子的,就是我们说的Pod Hook,Pod Hook 是由 kubelet 发起的,当容器中的进程启动前或者容器中的进程终止之前运行,这是包含在容器的生命周期之中。我们可以同时为 Pod 中的所有容器都配置 hook。
Kubernetes 为我们提供了两种钩子函数:
PostStart:这个钩子在容器创建后立即执行。但是,并不能保证钩子将在容器ENTRYPOINT之前运行,因为没有参数传递给处理程序。主要用于资源部署、环境准备等。不过需要注意的是如果钩子花费太长时间以至于不能运行或者挂起, 容器将不能达到running状态。
PreStop:这个钩子在容器终止之前立即被调用。它是阻塞的,意味着它是同步的, 所以它必须在删除容器的调用发出之前完成。主要用于优雅关闭应用程序、通知其他系统等。如果钩子在执行期间挂起, Pod阶段将停留在running状态并且永不会达到failed状态。
如果PostStart或者PreStop钩子失败, 它会杀死容器。所以我们应该让钩子函数尽可能的轻量。
当然有些情况下,长时间运行命令是合理的, 比如在停止容器之前预先保存状态。
示例1 环境准备
以下示例中,定义了一个Nginx Pod,其中设置了PostStart,即在容器创建成功后,写入一句话到/usr/share/nginx/html/index.html文件中。
apiVersion: v1
kind: Pod
metadata:
name: hook-demo1
spec:
containers:
- name: hook-demo1
image: registry.cn-shenzhen.aliyuncs.com/leedon/nginx-alpine
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/nginx/html/index.html"]
示例2 优雅删除资源对象
当用户请求删除含有 pod 的资源对象时,为了让应用程序优雅关闭(即让应用程序完成正在处理的请求后,再关闭软件),K8S提供两种信息通知:
- K8S 通知 node 执行docker stop命令,docker 会先向容器中PID为1的进程发送系统信号SIGTERM,然后等待容器中的应用程序终止执行,如果等待时间达到设定的超时时间,或者默认超时时间(30s),会继续发送SIGKILL的系统信号强行 kill 掉进程。
- 使用 pod 生命周期(利用PreStop回调函数),它执行在发送终止信号之前。
以下示例中,定义了一个Nginx Pod,其中设置了PreStop钩子函数,即在容器退出之前,优雅的关闭 Nginx:
apiVersion: v1
kind: Pod
metadata:
name: hook-demo2
spec:
containers:
- name: hook-demo2
image: nginx
lifecycle:
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
上面的例子可能看不到什么效果,我们将其改写一下:
apiVersion: v1
kind: Pod
metadata:
name: hook-demo2
labels:
app: hook
spec:
containers:
- name: hook-demo2
image: registry.cn-shenzhen.aliyuncs.com/leedon/nginx-alpine
ports:
- name: webport
containerPort: 80
volumeMounts:
- name: message
mountPath: /usr/share/
lifecycle:
preStop:
exec:
command: ['/bin/sh', '-c', 'echo Hello from the preStop Handler > /usr/share/message']
volumes:
- name: message
hostPath:
path: /tmp/test
Reference
1.《深入剖析Kubernetes 》张磊,容器编排和Kubernetes作业管理
- Kubernetes官方文档















 1186
1186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









