






我的使用系统环境是:ubuntu18.04,
gpu配置情况如下:
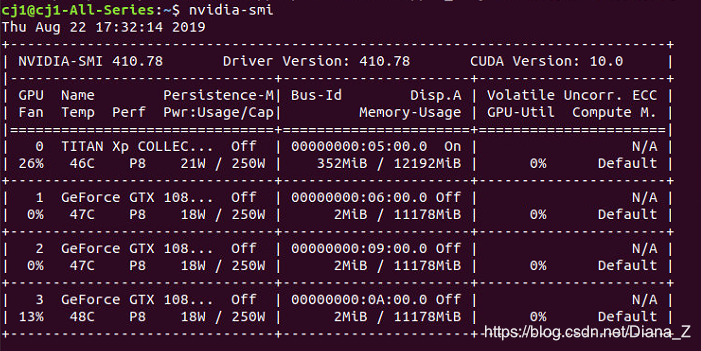
在pycharm中运行深度学习网络的时候,默认调用四个gpu,但是有时候,网络运行实际上用不到这么多算例,就可以限定使用的gpu,然后在其他的gpu上运行其他的网络。
使用torch和paddlepaddlle的调用gpu的网络模型,我都用这个方法实现了gpu控制。
需要注明的是,同一个工程中有多个需要调用gpu的组件的时候,每个组件调用一个gpu好像并不能通过该方式 实现 。该方式仅用于将某个工程的所有组件放置到限定的gpu上面运行,
以上一条出于自己的实验所得,可能并不完全和准确,仅供参考。
使用只需要添加如下两行代码:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"其中数字具体对应gpu序号,在我这里就是0,1,2,3四个gpu














 5784
5784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









