










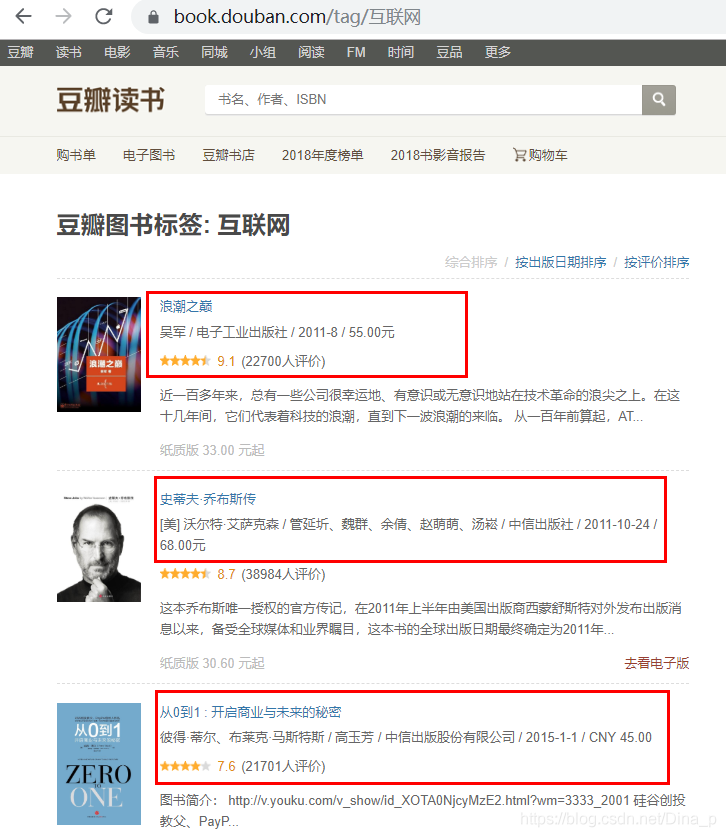
一、在豆瓣网爬取以下图书的信息:
二、参考代码:
1、连接 MongoDB 数据库,并且创建数据库和表
import pymongo
myclient = pymongo.MongoClient("mongodb://127.0.0.1:27017/")
db = myclient['webCrawler'] # 创建数据库 webCrawler
datatable = db['Book_info'] # 创建 Book_info 表2、爬取数据并且 存储到数据库
import re
import pandas as pd
import requests
from bs4 import BeautifulSoup
dataSet = [] # 用来存储 爬取下来的书籍信息
# 爬取 前五页 的数据
for i in range(5):
u = 'https://book.douban.com/tag/%E4%BA%92%E8%81%94%E7%BD%91?start='+str(i*20)+'&type=T'
txt = requests.get(url = u)
soup = BeautifulSoup(txt.text,'lxml') # 解析网址:使用 BeautifulSoup解析网址内容
lis = soup.find('ul',class_="subject-list").find_all('li') # 查找所有 ul 的class 为"subject-list"下的 所有 li 标签
for li in lis:
book_dict = {} # 用来存储 每本书的信息
book_dict['书名'] = li.h2.text.replace(' ','').replace('\n','')
book_dict['其他信息'] = li.find('div',class_="pub").text.replace(' ','').replace('\n','')
book_dict['评分'] = li.find('span',class_='rating_nums').text
book_dict['评价人数'] = re.search(r'(\d*)人',li.find('span',class_='pl').text.replace(' ','').replace('\n','')).group(1)
datatable.insert_one(book_dict) # 插入 图书信息到数据库中
dataSet.append(book_dict) # 把每本书的信息 添加到列表中
dataSetdf = pd.DataFrame(dataSet) # 将 list 类型的数据转换成 DataFrame 类型三、可在数据库里查看爬取下来的信息:














 3212
3212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









