









Hive概述
数据仓库的概念

传统数据仓库面临的挑战
• ( 1)无法满足快速增长的海量数据存储需求
• ( 2)无法有效处理不同类型的数据
• ( 3) 计算和处理能力不足
数据库和数据仓库的区别
数据库:传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
数据仓库:数据仓库系统的主要应用主要是OLAP(On-Line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
举个最常见的例子,拿电商行业来说好了。基本每家电商公司都会经历,从只需要业务数据库到要数据仓库的阶段。电商早期启动非常容易,入行门槛低。找个外包团队,做了一个可以下单的网页前端 + 几台服务器 + 一个MySQL,就能开门迎客了。这好比手工作坊时期。第二阶段,流量来了,客户和订单都多起来了,普通查询已经有压力了,这个时候就需要升级架构变成多台服务器和多个业务数据库(量大+分库分表),这个阶段的业务数字和指标还可以勉强从业务数据库里查询。初步进入工业化。第三个阶段,一般需要 3-5 年左右的时间,随着业务指数级的增长,数据量的会陡增,公司角色也开始多了起来,开始有了 CEO、CMO、CIO,大家需要面临的问题越来越复杂,越来越深入。高管们关心的问题,从最初非常粗放的:“昨天的收入是多少”、“上个月的 PV、UV 是多少”,逐渐演化到非常精细化和具体的用户的集群分析,特定用户在某种使用场景中,例如“20~30岁女性用户在过去五年的第一季度化妆品类商品的购买行为与公司进行的促销活动方案之间的关系”。这类非常具体,且能够对公司决策起到关键性作用的问题,基本很难从业务数据库从调取出来。原因在于:业务数据库中的数据结构是为了完成交易而设计的,不是为了而查询和分析的便利设计的。业务数据库大多是读写优化的,即又要读(查看商品信息),也要写(产生订单,完成支付)。因此对于大量数据的读(查询指标,一般是复杂的只读类型查询)是支持不足的。而怎么解决这个问题,此时我们就需要建立一个数据仓库了,公司也算开始进入信息化阶段了。数据仓库的作用在于:数据结构为了分析和查询的便利;只读优化的数据库,即不需要它写入速度多么快,只要做大量数据的复杂查询的速度足够快就行了。那么在这里前一种业务数据库(读写都优化)的是业务性数据库,后一种是分析性数据库,即数据仓库。最后总结一下:数据库 比较流行的有:MySQL, Oracle, SqlServer等数据仓库 比较流行的有:AWS Redshift, Greenplum, Hive等这样把数据从业务性的数据库中提取、加工、导入分析性的数据库就是传统的 ETL 工作。现在也有一些新的方法,这展开说又是另一件事情了,有机会再详细说说
Hive简介
•Hive是一个构建于Hadoop顶层的数据仓库工具
•支持大规模数据存储、分析,具有良好的可扩展性
•某种程度上可以看作是用户编程接口,本身不存储和处理数据
•依赖分布式文件系统HDFS存储数据
•依赖分布式并行计算模型MapReduce处理数据
•定义了简单的类似SQL的查询语言——HiveQL
•用户可以通过编写的HiveQL语句运行MapReduce任务
•可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上
•是一个可以提供有效、合理、直观组织和使用数据的分析工具
Hive具有的特点非常适用于数据仓库
•采用批处理方式处理海量数据
•Hive需要把HiveQL语句转换成MapReduce任务进行运行
•数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化
•提供适合数据仓库操作的工具
•Hive本身提供了一系列对数据进行提取、转换、加载( ETL)的工具,可以存储、查询和分析存储在Hadoop中的大规模数据
•这些工具能够很好地满足数据仓库各种应用场景
Hive与Hadoop生态系统中其他组件的关系

Hive与传统数据库的对比分析
• Hive在很多方面和传统的关系数据库类似,但是它的底层依赖的是HDFS和MapReduce,所以在很多方面又有别于传统数据库
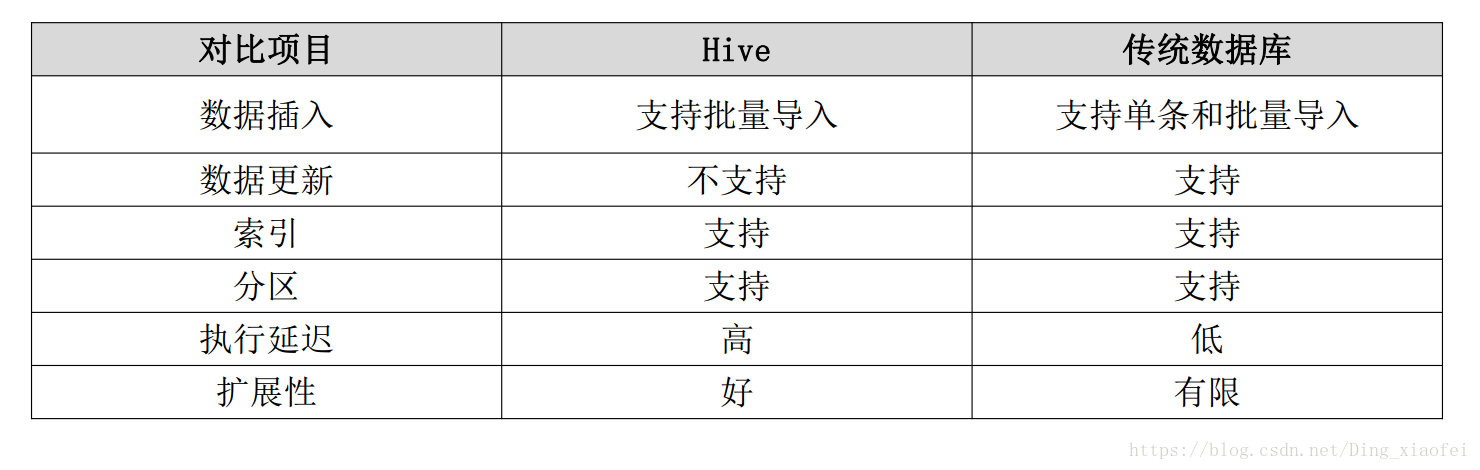
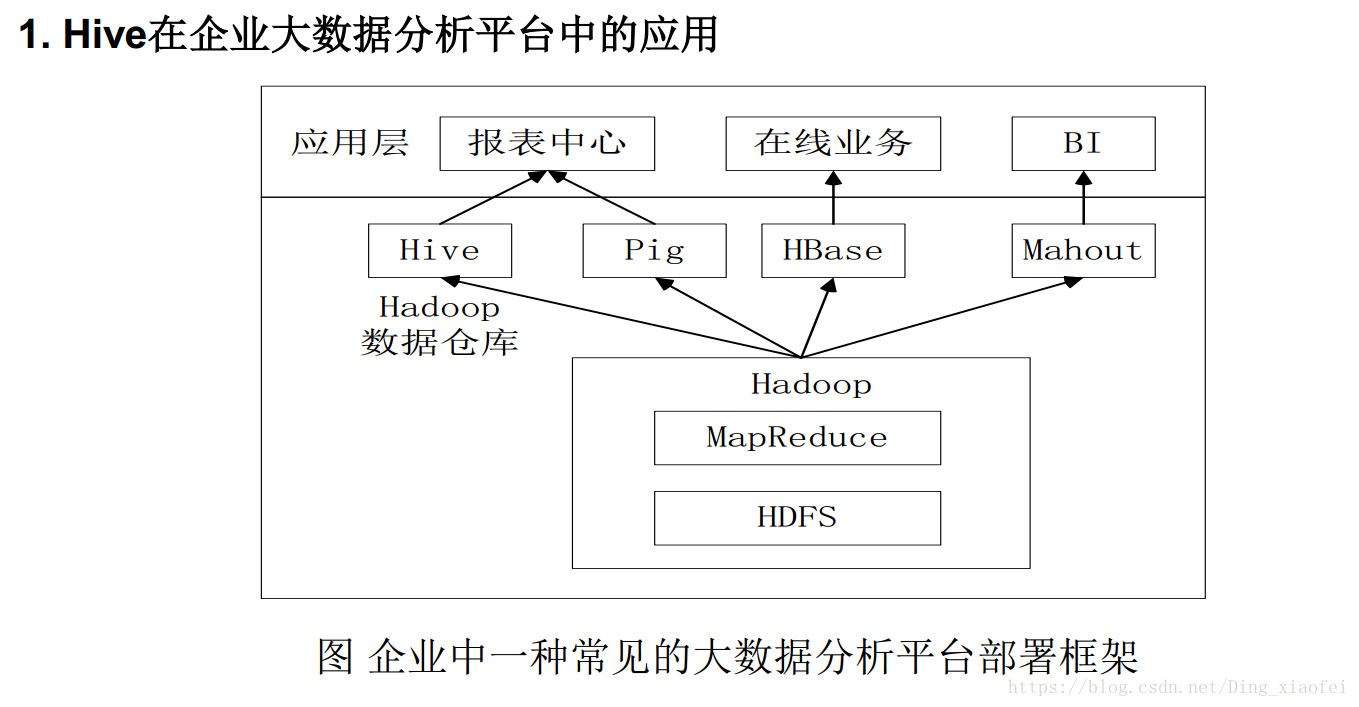
Hive在企业中的部署应用
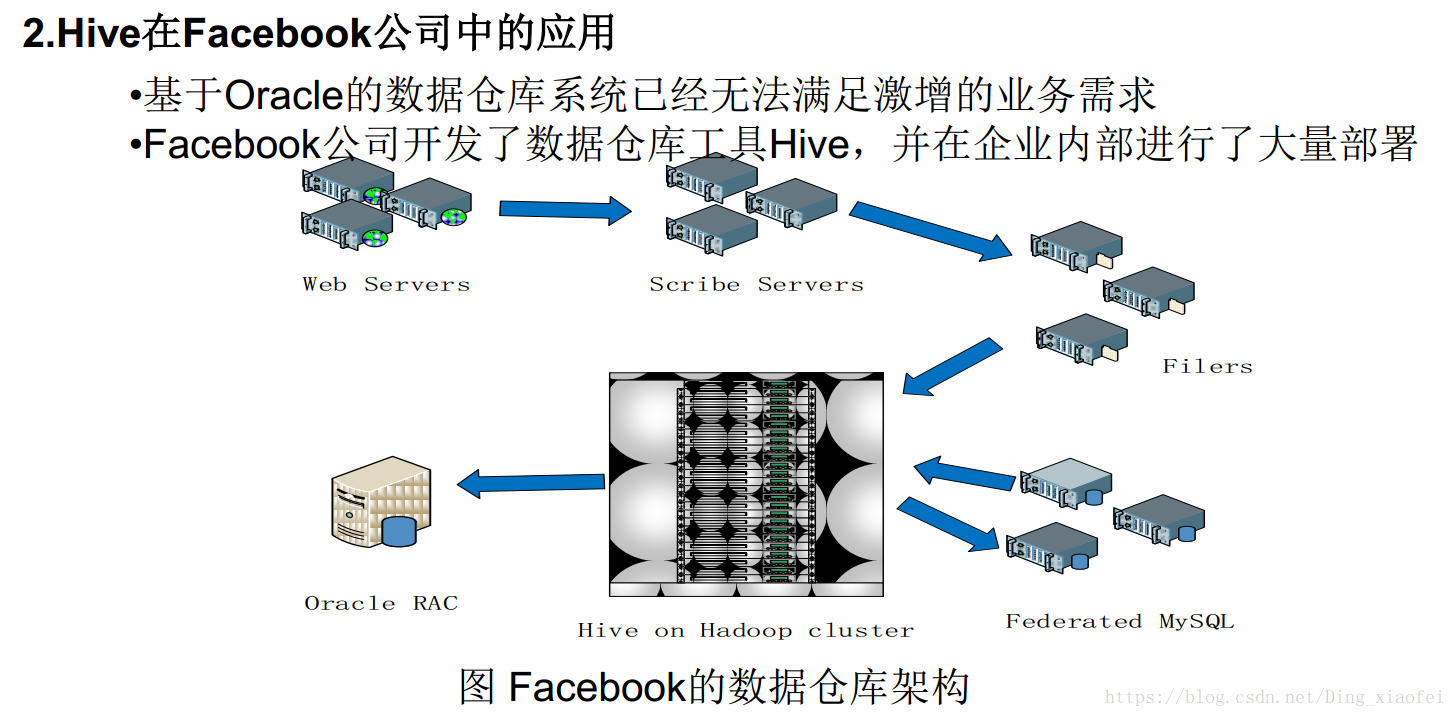
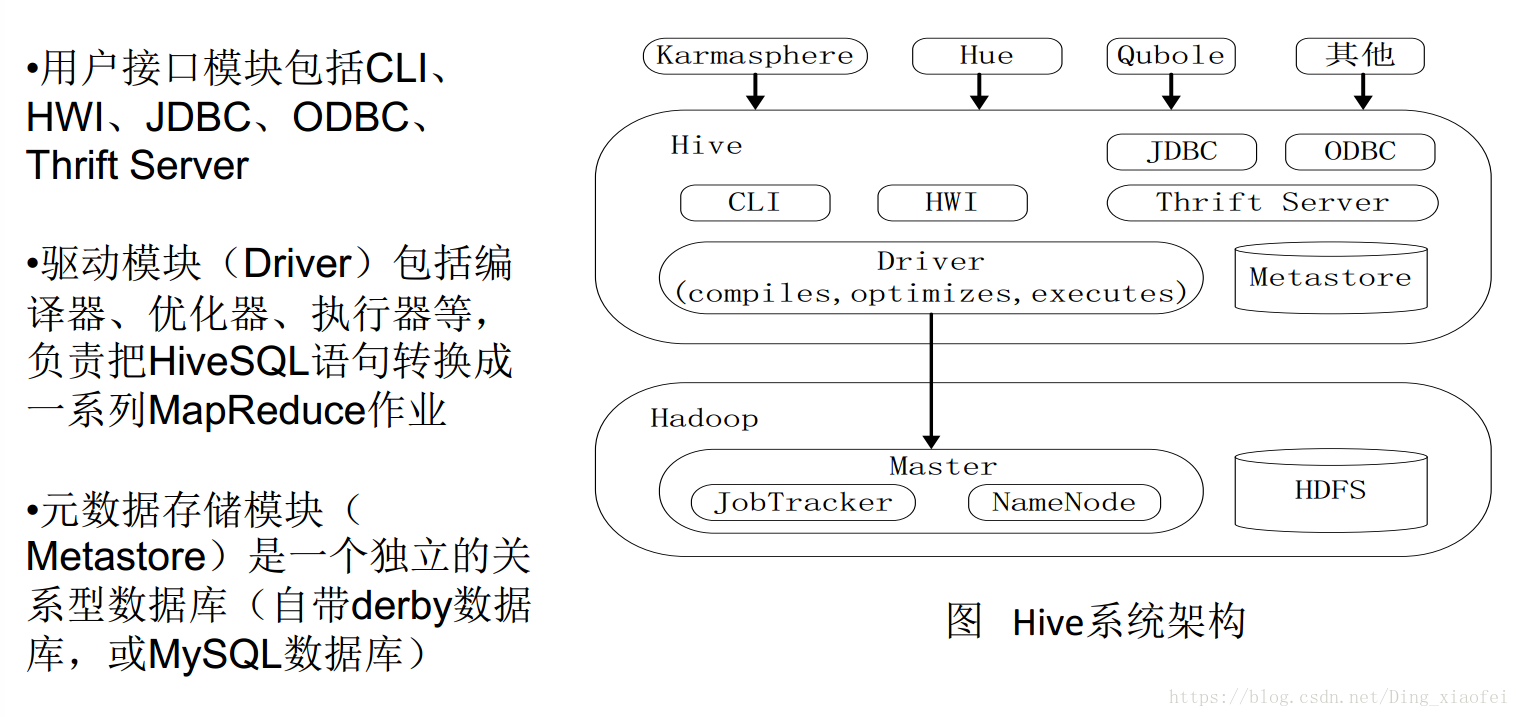
Hive系统架构
Hive工作原理
SQL语句转换成MapReduce的基本原理
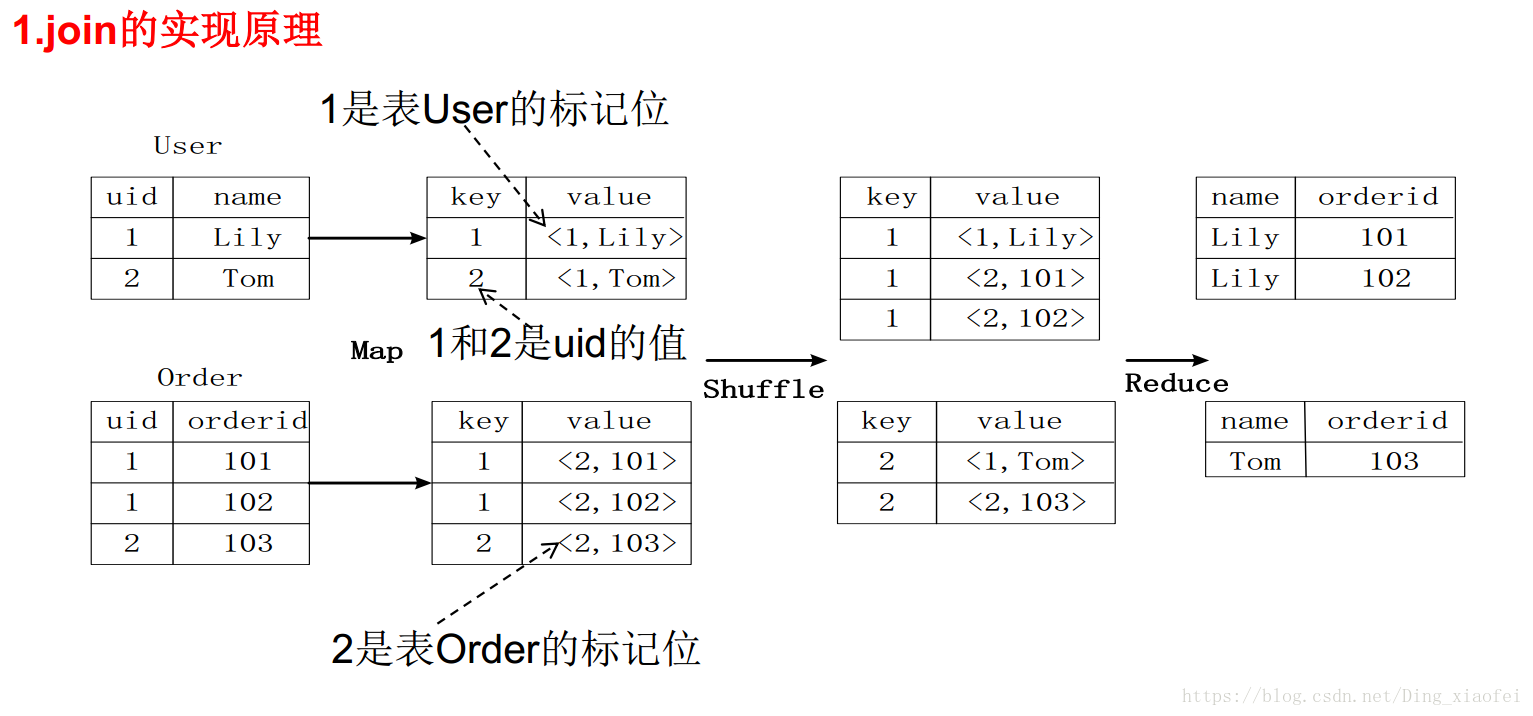
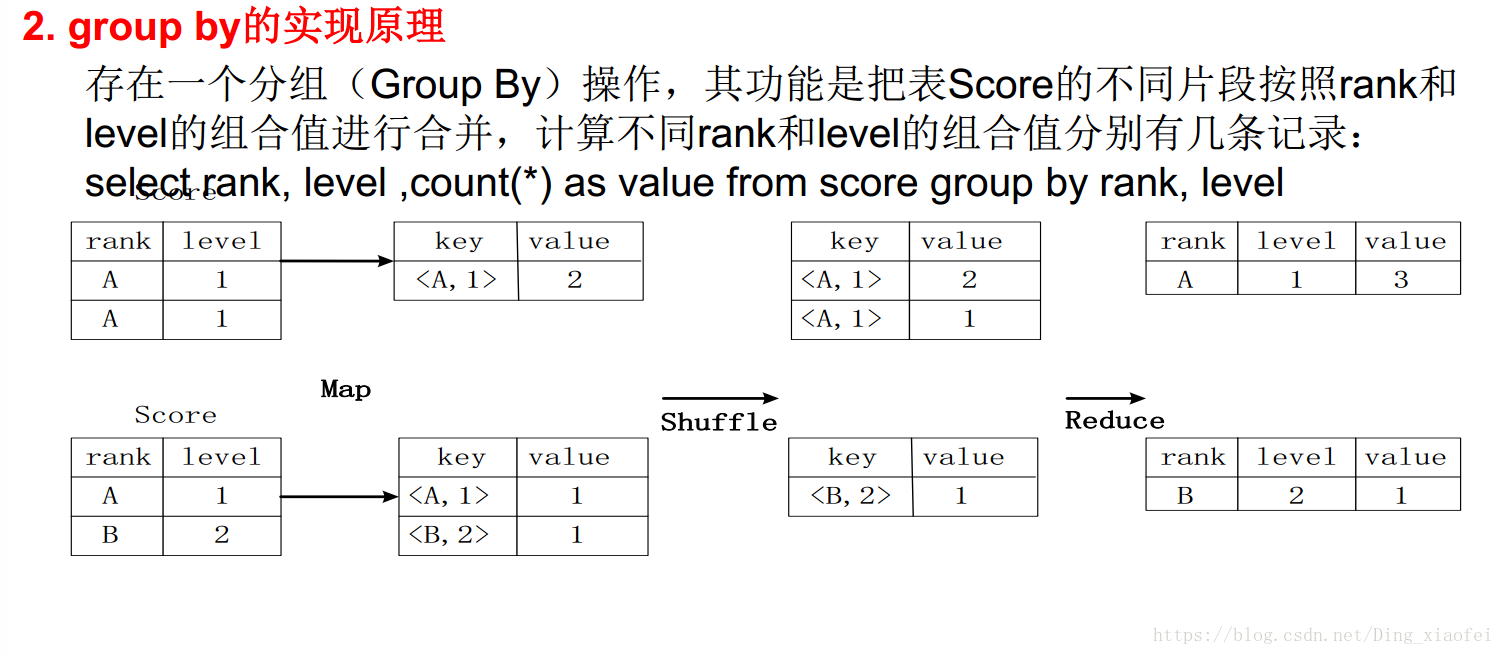
Hive中SQL查询转换成MapReduce作业的过程
•当用户向Hive输入一段命令或查询时, Hive需要与Hadoop交互工作来完成该操作:
驱动模块接收该命令或查询编译器
对该命令或查询进行解析编译
由优化器对该命令或查询进行优化计算
该命令或查询通过执行器进行执行

几点说明
• 当启动MapReduce程序时, Hive本身是不会生成MapReduce算法程序的
• 需要通过一个表示“ Job执行计划”的XML文件驱动执行内置的、原生的Mapper和Reducer模块
• Hive通过和JobTracker通信来初始化MapReduce任务,不必直接部署在JobTracker所在的管理节点上执行
• 通常在大型集群上,会有专门的网关机来部署Hive工具。网关机的作用主要是远程操作和管理节点上的JobTracker通信来执行任务
• 数据文件通常存储在HDFS上, HDFS由名称节点管理















 2530
2530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









