




python中一些常见的环境配置错误
目录
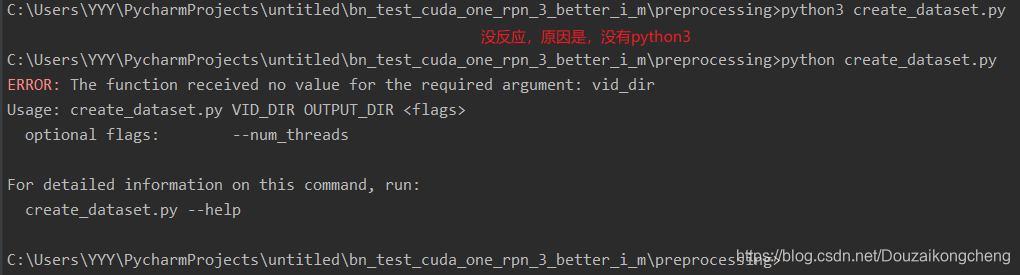
2.pycharm的 terminal中输入python3没反应
3.lmdb.Error: C:/Users/YYY/Desktop/data/VID_2015_RPN++.lmdb/: ���̿ռ䲻�㡣
10.控制多GPU训练,nn.DataParallel必须使用0号GPU作为主要的GPU,采用单进程多GPU
11.ModuleNotFoundError: No module named 'CommandNotFound'
14.RuntimeError: unexpected EOF, expected 743251 more bytes. The file might be corrupted.
21.RuntimeError: view size is not compatible with input tensor's size and stride
24.graphviz.backend.ExecutableNotFound: failed to execute ['dot', '-Tpdf', '-O', 'Digraph.gv']问题解决
1.pip install没反应
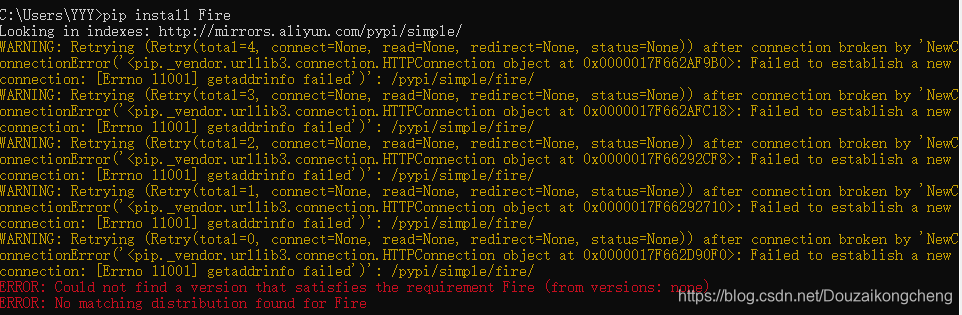
原因:1.没网,2.或者集群连不上外网,只能通过源码安装
2.pycharm的 terminal中输入python3没反应
3.lmdb.Error: C:/Users/YYY/Desktop/data/VID_2015_RPN++.lmdb/: ���̿ռ䲻�㡣
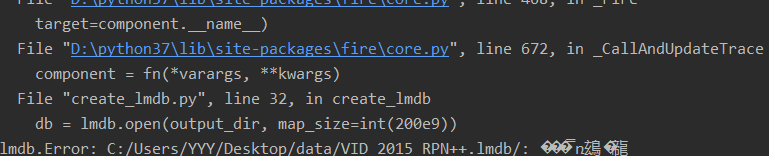
报错是因为map_size开的太大,超出了硬盘的可用大小(109951162776b=1tb)改小即可。
db = lmdb.open(output_dir, map_size=int(200e7))
4.RuntimeError: cuda runtime error (100) : no CUDA-capable device is detected at ..\aten\src\THC\THCGeneral.cpp:50
原因:电脑只有一块显卡,默认编号为0
解决办法
--gpu 0
os.environ["CUDA_VISIBLE_DEVICES"] = ‘0’
5.注册nvidia账号
There is a problem with your account. Please contact the site's administrator.
关闭页面重新进入就可以登陆了
之前在自己的笔记本电脑上注册nvidia的账号一直不成功
换了实验室的台式电脑就可以注册nvidia账号了
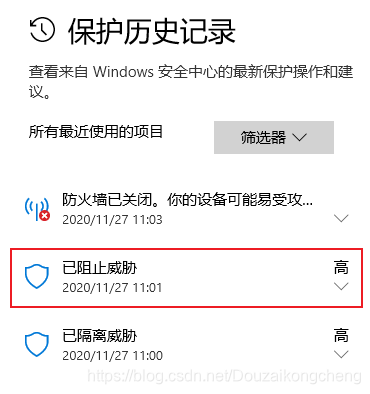
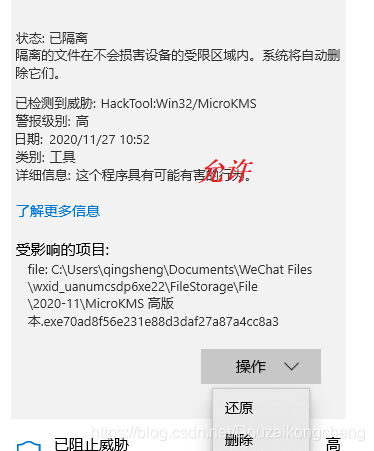
6.解除windows defender阻止
有时候需要安装一些软件,但是关了防火墙之后还是不能下载安装包,如下允许操作才可以
7.cannot connect to X server
device : cuda
: cannot connect to X server
在Linux下运用python文件出现此问题的原因为没有关闭图形界面,将py程序里的opencv图片显示代码注释掉即可!
https://blog.csdn.net/weixin_41797404/article/details/102924888
8.多GPU训练保存模型(会加.module)
多GPU用net.module.state_dict()
# net_state = {"epoch": epoch + 1,
# "network": net.module.state_dict()}
单GPU用net.state_dict()
net_state = {"epoch": epoch + 1,
"network": net.state_dict()}
9.python生成requirements文件
C:\WINDOWS\system32>pip freeze >requirements.txt
拒绝访问。
C:\WINDOWS\system32>pip freeze >C:/Users/qingsheng/Desktop/requirements.txt
C:\WINDOWS\system32>
10.控制多GPU训练,nn.DataParallel必须使用0号GPU作为主要的GPU,采用单进程多GPU
更好的方法是使用Distributed进行多进程多GPU训练,效率更高
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
11.ModuleNotFoundError: No module named 'CommandNotFound'
原因是没有这个命令,可以安装
乌班图中终端输入命令报python的错误
有谁见过这种问题么?比如随便输入个命令会报python错误
sadasd
Traceback (most recent call last):
File "/usr/lib/command-not-found", line 27, in
from CommandNotFound.util import crash_guard
ModuleNotFoundError: No module named 'CommandNotFound'
参考https://zhidao.baidu.com/question/238473577.html
参考https://ask.csdn.net/questions/758357?sort=comments_count
刚刚解决: 我是给系统新装了一个python导致的这个问题。
按照网上教程的操作执行了这样两步骤:
sudo ln -sf /usr/local/bin/python3 /usr/bin/python3
sudo ln -sf /usr/local/bin/pip3 /usr/bin/pip3
之后就出现了和你一样的问题,而且Ctrl+Alt+t也无法调用出终端。
这个local下的python3是我新装的python3(python3.6.5)
解决办法是:
找到系统之前自带的python3 (python3.5.2) 然后创建软连接指回去。
sudo ln -sf /usr/bin/python3.5 /usr/local/bin/python3
sudo ln -sf /usr/bin/python3.5 /usr/bin/python3
这是一个教训。不管给系统装多新的python,千万不要动系统自带的python python3的软连接。包括pip什么的
给自己的新版python软连接起个其他名字python36之类的别嫌麻烦。脚本里面#!/usr/bin/python36手动指定, 否则系统里的出了问题很难搞。
我这链接改回去后估计还有别的问题。一招走错步履维艰。
这次算长了个记性。另外吐槽一下当时那篇帖子。 真是误人子弟。
12.ubuntu安装screen,vim
sudo apt install screen
sudo apt install vim
新建screen关闭时可能会提示关闭终端会结束进程,但是真实的是不会结束进程的
放心关闭
13.whereis和locate命令
(base) lthpc@lthpc:/home/peng$ whereis cuda_runtime.h
cuda_runtime:
(base) lthpc@lthpc:/home/peng$ locate cuda_runtime.h
/usr/local/cuda-10.0/include/cuda_runtime.h
(base) lthpc@lthpc:/home/peng$
8.系统分区存放文件
C盘:系统盘,只放系统
D盘:安装各种程序,注意python,pycharm要indexing,不要把包文件装在D盘根下面,不然会索引D盘下所有文件
E盘:放自己的文件
14.RuntimeError: unexpected EOF, expected 743251 more bytes. The file might be corrupted.
Traceback (most recent call last):
File "C:/Users/qingsheng/PycharmProjects/untitled/A-20201108-/not_look_code/bn_test_1/demo.py", line 24, in <module>
net.load_state_dict(torch.load(model_path, map_location=torch.device('cpu'))["network"], strict=True)
File "D:\lib\site-packages\torch\serialization.py", line 426, in load
return _load(f, map_location, pickle_module, **pickle_load_args)
File "D:\lib\site-packages\torch\serialization.py", line 620, in _load
deserialized_objects[key]._set_from_file(f, offset, f_should_read_directly)
RuntimeError: unexpected EOF, expected 743251 more bytes. The file might be corrupted.
Process finished with exit code -1073740791 (0xC0000409)
错误原因,模型权重文件没有下载完成
15.vim删除多行
Esc
76 dd
删除76行
16.查看pip源
C:\WINDOWS\system32>pip config list
global.index-url='http://mirrors.aliyun.com/pypi/simple/'
global.timeout='60000'
install.trusted-host='mirrors.aliyun.com'
17.gcc编译
gcc cc.cpp -o test
gcc dd.c -o dd -I/usr/local/cuda-10.0/include -L/usr/local/cuda-10.0/lib64
出错
gcc -o my_app -L/usr/local/cuda-10.0/lib64 -lcuda -lcudart cc.cpp -I/usr/local/cuda-10.0/include
(base) lthpc@lthpc:/home/peng/homework$ python3 cuda_mul.py --MATRIX_SIZE 4000 --b 32
18.lscpu查看cpu信息
19.某个GPU坏掉导致整个集群不能使用
(base) lthpc@lthpc:~$ dmesg | grep -i xid
[344674.313497] NVRM: Xid (PCI:0000:0f:00): 79, GPU has fallen off the bus.
(base) lthpc@lthpc:~$
先把0f 拉黑名单吧
这个GPU卡貌似有问题
sudo echo 1 > /sys/bus/pci/devices/0000\:0f\:00.0/remove 临时移除,只有重启后才能生效,恢复正常。
把这个命令写入到/etc/rc.local ,重启后就会自动生效 。
注意顺序sudo echo 1 > /sys/bus/pci/devices/0000\:0f\:00.0/remove要放在行首
sudo echo 1 > /sys/bus/pci/devices/0000\:0f\:00.0/remove
sudo nvidia-smi -pm 1
sudo mount /dev/sdb1 /home
sudo mount /dev/sdc1 /data
exit 0
(base) lthpc@lthpc:~$ nvidia-smi -i 9
No devices were found
(base) lthpc@lthpc:~$ nvidia-smi -i 1
Mon Nov 9 15:47:41 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 430.26 Driver Version: 430.26 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+===|
| 1 GeForce RTX 208... On | 00000000:05:00.0 Off | N/A |
| 16% 30C P8 1W / 250W | 10MiB / 11019MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
20.pycharm无法删除一个文件
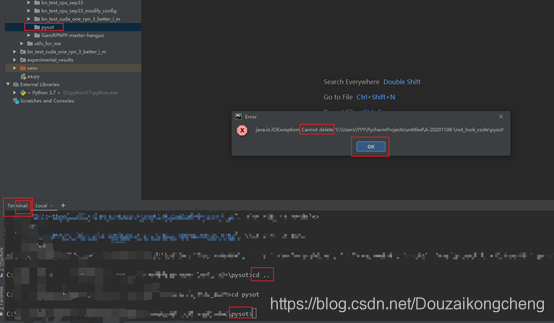
先切换到上级目录再删除
21.RuntimeError: view size is not compatible with input tensor's size and stride
这是因为view()需要Tensor中的元素地址是连续的,但可能出现Tensor不连续的情况,所以先用 .contiguous() 将其在内存中变成连续分布:
out = out.contiguous().view(out.size()[0], -1)
22.return _MultiProcessingDataLoaderIter(self)
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\python37\lib\site-packages\torch\lib\cudnn_adv_infer64_8.dll" or one of its dependencies.
return self._get_iterator()
线程数太多了,cpu利用率爆满,使用4线程可以
'--n_threads', type=int, default=4,
23.OSError: image file is truncated (28 bytes not processed)
https://blog.csdn.net/weixin_34130269/article/details/94236840
"C:\Users\YYY\PycharmProjects\untitled\Denoise\self_T_1000epoch\entire_2_connection_ori\data\srdata.py
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
24.graphviz.backend.ExecutableNotFound: failed to execute ['dot', '-Tpdf', '-O', 'Digraph.gv']问题解决
https://blog.csdn.net/qq_41997920/article/details/100928729
还没有安装,只是注释掉了
entire_2_connection\trainer_search.py
的line220
# plot_genotype(genotype.normal,
# os.path.join(folder, "normal_{}".format(epoch)))
25.if self.args.save_results: self.ckp.begin_background()
for p in self.process: p.start()
AttributeError: Can't pickle local object 'checkpoint.begin_background.<locals>.bg_target'
cation methods: 'publickey,gssapi-keyex,gssapi-with-mic,password'.
21:23:56.846 Attempting password authentication.
21:23:59.125 Authentication failed. Remaining authentication methods: 'publickey,gssapi-keyex,gssapi-with-mic,password'.
RuntimeError: DataLoader worker (pid(s) 9528, 8320) exited unexpectedly问题解决记录
仅供学习记录,若有侵权可联系删除。
方法一: num_workers设置为0,默认值为0表示不启用多进程。该方法在处理大量数据的时候还是不行,肯定要多进程。参见方法二。
在这里插入图片描述
方法二:将涉及多线程的代码放到if name == 'main’的范围内
if name == ‘main’:
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
# 假设这里就是你训练的地方…
里面的loader就是上面定义的test_loader,(指定了多进程的)。另外只需要loader的执行部分放在main之内即可,定义部分可以在main内,也可以在main之外.
Python中多进程(multiprocessing这个模块包)的内容必须放在if name == 'main’之内才可以。多线程(threading这个模块包)是没有这项限定的。
-----save_results----改为False
26.ModuleNotFoundError: No module named 'pyarrow'
(base) lthpc@lthpc:/home/library$ pip install pyarrow-2.0.0-cp37-cp37m-manylinux1_x86_64.whl --user
Processing ./pyarrow-2.0.0-cp37-cp37m-manylinux1_x86_64.whl
Requirement already satisfied: numpy>=1.14 in /opt/anaconda3-2019.3/lib/python3.7/site-packages (from pyarrow==2.0.0) (1.16.4)
27.lmdb.MapFullError: mdb_put: MDB_MAP_FULL: Environment mapsize limit reached
写入的数据超出默认值,解决方法:
env = lmdb.open('image_lmdb', map_size=int(1e9))#max_size为1e9kb,大小可调整
28.AttributeError: Can't pickle local object
https://blog.csdn.net/qq_39314099/article/details/83822593
AttributeError: Can't pickle local object 解决办法
python多进程和装饰器
今天意外的发现了python装饰器和多进程之间的一个小坑,起初简单写了一个装饰器,用来给程序计时,自测了下没有什么问题
使用lmdb对ImageNet数据进行快速读取(Pytorch)
https://blog.csdn.net/weixin_43955917/article/details/105888860
git clone https://github.com/xunge/pytorch_lmdb_imagenet
29.由于系统缓冲区空间不足或队列已满,不能执行套接字上的操作
Bitvise SSH Client在一个电脑上每次开的终端不能太多
09:44:42.257 Current date: 2020-12-30
09:44:42.257 Bitvise SSH Client 8.35, a fully featured SSH client for Windows.
Copyright (C) 2000-2019 by Bitvise Limited.
09:44:42.257 Visit www.bitvise.com for latest information about our SSH software.
09:44:42.257 Run 'BvSsh -help' to learn about supported command-line parameters.
09:44:42.257 Cryptographic provider: Windows CNG (x86) with additions
09:44:42.472 Version status: Unknown
The status of the currently installed version is unknown because there has not been a recent, successful check for updates.
09:44:42.497 Loading command-line profile 'C:\Users\YYY\Desktop\239.tlp'.
09:44:42.501 Command-line profile loaded successfully.
09:44:43.615 Started a new SSH session.
09:44:43.625 Connecting to SSH server 10.171.92.3:22.
09:44:43.625 Connection failed. FlowSocketConnector: Failed to connect to target address. Windows error 10055: 由于系统缓冲区空间不足或队列已满,不能执行套接字上的操作。.
09:44:43.625 The SSH session has been terminated.
30.OSError: image file is truncated (X bytes not processed)
OSError: image file is truncated (X bytes not processed)错误处理
光之炼金术士 2020-08-23 21:02:33 289 收藏 1
分类专栏: 软件环境
版权
训练Yolo v3时遇到以下错误:
OSError: image file is truncated (X bytes not processed)
原因:
图片太大超过限制,PIL处理不了,必须把图片删除一部分,导致报error。
解决方法:
错误信息发生的文件开头加上:
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
如果设为true,此时你加载的图片会少掉一部分,但是在大数据加载一张半张残缺图像是应该没大影响。
参考链接:https://zhuanlan.zhihu.com/p/132554622
31.lmdb.Error: F:/imagenet/train.lmdb: ���̿ռ䲻�㡣
db = lmdb.open(lmdb_path, subdir=isdir,
map_size=10995116277 * 2, readonly=False,
meminit=False, map_async=True)
windows要将num_workers=0,
map_size=10995116277 * 2 设小一点
data_loader = DataLoader(dataset, num_workers=0, collate_fn=lambda x: x)
32.RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
Traceback (most recent call last):
File "C:/Users/YYY/PycharmProjects/untitled/ImageNet-training-master/train_on_imagenet_1000.py", line 298, in <module>
main()
File "C:/Users/YYY/PycharmProjects/untitled/ImageNet-training-master/train_on_imagenet_1000.py", line 198, in main
train_acc, train_obj = train(train_queue, model, criterion_smooth, optimizer)
File "C:/Users/YYY/PycharmProjects/untitled/ImageNet-training-master/train_on_imagenet_1000.py", line 253, in train
prec1, prec5 = accuracy(logits, target, topk=(1, 5))
File "C:\Users\YYY\PycharmProjects\untitled\ImageNet-training-master\utils.py", line 72, in accuracy
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
RuntimeError: view size is not compatible with input tensor‘s size and stride
Dezeming 2020-08-23 22:30:07 1851 收藏 6
分类专栏: 出错专栏
版权
在运行程序中:
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
python报错:
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
这是因为view()需要Tensor中的元素地址是连续的,但可能出现Tensor不连续的情况,所以先用 .contiguous() 将其在内存中变成连续分布:
out = out.contiguous().view(out.size()[0], -1)
这样就好了。
33.evaluate_torch.py: error: the following arguments are required: INPUT
deepIQA
parser.add_argument('INPUT', default="./A0001_06_15.bmp", help='path to input image')
evaluate_torch.py: error: the following arguments are required: INPUT
改为--INPUT
parser.add_argument('--INPUT', default="./A0001_06_15.bmp", help='path to input image')
34.TypeError: 'tuple' object is not callable
deepIQA
self.fc1 = nn.Linear(512 * 3, 512),
TypeError: 'tuple' object is not callable
改为(去掉逗号)
self.fc1 = nn.Linear(512 * 3, 512)
35.UserWarning: To get the last learning rate computed by the scheduler, please use `get_last_lr()`.
deepIQA
D:\python37\lib\site-packages\torch\optim\lr_scheduler.py:509: UserWarning: To get the last learning rate computed by the scheduler, please use `get_last_lr()`.
(conv5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
"please use `get_last_lr()`.", UserWarning)
改为
current_lr = scheduler.get_last_lr()[0]
print('lr :', current_lr)
36.dropout影响测试精度
deepIQA
模型在测测试阶段,不去掉dropout每次测试的结果都不一样,去掉之后就一样了
h = F.dropout(h)
model.eval()
with torch.no_grad():
pass
37.windows安装cupy,没成功
pip install chainer-cuda-deps
https://blog.csdn.net/qq907482638/article/details/102586724
ModuleNotFoundError: No module named 'cupy'
pip search cupy
报错
pip install cupy-cuda110
D:\python37\python.exe C:/Users/YYY/PycharmProjects/untitled/IQA/deepIQA/evaluate.py
Traceback (most recent call last):
File "C:/Users/YYY/PycharmProjects/untitled/IQA/deepIQA/evaluate.py", line 16, in <module>
from nr_model import Model
File "C:\Users\YYY\PycharmProjects\untitled\IQA\deepIQA\nr_model.py", line 11, in <module>
cuda.check_cuda_available()
File "D:\python37\lib\site-packages\chainer\backends\cuda.py", line 142, in check_cuda_available
raise RuntimeError(msg)
RuntimeError: CUDA environment is not correctly set up
(see https://github.com/chainer/chainer#installation).CuPy is not correctly installed.
If you are using wheel distribution (cupy-cudaXX), make sure that the version of CuPy you installed matches with the version of CUDA on your host.
Also, confirm that only one CuPy package is installed:
$ pip freeze
If you are building CuPy from source, please check your environment, uninstall CuPy and reinstall it with:
$ pip install cupy --no-cache-dir -vvvv
Check the Installation Guide for details:
https://docs.cupy.dev/en/latest/install.html
original error: DLL load failed: 找不到指定的模块。
Process finished with exit code 1
38.No module named ignite.engine
IQA
No module named ignite.engine 解决方案
https://blog.csdn.net/weixin_44273380/article/details/109272186?utm_medium=distribute.pc_relevant_bbs_down.none-task-blog-baidujs-1.nonecase&depth_1-utm_source=distribute.pc_relevant_bbs_down.none-task-blog-baidujs-1.nonecase
你们所需要的那个有.engine的ignite是pytorch的一个扩展包。真正的全名叫pytorch-ignite。只不过导入的时候前面那个pytorch省掉了。
给大家看下作者在github中指出的正确安装方式:
所以说,其实这个错误很简单,就是你装错包了。改成
pip install pytorch-ignite
39.ValueError: too many dimensions 'str'
IQA
self.label_std.append(line.split(",")[1])
报错是ValueError: too many dimensions 'str'。这个错误可以回溯到tensor对象的生成。结论是split读入文件时,标签是以[“1”]这样的str列表读入的,但是生成词表时需要[1]这样的数字列表。
加上其他博客写的,遇到这个错误可能的原因是某些数据是数字类型的,却以str对象的形式传入torch.tensor中,记得转换。;
self.label_std.append(float(line.split(",")[1]))

















 2744
2744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









