







实验背景:
让工作自动化,这是很多人的在纷繁复杂的工作环境中想要达到的,尤其是一些大量的重复性劳动。而程序员则被大家认为可以实现这一目标的首选人群。这不,就有人让我来帮忙处理一堆Excel表格了。
(眼高手低的我觉得这个 so easy, 应声接下。却意外的折腾了好久。。。)
实验目标:
读取文件夹下所有Excel表格(CSV格式)的最后一行写入新文件。
实验步骤
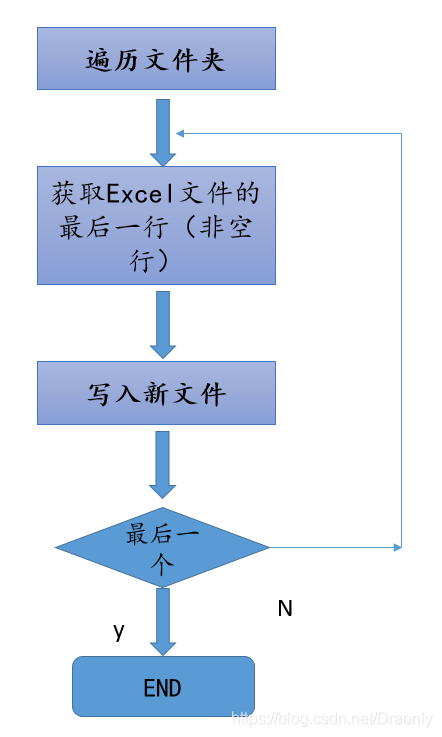
代码程序
1. 遍历文件夹
#遍历文件夹
def getFileName(filepath):
file_list = []
for root,dirs,files in os.walk(filepath):
for filespath in files:
print(os.path.join(root,filespath))
file_list.append(os.path.join(root,filespath))
return file_list
2. 获取文件最后一行非空行
#获取文件最后一行非空行
def get_file_last_line(inputfile):
filesize = os.path.getsize(inputfile)
blocksize = 1024
with open(inputfile, 'r') as f:
last_line = ""
if filesize > blocksize:
maxseekpoint = (filesize // blocksize)
f.seek((maxseekpoint - 1) * blocksize)
elif filesize:
f.seek(0, 0)
lines = f.readlines()
if lines:
lineno = 1
while last_line == "":
last_line = lines[-lineno].strip()
lineno += 1
print (last_line)
return last_line
3.写入新文件
def write_csv(data):
with open(outfile,'a+') as f:
#这里要加上delimiter=‘,’ 表示以逗号作为分隔符,将读取到的数据重新写入新文件
csv_write = csv.writer(f,delimiter=',')
csv_write.writerow((str(data),))
open()函数参数说明
r 只能读,即带r的文件必须先存在
r+ 可读可写 不会创建不存在的文件 从顶部开始写 会覆盖之前此位置的内容
w+ 可读可写 如果文件存在 则覆盖整个文件不存在则创建 ,要close 之后才算完成写入
w 只能写 覆盖整个文件 不存在则创建
a 只能写 从文件底部添加内容 不存在则创建
a+ 可读可写 从文件顶部读取内容 从文件底部添加内容 不存在则创建
r+可读可写,不会创建不存在的文件。如果直接写文件,则从顶部开始写,覆盖之前此位置的内容,如果先读后写,则会在文件最后追加内容。
r、rb、rt区别
使用’r’一般情况下最常用的,但是在进行读取二进制文件时,可能会出现文档读取不全的现象;
使用’rb’按照二进制位进行读取的,不会将读取的字节转换成字符,二进制文件用二进制读取用’rb’ ;
rt模式下,python在读取文本时会自动把\r\n转换成\n,文本文件用二进制读取用‘rt’;
中间遇到的问题
写到文件中的数据分隔的不正确,
本来是这样的数据82.1875,41.99480057,1689,11.79143657,1
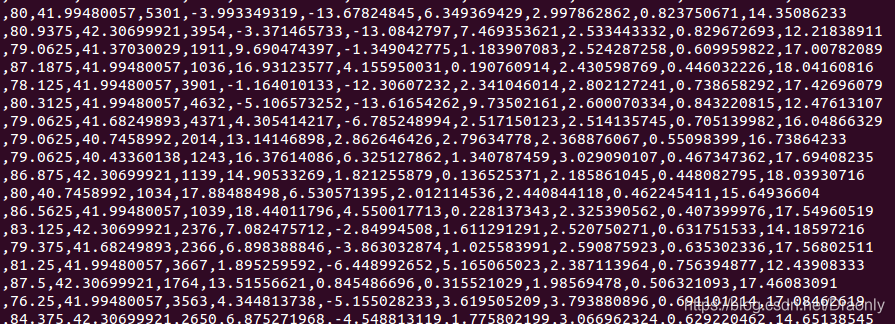
由于最开始是这样写的
csv_write = csv.writer(f)
csv_write.writerow(data)
然后写到表中的数据就成了这样。。
每个数据单独在一格。
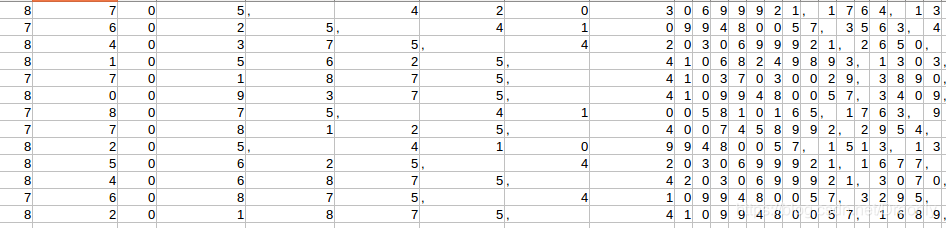
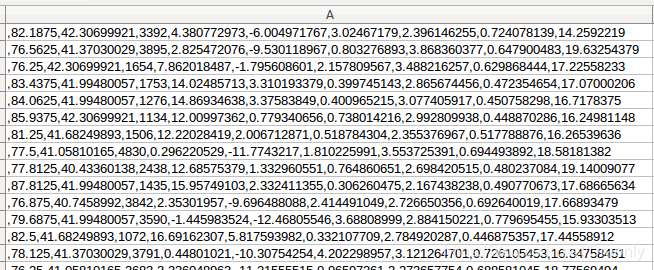
逗号分隔符
使用逗号分隔符,下面一行不改,左右数据却都写在了第一列。
csv_write = csv.writer(f,delimiter=’,’)
最后一行修改为下面代码,.将其作为一个元组
writer.writerow((str(row),))
总算OK了。。
4 程序
#!/usr/bin/env python3
# coding=utf-8
import pandas as pd
import os
import os.path
import csv
from xlutils.copy import copy
def getFileName(filepath):
file_list = []
for root,dirs,files in os.walk(filepath):
for filespath in files:
print(os.path.join(root,filespath))
file_list.append(os.path.join(root,filespath))
return file_list
#last line
def get_file_last_line(inputfile):
filesize = os.path.getsize(inputfile)
blocksize = 1024
with open(inputfile, 'r') as f:
last_line = ""
if filesize > blocksize:
maxseekpoint = (filesize // blocksize)
f.seek((maxseekpoint - 1) * blocksize)
elif filesize:
f.seek(0, 0)
lines = f.readlines()
if lines:
lineno = 1
while last_line == "":
last_line = lines[-lineno].strip()
lineno += 1
print (last_line)
return last_line
def MergeExcel(filepath,outfile):
#df=pd.read_csv(outfile, engine='python')
file_list=getFileName(filepath)
print (len(file_list))
for each in file_list:
data = get_file_last_line(each)
write_csv(data)
def write_csv(data):
with open(outfile,'a+') as f:
csv_write = csv.writer(f,delimiter=',')
csv_write.writerow((str(data),))
if __name__ == '__main__':
filepath='/home//file/table_file'
outfile = '/home//file/result.csv'
MergeExcel(filepath, outfile)














 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









