




ELK 日志采集系统搭建

一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。
常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
1. 架构
ELK是Elasticsearch+Logstash+Kibana简称.
- Elasticsearch 是一个分布式的搜索和分析引擎,可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在是使用最广的开源搜索引擎之一。
- Logstash 简单来说就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端,与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供了很多功能强大的滤网以满足你的各种应用场景。
- Kibana 是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图标、表格、地图等,kibana能够很轻易的展示高级数据分析与可视化。
一个简单的 ELK 架构图如下:
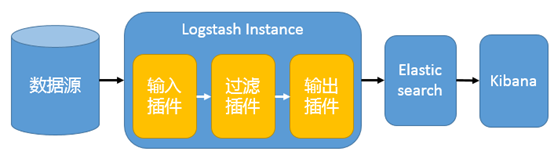
在这种架构中,Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 进行可视化展示。
这种架构非常简单,使用场景也有限。初学者可以搭建这个架构,了解 ELK 工作模式, 但是生产环境中并不推荐. 如要有以下问题:
- Logstash 依赖 java、在数据量大的时候,Logstash 进程会消耗过多的系统资源,这将严重影响业务系统的性能。因此官网现已经推荐通过 filebeat 代替 Logstash Agent。
- Logstash 将资源耗尽系统或者其自身出故障的问题时,日志数据将会出现丢失等问题,因此引入 Kafka 集群作为消息缓冲队列以提高数据传输的可靠性和稳定性。
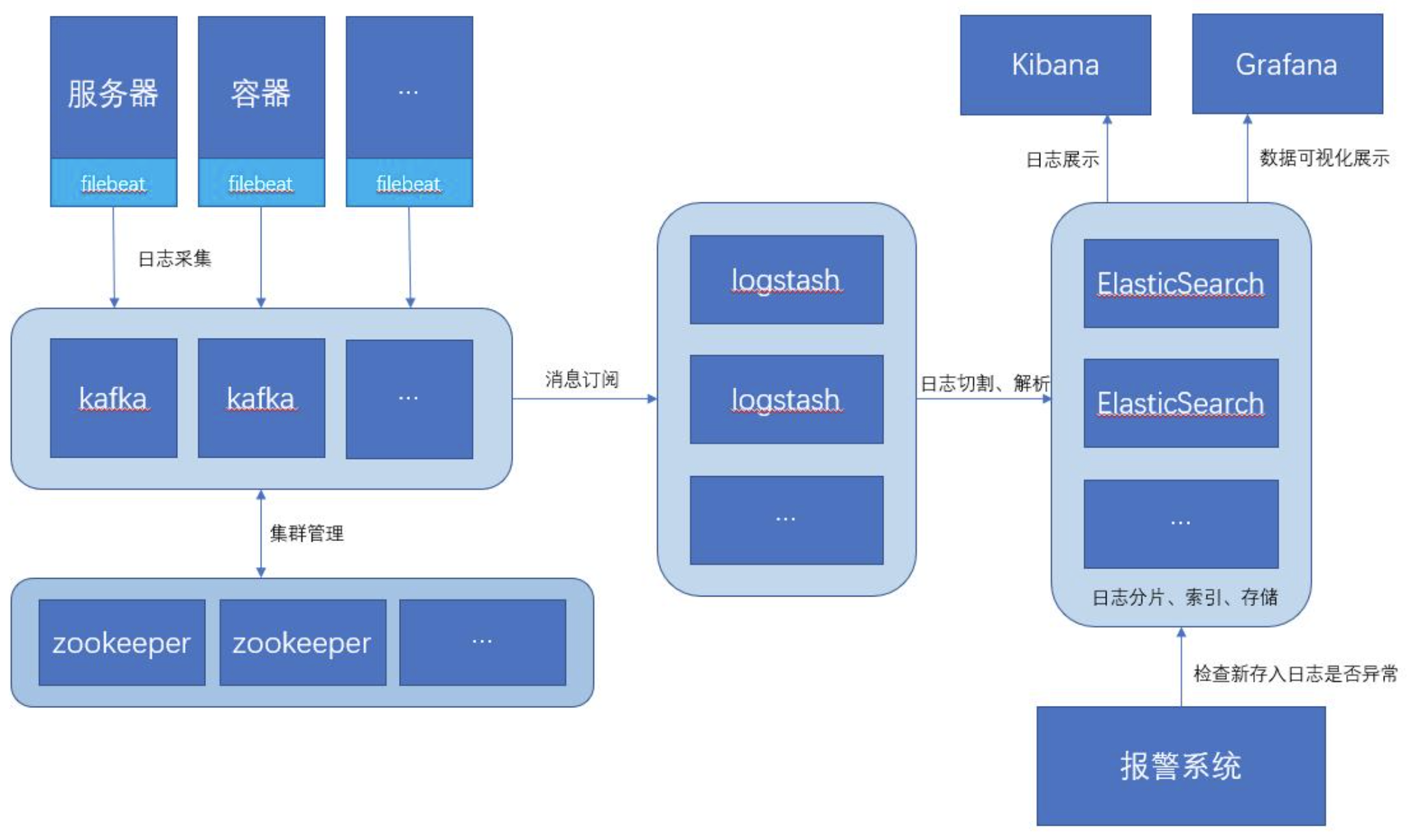
如此一来, 此架构特别适合大型集群、海量数据的业务场景,它通过将前端 Logstash Agent 替换成 filebeat,有效降低了收集日志对业务系统资源的消耗。同时,消息队列使用kafka集群架构,有效保障了收集数据的安全性和稳定性,而后端Logstash和Elasticsearch均采用集群模式搭建,从整体上提高了ELK系统的高效性、扩展性和吞吐量。
推荐的架构图如下:
2. 环境搭建
本文首先采用最简单的架构方式进行搭建, 后续博文将一步一步完善到生产环境集成消息队列的架构方式.
本次环境采用Docker或者DockerCompose搭建, 如果还不能熟练使用麻溜去看帅帅之前发布的Docker 全家桶系列视频教程:
版本如下:
Elasticsearch: 6.8.16Logstash: 6.8.16Kibana: 6.8.16
2.1 拉取镜像创建网络
docker pull elasticsearch:6.8.16
docker pull kibana:6.8.16
docker pull docker.elastic.co/logstash/logstash:6.8.16
# 创建 ELK 运行的网络
docker network create elastic
2.2 ElasticSearch
- 配置
elasticsearch.yml
cluster.name: "es-docker-cluster"
network.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
- 安装与启动
通过如下 Docker 命令:
docker run -d --name elasticsearch --network elastic \
-p 9200:9200 -p 9300:9300 \
-e node.name=esNode -e cluster.name=es-docker-cluster -e discovery.type=single-node \
-e bootstrap.memory_lock=true -e "ES_JAVA_OPTS=-Xms1024m -Xmx1024m" \
-v ${CONF_DIR}/es:/usr/share/elasticsearch/config \
-v ${VOLUME_DATA_DIR}/es:/usr/share/elasticsearch/data \
-v ${LOGS_DIR}/es:/usr/share/elasticsearch/logs \
elasticsearch:6.8.16
其中,
CONF_DIR,VOLUME_DATA_DIR,LOGS_DIR是我本地配置的环境变量, 指向一个固定的文件夹用于挂载 Docker 容器的配置文件, 数据卷和日志文件.
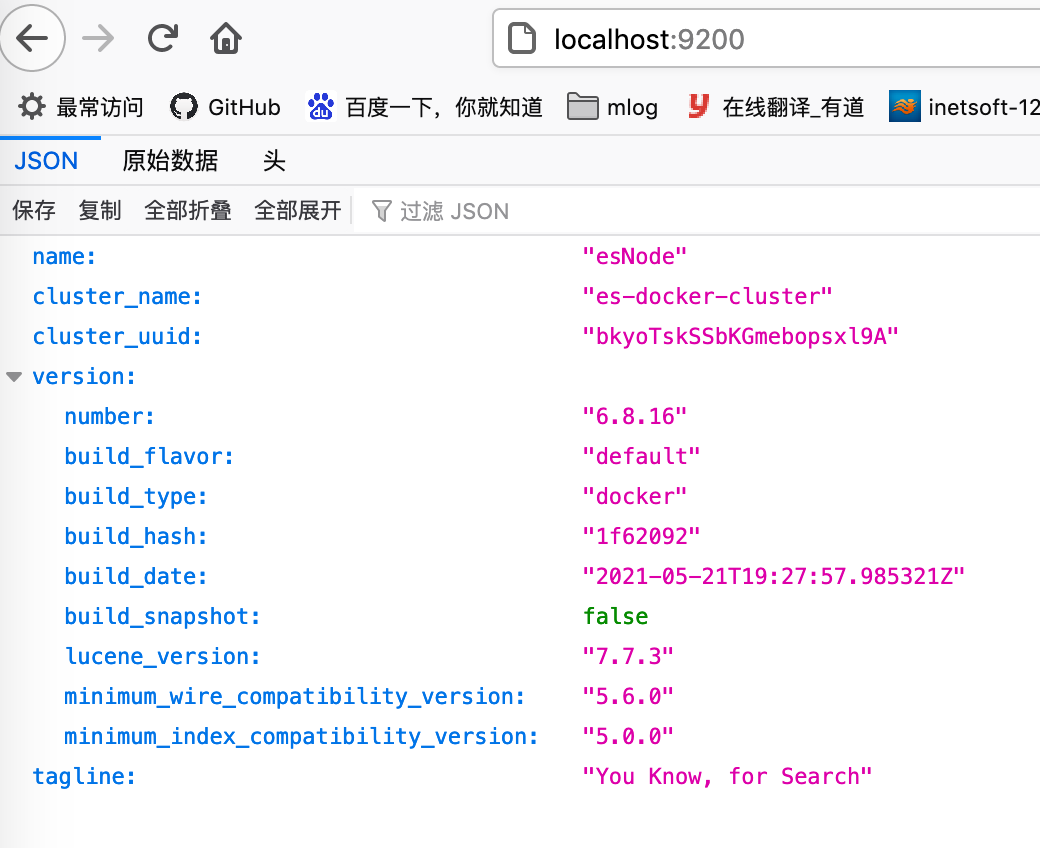
- 测试
访问 http://localhost:9200/ 看到如下界面就表示 Elasticsearch 启动成功.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1485
1485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









