







目录
Pandas 是一种基于 NumPy 的开源的数据分析和处理工具包,提供了高性能、简单易用的数据结构和数据分析函数。Pandas提供了方便的类表格和类SQL的操作,同时提供了强大的缺失值处理方法,通过Pandas可以方便的进行数据导入、选取、清洗、处理、合并、统计分析等操作。
Python标准库中默认不包含 Pandas,需要自己下载安装:
-
命令行安装 pip install pandas;
-
借助于第三方包管理软件,例如Anaconda;
基本结构之Series
Pandas 中的 Series 对象可以理解为带有标签数据的一维数组,标签在Pandas中有对应的数据类型“Index”,Series类似于一维数组与字典的结合。
Series对象的创建
创建Series时,可通过index参数指定索引,未指定索引时,采用默认索引,从0开始,不断递增;创建Series的主要方式如下:
-
通过列表、元组创建:索引大小必须和列表大小一致;
-
通过numpy的ndarray创建:必须是一维数组,且数组大小和索引大小要一致;
-
通过字典创建:默认索引为字典的关键字,指定索引时,会以索引为键获取值,没有值时,默认为NaN;
-
通过标量创建 :重复填充标量到每个索引上;

创建好Series对象后,可通过values 属性获取具体值,类型为一维ndarray;可通过index属性获取相应索引,类型为Index;
Index对象介绍
Pandas 的 Index 对象可以看作是一个不可变数组,Index 对象中可以包含重复值。可直接通过Pandas中的Index类创建Index对象,也可以通过Series或DataFrame中的 index属性获取对应的Index对象。Index对象可以在多个数据间共享。例如:

Index对象的很多操作都与numpy 中的数组类似,例如支持索引和切片操作,支持Numpy中的一些常见函数,拥有size,shape,ndim 等属性。不同的是Index 对象的值是不可变的。Index 对象的不可变特征使得多个数据之间进行索引共享时更加安全,可避免因修改索引时而导致的副作用。
Index对象也支持集合操作,例如如并集、 交集、 差集等,这些操作也可以通过调用对象方法来实现。不同的是操作结果中可能会存在重复的元素。
Series中数据的访问
Series 对象与 numpy 中的一维数组 和 字典 dict在很多方面都类似。Series 对象中数据访问可与它们进行类比学习。
(1)将Series看作字典
-
字典中的键不允许重复,但Series中的索引允许有重复值;
-
以索引为键,可访问对应的值,如果有多个,则结果为Series类型;
-
可调用字典的一些常见方法,如keys()、items()等,可判断是否包含指定索引;
-
可用字典类似语法更新数据,对已有的索引进行赋值,会修改索引对应的值,对一个不存在的索引进行赋值,会添加一个索引。

系统一般会为Series对象默认分配一个从0开始不断增大的索引,称为隐式索引;用户通过index指定的索引称为显式索引。如果显式索引为整数,容易冲突,通过键访问采用的是显式索引,通过切片访问采用的是隐式索引,尽量不要使用整数作为显式索引。其他情况下,两种方式可以共存。
(2)将Series看作一维数组
-
可以通过索引、切片、布尔表达式访问数据;
-
通过切片访问时,显式索引结果包含最后一个索引,隐式索引结果不包含最后一个索引。

(3)索引器:loc、iloc
-
loc: 显式索引访问,即根据用户指定的索引访问;
-
iloc: 隐式索引访问,即根据位置序号访问。

Series中常用方法
-
sort_index():对Series按照索引排序,生成一个新的Series对象;
-
sort_values():对Series按照值排序,生成一个新的Series对象;
-
rank():对值进行排名,从1开始,对于相同的值默认采用平均排名;
-
reindex():重新设置索引,生成一个新的Series对象。新的索引长度和原始索引长度可以不相同,如果新的索引不在原始数据中,则对应的值为NaN,如果在原始数据中,则值保持不变,可通过method参数指定值填充的方案(要求原始索引是递增的),还可通过fill_value参数指定填充值;
-
Series对象也可执行numpy中的一些运算,此时只对值进行操作,索引和值之间的对应关系不变;
-
Series对象之间执行运算时,会自动进行对齐,相同索引之间执行相应运算,不同索引对应的值为NaN。

基本结构之DataFrame
DataFrame可以看作是一种既有行索引, 又有列索引的二维数组,类似于Excel表或关系型数据库中的二维表,是Pandas中最常用的基本结构。前面介绍的Series只有一列数值,DataFrame中往往有多列数值,一列可以看成是一个Series组成。
DataFrame的创建
可通过值为一维ndarray,list, dict或者Series的字典或列表;二维的ndarray;单个Series、列表、一维数组,此时DataFrame中只有一列;其他的DataFrame等创建;
创建DataFrame时,可通过index和columns参数指定行索引 和 列索引,若没有指定索引,则系统会提供默认索引,从0开始不断增大;
通过多个Series创建DataFrame时,多个Series对象会自动对齐,即多个Series对象会根据行索引自动匹配,行索引相同的放在同一行。若指定了index ,则会以指定的索引为准,去匹配已有的值,丢弃所有未和 index匹配的数据 ,如果指定的索引没有提供对应的值,则表示该值缺失,使用NaN。
 DataFrame中数据访问
DataFrame中数据访问
DataFrame对象与二维 numpy 数组和 共享索引的若干个Series对象构成的字典有很多相似之处,DataFrame中数据的访问可与它们进行类比学习。
(1)将 DataFrame 看作字典
-
以列的索引为关键字,获取某一列数据,例如d_1[列索引],结果为Series对象,可进一步获取某个数据,例如d_1[列索引][行索引],需要使用两个中括号,不能合并;
-
如果列的索引为字符串,则可以列名为属性名,获取某一列数据,例如d_1.属性名,前提是列名符合标识符的命名规范。如果列名不符合规范或与 DataFrame 中属性相同,例如shape、index等,则不能用属性形式。

与Series类似,DataFrame中也存在隐式索引和显式索引。显式索引主要是根据用户指定的索引访问数据,而隐式索引主要是根据系统生成的索引即位置序号访问数据。DataFrame也支持索引器访问数据,其中loc[行索引, 列索引]通过显示索引访问数据, iloc[行索引, 列索引]通过隐式索引访问数据。
(2)将DataFrame看作二维数组
-
支持行列转置、布尔表达式等;
-
支持行切片操作,不支持列切片。若想访问多列数据,可将多个列索引放在一个列表中,例如d_1[[列1,列2]];

DataFrame 常见属性
-
shape:获取形状信息,结果为一个元组;
-
dtypes:获取各字段的数据类型,结果为Series;
-
values:获取数据内容,结果通常为二维数组;
-
columns:获取列索引,即字段名称,结果为Index;
-
index: 获取行索引,即行的标签,结果为Index。
-
axes:同时获取行和列索引,结果为Index的列表;
DataFrame 常见方法
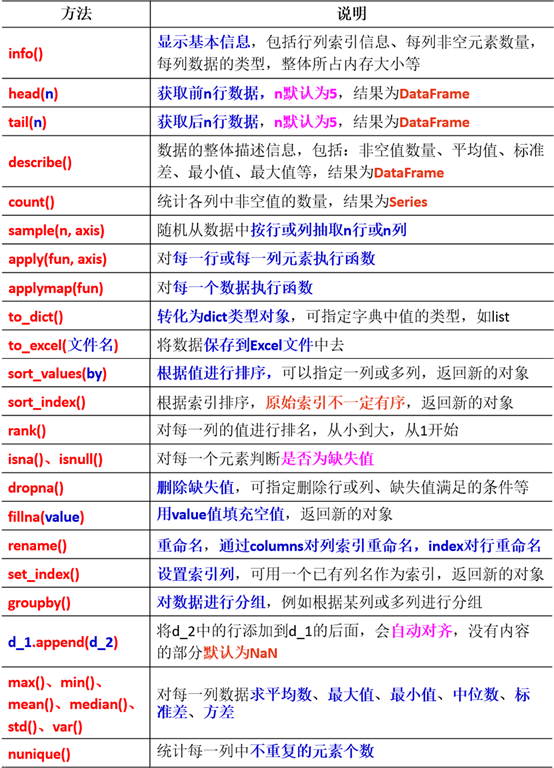
DataFrame中提供了大量的实用方法,例如按照某一列或多列的值进行排序、将DataFrame中的数据保存到文件中、进行抽样、分组、统计、去重等等。详细方法介绍如下:
 DataFrame的合并操作
DataFrame的合并操作
DataFrame中提供了一个join()方法用于将其他DataFrame中的列合并到当前DataFrame中,类似于数据库中的连接,支持内连接(只保留两个对象中都存在的行索引对应的数据)、外连接(保留两个对象中,只要有一方存在的行索引对应的数据,如果另一方不存在则相应值为NaN)、左连接(只保留左边对象中的所有行索引对应的数据)和右连接(只保留左边对象中的所有行索引对应的数据)等,默认情况采用左连接。join()方法合并数据时,默认根据两个对象的行索引进行匹配连接,如果有相同列名,则需指定后缀以区分,否则会出错,也可通过on参数指定合并时参考的列,此时需将该列作为其他对象的行索引,也就是说让另一个对象的行索引和当前对象的on进行匹配。

Pandas中常用方法
加载数据的方法
Pandas中提供了大量的从不同格式文件中加载数据的方法,例如读取Excel文件、CSV文件、Json格式文本、HTML网页等等,大家可以根据实际需求,选择相应的方法,每个方法根据文件特征需要传递的参数不同,可关联源代码查看详情。主要的方法如下:
-
read_excel():从excel文件中读取数据;
-
read_csv():从csv文件中读取数据;
-
read_clipboard():从剪切板中数据;
-
read_html():从网页中读取数据;
-
read_json():从 json 格式文本中读取数据;
-
read_pickle():从pickle文件中读取数据;
-
……
在此,以实际应用中使用比较广泛的Excel文件读取为例,介绍一些核心的参数含义。
-
io:文件路径,可以是本地文件也可以是网络文件,支持xls、xlsx、xlsm等格式;
-
sheet_name:表单序号或名称,可以是一个列表,表示同时读取多个表单,默认为第一个表单;
-
hearder:表头,可以是整数或整数列表,默认为第一行;
-
names:指定列名,默认为表头;
-
index_col:索引列,可以是整数或整数列表;
-
usecols:使用到的列,默认加载所有列,如果需要加载某些列可指定这些列的序号;
-
dtype:指定每一列的数据类型;
-
skiprows:跳过多少行,常用于表的最开始几行为说明性文档的情景;
-
nrows:解析多少行;
-
na_values:指定哪些值被看做是缺失值;
-
……
数据显示的方法及关键属性
Pandas中提供了数据显示的一些默认设置,例如默认显示60行,超过60行只显示前5行、后5行其他都用省略号表示等。可通过一些方法更改设置,相应方法如下:
-
get_option(属性名):获取相应的属性值;
-
set_option(属性名,值):设置相应的属性值;
-
reset_option(属性名):重置相应的属性值,恢复成默认值;
-
describe_option(属性名):获取相应的属性描述信息,包括默认值,当前值等信息;
-
option_context(属性名):设置临时的属性值,主要用于上下文管理器中;
显示设置中经常使用到的一些属性如下:
-
display.max_rows:显示的最大行数,默认为60行,超过60行时,只显示前5行、后5行,其他行用省略号表示,None表示不限制,显示所有行;
-
display.max_columns:显示的最大列数,默认为0,根据宽度自动确定,显示不下时,中间列用省略号表示,None表示不限制,显示所有;
-
display.expand_frame_repr:是否换行打印超过宽度的数据,默认为True,当不限制列的数量,同时一行又放不下那么多列信息时,默认会自动换行,可设置为False,这样会添加水平滚动条,在一行显示;
-
display_max_colwidth:显示的最大列宽,默认为50个字符,超出以省略号表示,None表示不限制;
-
display.precision:设置小数显示精度,默认为6位。

缺失值处理方法
缺失值是指数据集中的某些值为空。常见的处理方法有:删除法、替换法和插补法。
-
删除法:直接将包含缺失值的记录删除,常用于缺失值比例非常低,如5%以内;
-
替换法:用某种值直接替换缺失值,例如连续变量的均值或中位数,离散变量的众数等;
-
插补法:根据其他已观测值进行预测,例如K近邻、回归插补法等;
Pandas中提供了强大的缺失值处理,相关方法如下:
-
dropna():删除包含缺失值的行,可通过axis参数设置删除所在列,通过thresh参数指定阈值,只有非空值大于该阈值的行或列才保留;
-
fillna():用指定值填充缺失值,可为不同的列指定不同的填充值,此时传递一个字典,键为列名,值为该列缺失值的填充值,可通过method参数指定填充方式;通过limit参数限定填充的数量;
-
isna()或isnull():判断元素是否为缺失值,如果元素为缺失值,则对应位置为True,否则为False。

Pandas中的分组操作
分组操作主要是根据某个或某些特征对原始数据进行分割,然后可以在子集上应用一些函数,例如聚合、转换、过滤等,Pandas中的分组通过groupby函数实现。Series 和DataFrame 都支持分组操作。分组后将得到一个分组对象,通过groups属性可查看分组信息,通过get_group()可获取某个组详情,通过agg()可对组执行聚合函数,通过transform()方法可对组进行转换,通过filter()方法对某些组进行过滤。

Pandas中的数据合并操作
数据合并是指将多个数据按照一定的规则合并到一起。在实际应用中,常常涉及多个数据的联合操作,而这些数据又保存在不同的文件中,此时需要先进行合并,再执行相关操作。Pandas中提供了一些数据合并的方法,例如merge()、contact()等。
(1)merge()方法,按照某列或某些列将两个数据对象进行合并,与前面介绍的DataFrame中的join()方法非常相似。
-
left:左边的数据对象;
-
right:右边的数据对象;
-
how:连接方式,默认为inner,此外还有left、right、outer等;
-
on:连接的列名称,必须在两个对象中,默认以两个对象的列名的交集作为连接键;
-
left_on:左边对象中用于连接的键的列名;
-
right_on:右边对象中用于连接的键的列名;
-
left_index:使用左边的行索引作为连接键;
-
right_index:使用右边的行索引作为连接键;
-
sort:是否将合并的数据排序,默认为False;
-
suffixes:列名相同时,指定的后缀。

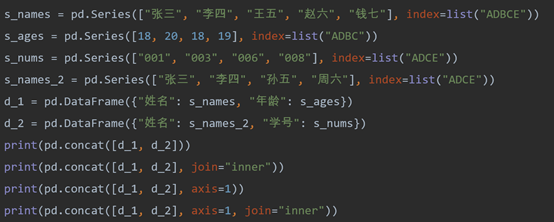
(2)contact()方法,沿着一条轴,将多个对象堆叠起来,关键参数如下:
-
objs:需合并的对象序列;
-
axis:指定合并的轴,0/‘index’, 1/‘columns’,默认为0;
-
join:连接方式,只有inner和outer,默认为outer;
-
ignore_index:是否忽略索引,默认为False;
-
verify_integrity:验证完整性,较为耗时,默认为False;
-
……

更多关于手把手教你学Python的文章请关注微信公众号:Python资源分享。详细的视频讲解可查看 CSDN学院 里的手把手教你学Python系列视频:https://edu.csdn.net/lecturer/5686。
完整的课件下载网址如下:
















 1706
1706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











