







大家新年好,新一期资源整理博客。
1 Coding:
1.R语言包radiant.basics,使用R和shiny的商业分析软件包。
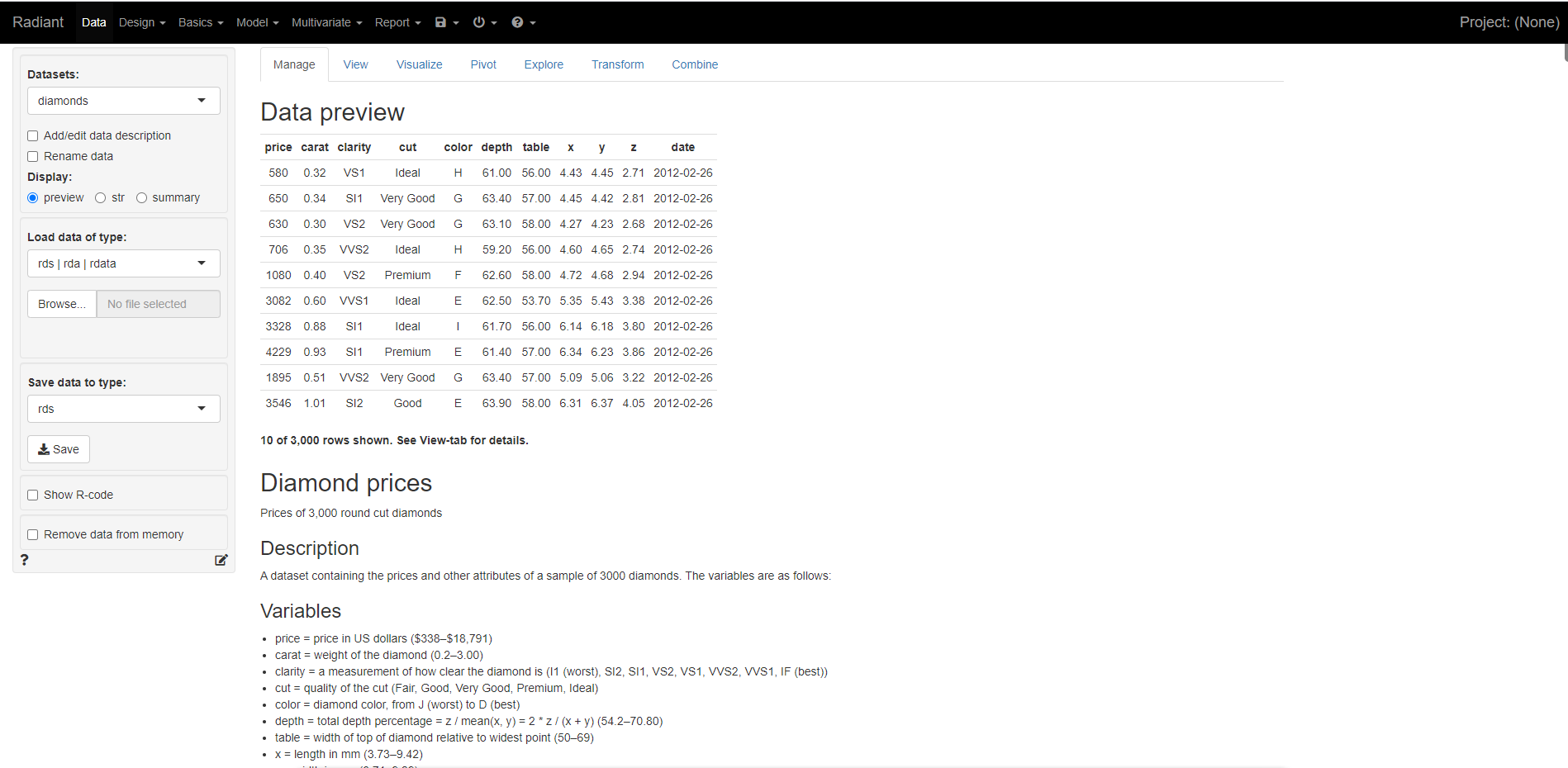
2.一个用于探索和发布数据的开源多功能工具,Datasette是用于浏览和发布数据的工具。 它可以帮助人们获取任何形状或大小的数据,并将其发布为交互式,可探索的网站和API。
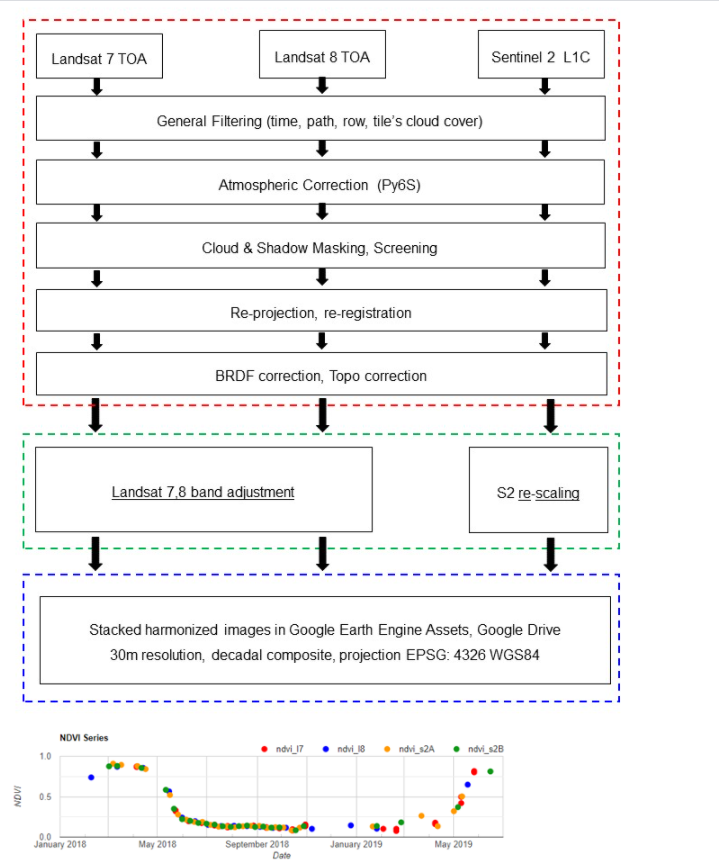
3.关于作者硕士论文的技术部分,基于Google Earth Engine实现的结合Landsat和Sentinel 2以进行作物监测。
4.处理道路相关数据的流程化脚本。
5.小麦枯萎病杀菌剂功效的Meta分析。
6.OpenMapKit Server是OpenMapKit的轻量级服务器组件,用于处理OpenStreetMap和OpenDataKit数据的收集和聚合。
7.OpenMapKit的主要文件。
8.世界卫生组织的开源沟通频道。
open source communication channel
9.现代C++的教程。
10.InVEST模型的docker镜像。
11.R语言包targettypes,是target包的目标原型和管道原型的集合。 这些原型使用简洁的语法表示复杂的流水线,从而增强了可读性,从而提高了可重复性。
12.R语言包rstac, SpatioTemporal Asset Catalog 的R客户端,SpatioTemporal Asset Catalog是用于描述地理空间信息数据的文件和Web服务的规范。
13.Adobe Illustrator的Javascript脚本集合。
14.Python库xarray_leaflet,leaflet的xarray拓展插件。
15.局部气候分区图的多标签机器学习标注,还在建设中。
16.QGIS的资源。
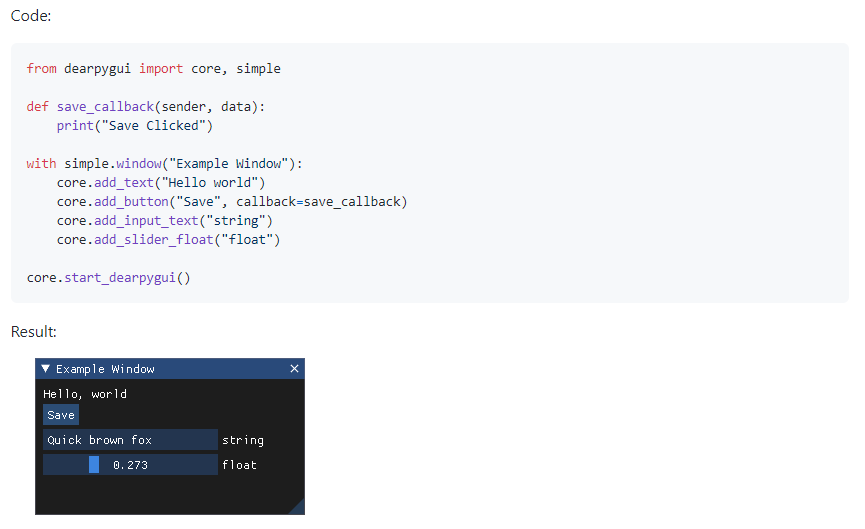
17.Python库DearPyGui,一个快速且有力的GUI工具。
18.Kevin Murphy《概率机器学习》的一系列书籍。
19.UCL CASA的课程编程导论。
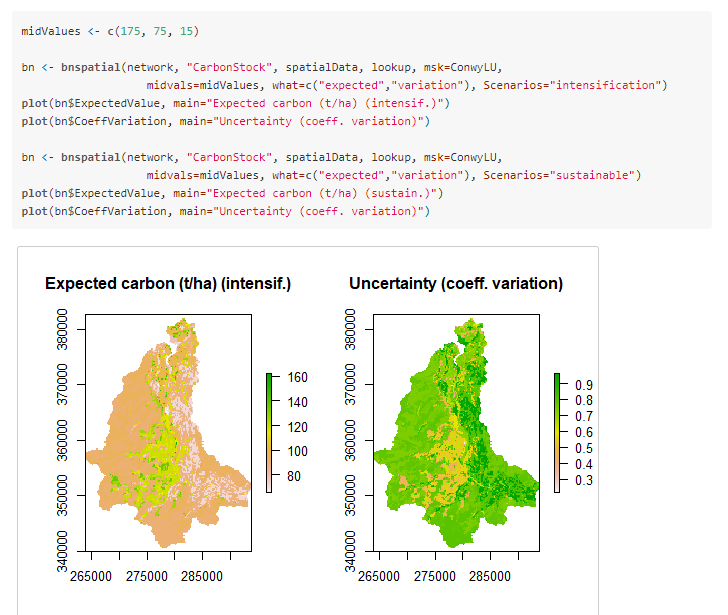
20.R语言包bnspatial,贝叶斯网络与地理空间制图的空间化实现。
21.Aalto GIS课程的CSC JupyterLab环境。
22.R语言包rmdrive,提供了简单的功能可将rmd文件移动到google drive以进行同步协作,然后将其返回到本地.Rmd进行修订。
23.R语言包USAboundaries,用以获取美国的历史和当代边界数据。
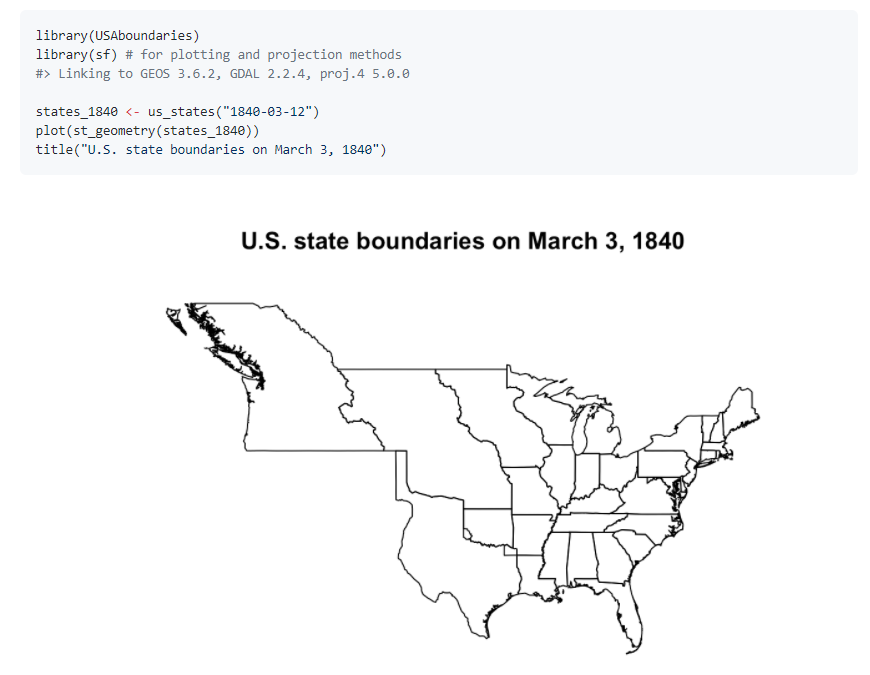
24.局部气候分区图的例子。
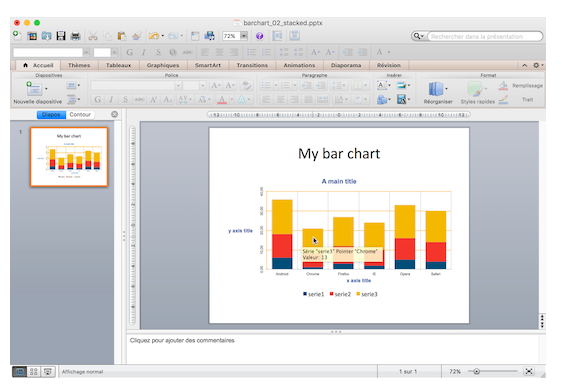
25.R语言包mschart,方便创建可以用于Microsoft Power Point的可交互式图片。
26.一位生态学家的Shiny介绍。
27.gdal-summarize.py的目标是汇总跨图层的栅格数据。
28.更简单构建机器学习API的方式。
29.一个基于Postgres SQL与PostGIS构建的开源地理空间轨迹数据库。

30.R语言包ape,系统发育和进化分析。
31.贝叶斯方法+概率编程的介绍,纯Python实现。
Probabilistic Programming and Bayesian Methods for Hackers
32.R语言包rgeoboundaries,geoboundaries API的R客户端。

33.课程可持续发展的空间数据科学的jupyter Notbebook(学生版本)。
34.100天的tensorflow概率实验。
tensorflow probability 100days
35.开源web地图js库openlayers。
36.rspatialdata的主页。
37.R语言包DataEditR,在R中手动输入和编辑数据可能很繁琐,尤其是如果您的编码经验有限并且习惯于使用带有图形用户界面(GUI)的软件。 DataEditR是一个基于shiy和可扩展的R软件包,可以轻松地交互查看,输入,过滤和编辑数据。
38.一个用于构建管理面板和内部工具的Web框架。

39.Rowan University生物学家的数据科学的课程资料。
40.plaidml是一个框架将深度学习应用到不同领域。
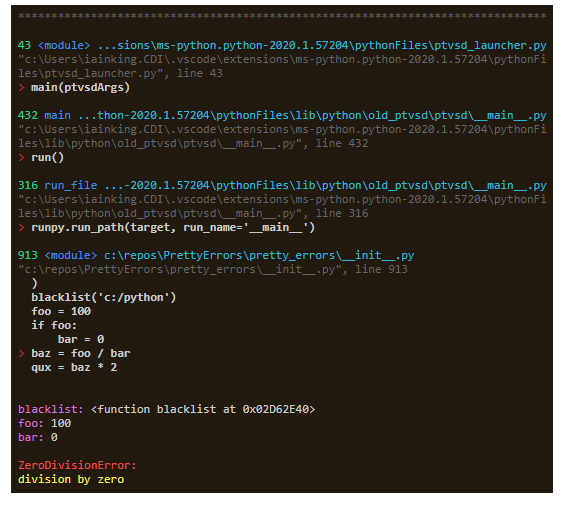
41.Python库PrettyErrors,美化Python异常输出以使其清晰可见。
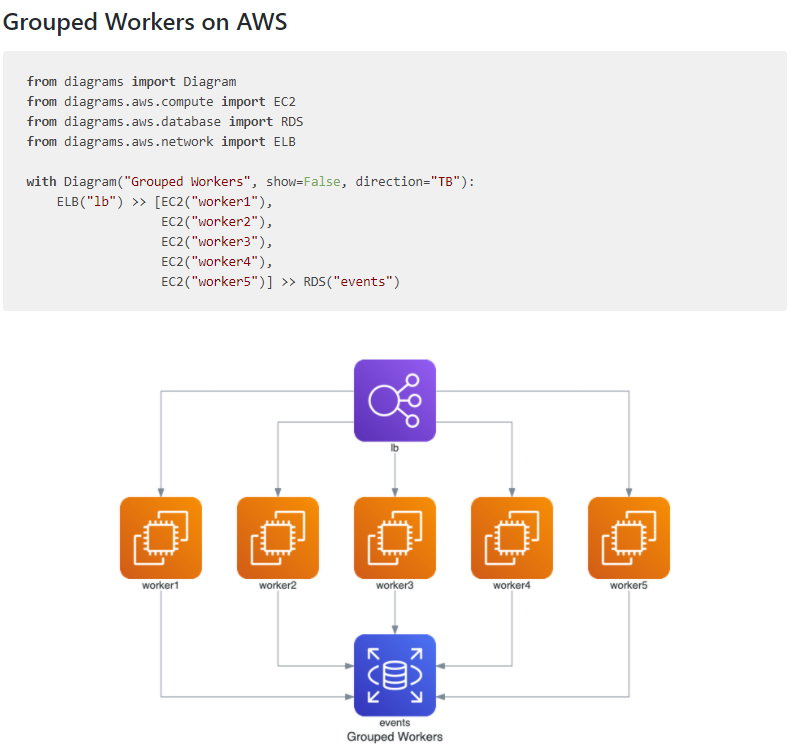
42.Python库diagrams,使您可以用Python代码绘制云系统架构。 它的诞生是为没有任何设计工具的新系统架构设计提供原型。 您还可以描述或可视化现有的系统架构。
43.Postgre SQL和PostGIS。
44.DevOps,开发人员和平台工程师的工具集合。
docker development youtube series
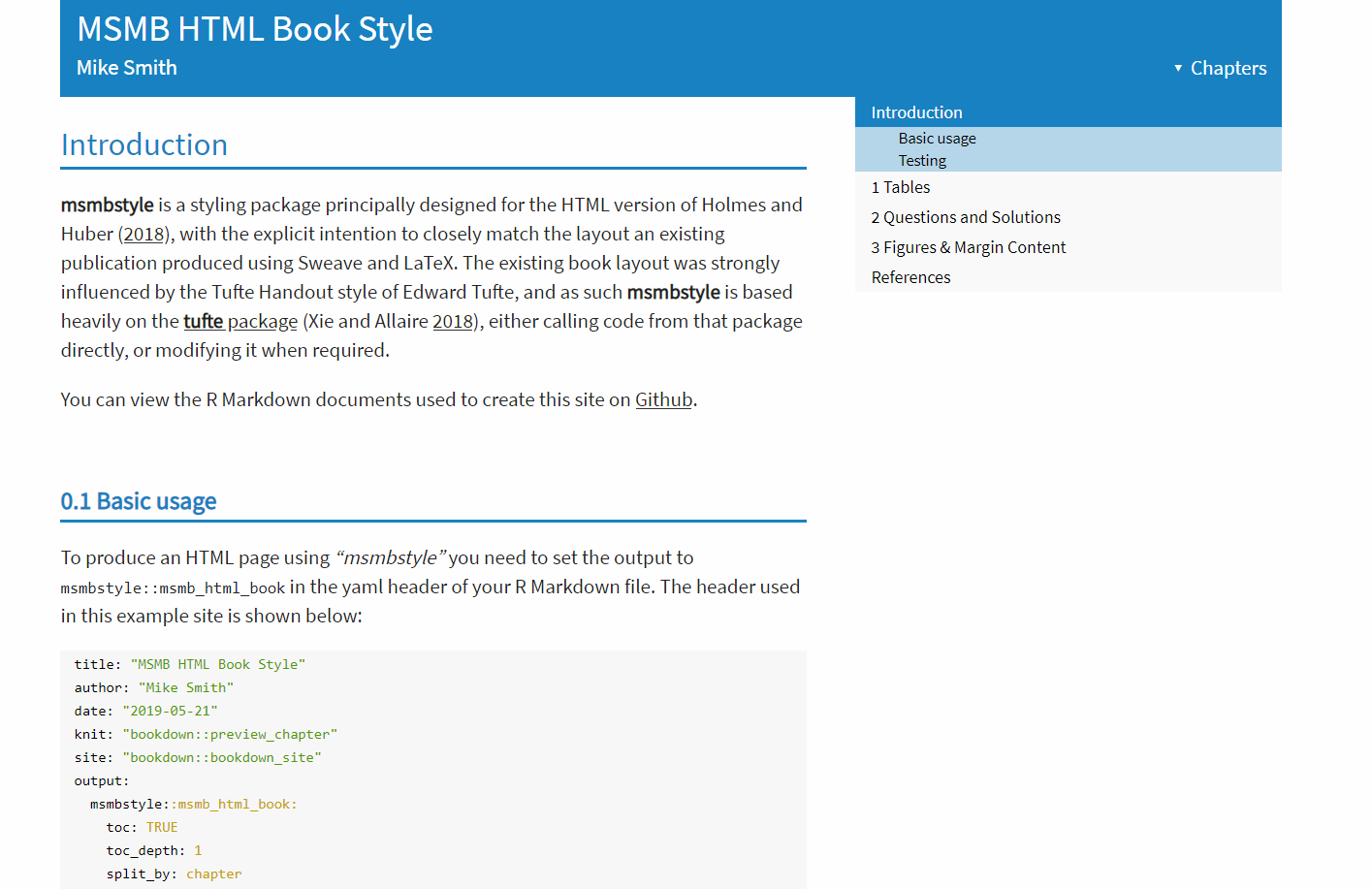
45.R语言包msmbstyle,为使用R包的书籍生成的HTML页面提供了另一种设计。将注释放在页面右边。
46.气候相关的数据集API与开源项目。
47.R语言包slider,提供了一系列通用的“滑动窗口”功能。 该API的目的与purrr非常相似。 这些功能的目标通常是计算滑动平均值,累积总和,滑动回归或其他基于“窗口”的计算。
48.免费R-Tips是Business Science提供的免费新闻通讯。每个星期二提供的代码教程。
49.仿制控制算法中的通用性多任务评估(MAGICAL)。
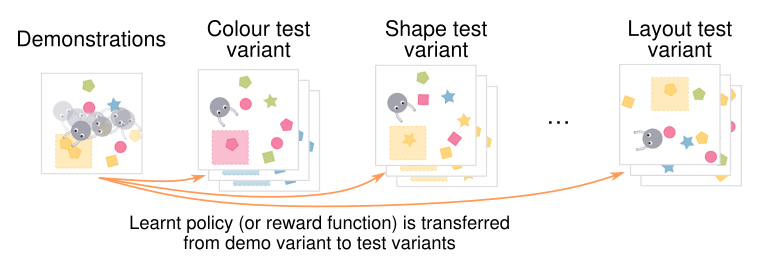
50.PyCRS是一个纯Python GIS软件包,用于在各种通用坐标参考系统(CRS)字符串和数据源格式之间进行读取,写入和转换。
51.Julia的软件包DoctorDocstring,用于诊断软件包中缺少的文档字符串。
52.papermill是用于参数化,执行和分析Jupyter Notebook的工具。

53.将钢琴录音转录成MIDI文件的任务。 高分辨率钢琴转录系统的PyTorch实现。
54.R语言包tmaptools,该软件包提供了一组方便的工具功能,用于读取和处理空间数据。 这些功能的目的是提供工作流程以创建专题图。
55.使用PySimpleGUI开发的数据科学和机器学习GUI程序/桌面应用程序。

56.使用Python、OpenCV、FFmpeg,自动识别电影剪辑、分析剪辑主题颜色。
cut video and generate color with python opencv

57.Sentinel系列卫星SAR影像分析的jupyter notebook样例。
58.rodent小数据集中的缺失值探索。
59.bco app是用于创建,验证和浏览BioCompute对象的Shiny应用程序。

60.使用Golang编写的LAS文件的Cesium.js点云3D切片生成器。
61与Tucker, A.M., C.P. McGowan, E. Mulero, N.F. Angeli, and J.P. Zegarra的论文"A demographic projection model to support conservation decision making for an endangered snake with limited monitoring data(In revision - Animal Conservation)"相关的代码和文件。
62.严重性估算:虚拟实验。
63.微软的人工智能系统课程资源。
64.R语言包agriwater,使用卫星影像和农业气象数据获取能量平衡和实际蒸散量的R软件包。
65.Voilà将Jupyter笔记本变成独立的Web应用程序。
66.IPSQL是可以在IPFS中运行的去中心化数据库。 它实现了SQL模式,数据模型和查询语言。
67.R语言包speed,空间增强和熵导出的邻接矩阵(SpEED-CoMat)。
68.forty是一个多页面网站的hugo主题。 它是HTML5 UP构建的移植主题。该主题包含许多样式元素,并具有联系表单。 专为博客,企业或自由职业者而设计。
69.由克罗姆(Peter Lemon)设计的Game Boy Advance裸机代码。所有代码都可以通过FASMARM汇编器即时进行编译。
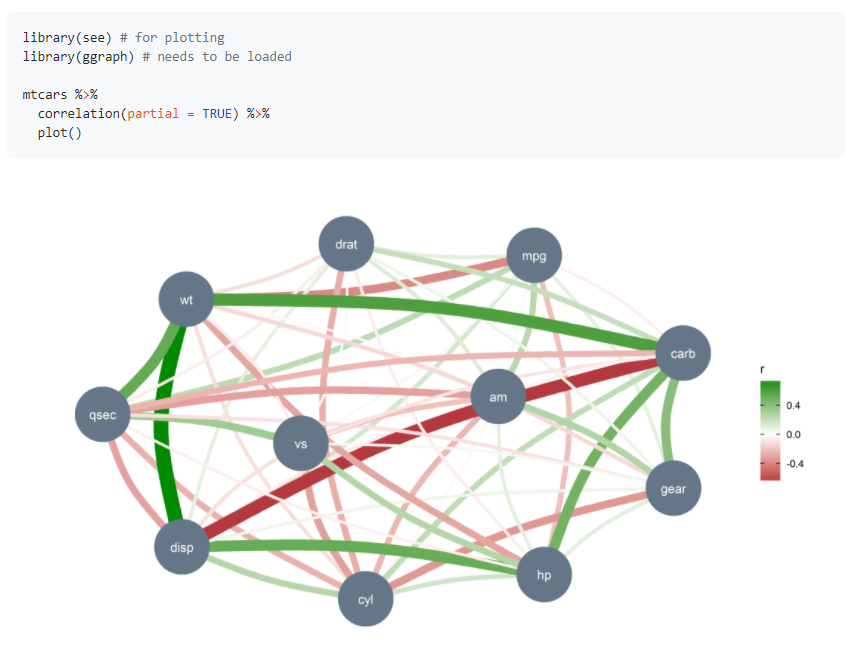
70.R语言包correlation,相关分析的方法包。
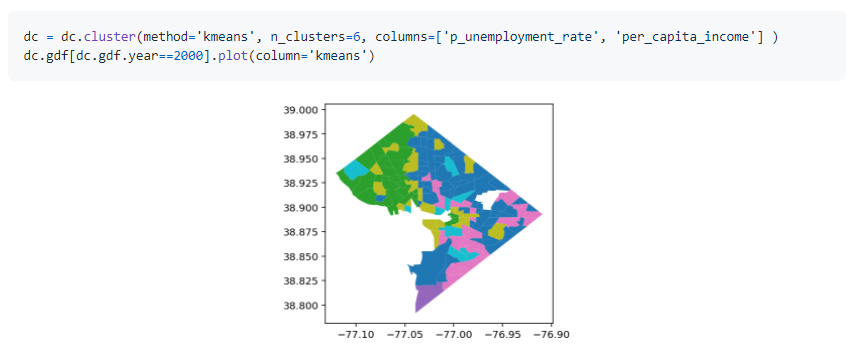
71.Python库geosnap,使探索,建模,分析和可视化社区的社会和空间动态变得更加容易。
72.Python库tobler,用于面插值,等轴测图映射和支持更改。

73.JuliaGeo是一个组织,其中包含许多相关的Julia项目,用于处理,查询和处理地理空间几何数据。 该存储库旨在围绕JuliaGeo组织进行讨论,并列出了一些可用的现有库,以及参与JuliaGeo生态系统的方式(软件包,教材等)。
74.“学习玩混沌游戏:通过区分迭代函数系统来实现分形叶子”的代码。
75.Python库scikit-multilearn,能够执行多标签学习任务。
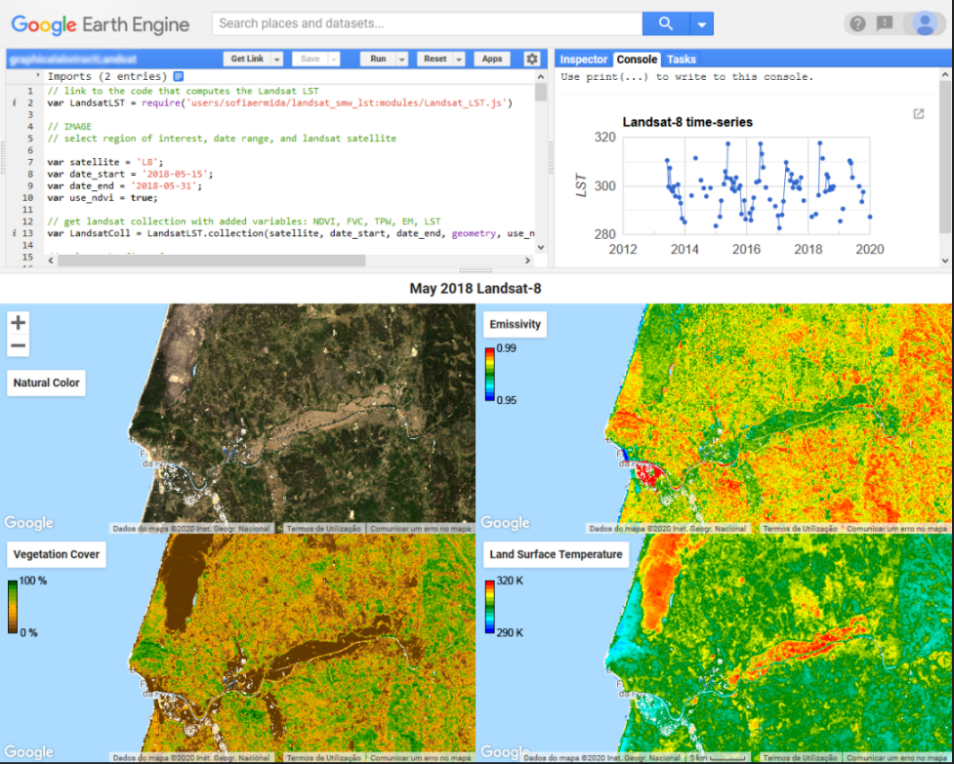
76.Google Earth Engine代码,可通过Landsat系列卫星计算地表温度。Remote Sensing发表文章的代码。
77."An Introduction to Statistical Learning"一书的练习与答案。
An Introduction to Statistical Learning
78.具有重要性加权Actor-Learner架构的可扩展分布式深度强化学习。
79.该数据集16级的Web墨卡托地图瓦片提供了全球固定宽带和移动(蜂窝)网络性能指标。
80.ImplicitGlobalGrid是瑞士国家超级计算中心,苏黎世联邦理工学院(Samuel Omlin博士)与斯坦福大学(LudovicRäss博士)和瑞士地理计算中心(Yuri Podladchikov教授)合作的产物。 它使规则的交错网格上基于模板的GPU和CPU应用程序的分布式并行化几乎变得微不足道,并且使成千上万个GPU上的现实应用程序接近理想的尺度。
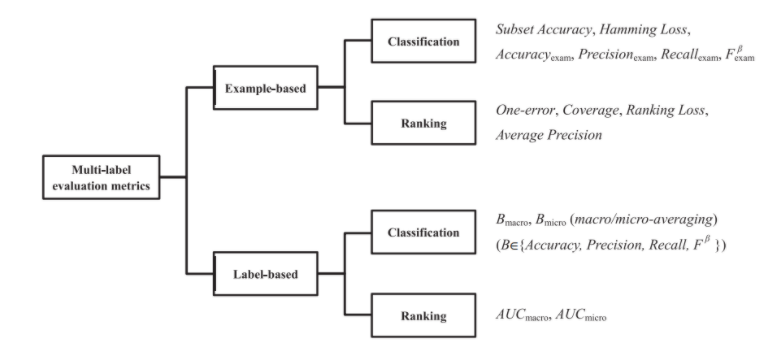
81.多标注模型性能的评估指标。
82.Python库TensorFlow Recommenders,一个使用TensorFlow构建推荐系统模型的库。
83.Python库acme,一个强化学习的研究框架。
84.Python库TF-Agents,使用Tensorflow进行强化学习的库。使实施,部署和测试新的Bandits和强化学习算法更加容易。 它提供了经过测试的模块化组件,可以对其进行修改和扩展。 它具有良好的测试集成和基准测试,可实现快速代码迭代。
85.docker的基础。
86.Reverb是专为机器学习研究而设计的高效且易于使用的数据存储和传输系统。
87.hugo的coder主题。
88.Klever是用于机器学习工作负载的云原生平台。 它可以帮助用户训练,分发,管理和服务其机器学习模型。
89.分布式强化学习代理的实现。
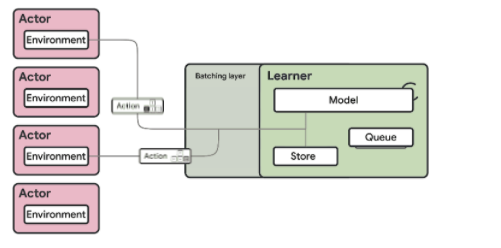
90.基于Ray和Tensorflow的分布式强化学习框架。

91.Linux运行wine应用(QQ/微信/百度网盘/TIM/迅雷极速版/Foxmail等),适用于所有发行版------- Best wine-QQ/TIM/Wechat for all Linux distros。
92.stravalib项目旨在提供一个用于与Strava v3 Web服务进行交互的简单API。
93.有关机器学习和捕捉相机陷阱的所有信息的列表。
94.21世纪的探索性数据分析。
exploratory data analysis in the 21st century
95.Python库gdown,从Google云端硬盘下载大文件(由于安全提示,curl / wget失败)。
96.通过利用Apache MXNet进行动态培训,可以利用AWS云的弹性和规模来降低深度神经网络的培训成本和时间。
dynamic training with apache mxnet on aws
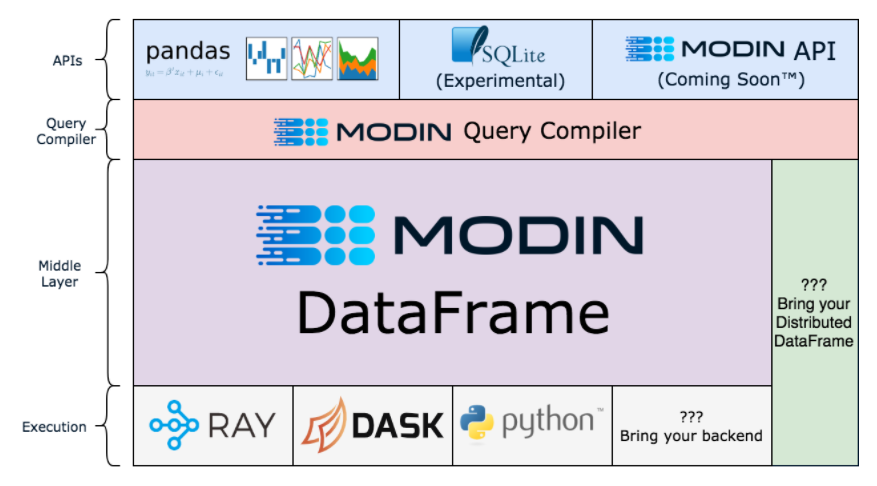
97.Python库modin,通过更改一行代码来加速pandas工作流程。
98.苏格兰NHS(国家健康服务系统)的数据分析专家/商业智能开发者的主页(使用R)。
99.R语言包rdwplus,Peterson&Pearse(2017)的IDW-PLUS的开源实现(IDW-PLUS,溪流土地的反距离加权百分比)。
100.基于dashboard的shiny app,内容是地下水相关。
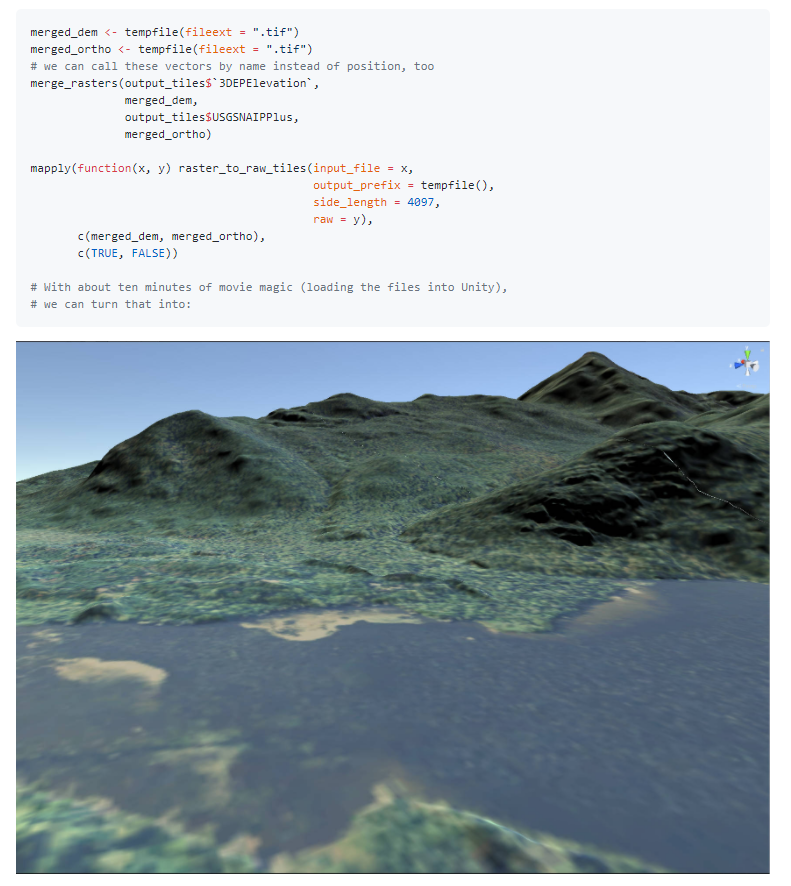
101.R语言包terrainr,从USGS国家地图获取DEM和正射影像,对图像进行地理配准并合并栅格,并对输出进行转换,以便将其导入到Unity中。
102.Python库geocube,将Geopandas矢量数据转换为栅格化xarray数据的工具。
103.IGARSS 2021会议相关材料。
104.来自微软AI for Earth项目,土地覆被制图,前端Web应用程序和后端服务器。

105.通过Excel学习数据挖掘。
Learn Data Mining through Excel
106.Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks论文代码。
107.RStudio的地理数据科学环境docker容器化镜像。
108.R语言包scholar,提供了从Google Scholar中提取引用数据的功能。 除了检索有关单个学者的基本信息之外,该软件包还允许您比较多个学者并预测未来的h指数值。
109.tensorflow源码阅读笔记。
110.PyHSPF包含Fortran水文模拟程序(HSPF)的Python扩展,包括用于收集输入数据,构建输入文件,执行模拟,后处理结果,校准水文过程参数以及预测气候和土地利用变化对水资源的影响的类。要使用HSPF,需要一个河流网络的流线和集水量数据,河流到达子流域的土地利用数据,气候参数的时间序列数据以及每个土地利用类别/子流域的水文参数。可以根据需要在外部提供数据(例如,使用Python扩展程序来处理各种数据类型)或使用PyHSPF的预处理类。
111.Python库atral,计算太阳和月亮的位置。
112.用于软件和Web开发的免费API的汇总列表。
113.R语言包sizzled,可创建需要样本量计算的实验。
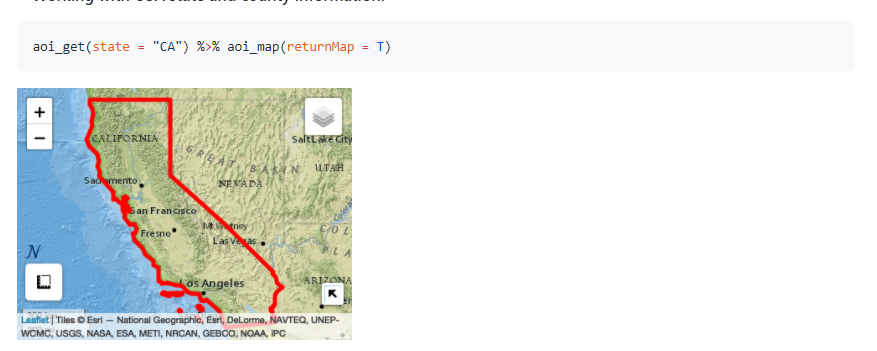
114.R语言包AOI,AOI的目的是帮助人们为分析和制图工作流创建可重现的的边界。
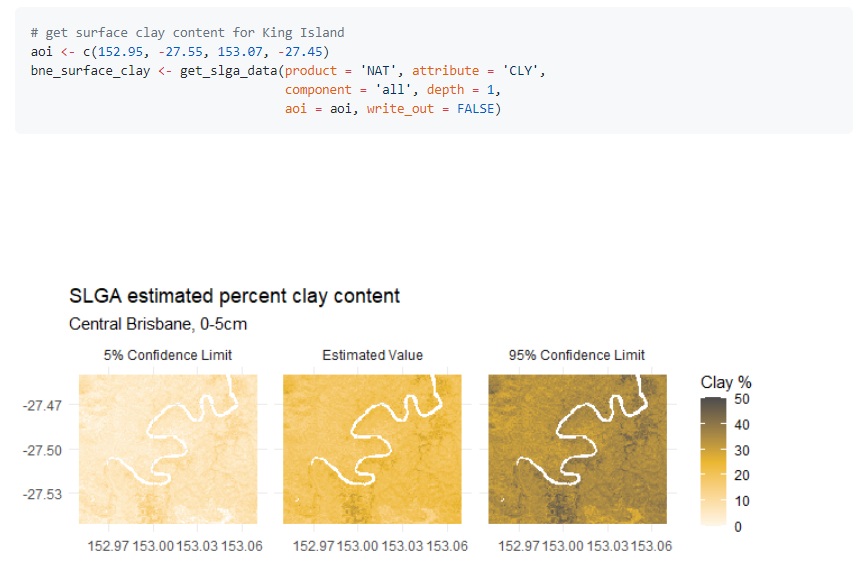
115.R语言包slga,可以从澳大利亚土壤与景观网格下载指定区域的数据。
116.FORCE11软件引证实施工作组。
117.udemy.com的课程The Complete JavaScript Course 2021: From Zero to Expert资料。含课程中所有部分和项目的入门文件和最终代码。
118.使用“ Apache”“ Drill”转换和查询数据的工具。
119.Python库manim,用于数学解释视频的动画引擎。
120.joplin在VSCode中的集成目前允许对目录和注释进行直接操作,同时支持搜索功能。
121.全球湖泊数据库(GLLD)是Python软件包LakePy的后端体系结构。 GLLD在Amazon Web Services(AWS)关系数据库服务(RDS)上托管历史湖泊数据。
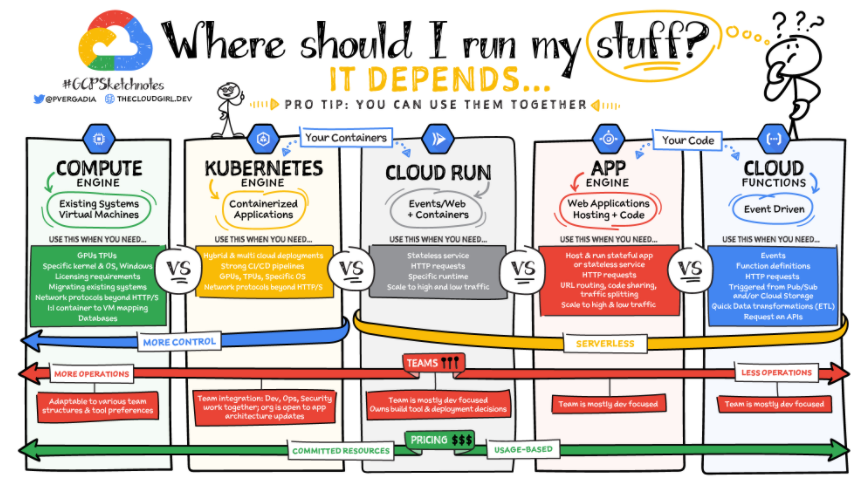
122.Google Cloud Developer的视觉笔记,Google Cloud系列产品中的每个产品都以可视化的草图注释格式描述,以快速,轻松地掌握工具的功能。
123.带有自动完成功能,订阅和GraphiQL的GraphQL的curl。 也是一个简单的通用javascript GraphQL客户端。
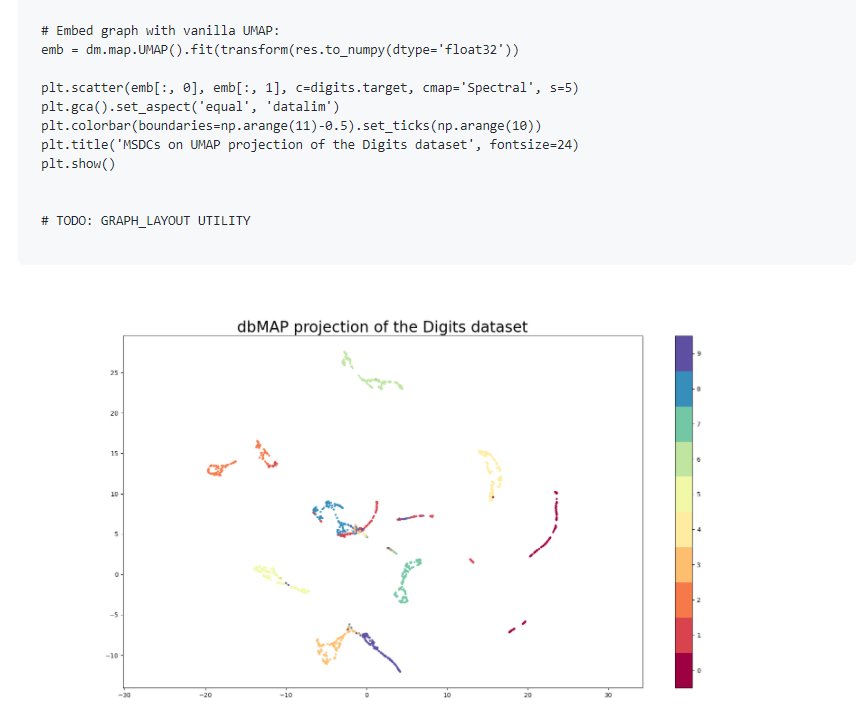
124.Python库nmslib,dbMAP(基于扩散的流形逼近和投影),一个用于运行基于扩散的流形近似和投影(dbMAP)的python模块,这是一种快速,准确和模块化的降维方法。
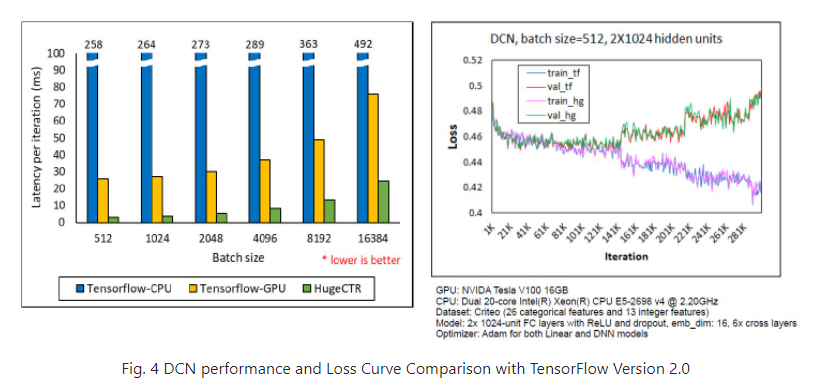
125.HugeCTR是NVIDIA Merlin Open Beta的组件,是GPU加速的推荐程序框架。
126.TensorFlow的性能分析和性能分析工具。
127.一个有趣的shiny小应用程序,灵感来自@nnstats的推文。
128.XNNPACK是针对ARM,WebAssembly和x86平台的高度优化的浮点神经网络推理运算符库。
129.音乐深度学习的资源。
130.如何使用苏格兰NHS网站的API。
131.免费的计算机编程类中文书籍,欢迎投稿。
132.练习旨在反映对可持续性和空间数据科学的看法,并帮助开始使用Python并学习使用课程环境。
133.R语言包polite,基于出色的工具包,用于定义和管理http会话(httr和rvest),声明用户代理字符串和调查站点策略(robotstxt)以及利用速率限制和响应缓存(ratelimitr和备忘录)。
134.Data Science Studio课程的资料。用于分析人群动态。
135.Python库isort,用于按字母顺序对导入进行排序,并自动将其按部分和类型分开。 它为各种编辑器提供了命令行实用程序,Python库和插件,可快速对所有导入进行排序。
136.Python库LakePy,是以用户为中心的Global Lake Level Database的pythonic前端。

137.Python库xoak,Xoak是Xarray扩展,它允许逐点选择以任意数量的维度在坐标中编码的不规则n维数据。
138.滑铁卢大学的CS350(操作系统)课程考试复习笔记。
139.R语言包parallelly,提供增强并行程序包的功能。例如,availableCores()给出R选项和环境变量(包括由作业调度程序在高性能计算(HPC)集群上设置的选项)和环境变量给定的R进程可用的CPU内核数。如果R在’cgroups’或Linux容器下运行,那么它们的设置也会被确认。
140.Carter et al. 2020论文的代码和数据。
temporal island prioritization
141.Python库Opacus,可以使用不同的隐私训练PyTorch模型。 它支持在客户端上进行的代码更改最少的培训,对培训性能的影响很小,并且允许客户端在线跟踪在任何给定时刻花费的隐私预算。
142.Verdaccio是一个简单的,零配置所需的本地私有npm注册表。 无需整个数据库就可以开始! Verdaccio具有自己的小型数据库,并且具有代理其他注册表(例如npmjs.org)的能力,并一路缓存下载的模块。
143.Three.js渲染器,它利用路径跟踪来渲染具有真实照片级逼真的场景。 渲染器支持全局照明,反射,柔和阴影和逼真的环境照明。

144.Python库dalle-pytorch,在Pytorch中实现/复制OpenAI,即OpenAI的文本到图像转换器。 它还将包含CLIP,用于对世代进行排名。
145.LocalStack为开发云应用程序提供了易于使用的测试/模拟框架。
146.用于信用卡审批分析的R Shiny App。
147.Python库alive-progress,一种新型的进度条,具有实时吞吐量,eta和非常酷的动画!
148.Topeka, Kansas的FEV1探索性数据分析。
149.R语言包easystats,旨在提供一个统一和一致的框架来训练,约束和利用R统计信息及模型。
150.使用U-Net架构的Pytorch实施进行道路和建筑物提取。

151.SEVIR天气数据集的挑战和基线模型。SEVIR(用于雷达和卫星气象学中的深度学习应用的Storm事件图像数据集)。
152.R语言包urlchecker,从旧版本的R 4.1中的R 4.1运行URL检查,并根据需要自动更新URL。
2 Paper:
越来越多地研究环境暴露,作为健康行为和疾病后果的可能驱动因素。旨在识别和更好地了解暴露在整个生命过程中对行为和疾病风险的影响的所谓暴露研究需要高质量的环境暴露数据。荷兰拥有各种各样的环境数据,包括有关城市基础设施,物理化学暴露,社区服务的存在和可用性等的高空间分辨率和时空分辨率信息。直到最近,这些环境数据还是在不同的空间尺度上进行分散和测量的,这阻碍了与个人(队列)数据的链接,因为它们尚未作为个人暴露进行操作,即暴露于特定于某个人的环境特征。在地球科学和健康人群联合会(GECCO)中,并在全球地球健康数据中心(GGHDC)的支持下,荷兰建立了一个平台,该平台将环境变量集中化,作为个人暴露进行操作,并用于丰富23个人群研究并应要求提供给研究人员。我们在这里展示并详细介绍了迄今为止GECCO内可用的一系列个人暴露数据集,涵盖了荷兰整个土地上荷兰所有居民(目前约为1700万)的个人暴露,并讨论了挑战和机遇。现在和不久的将来使用它。一项先瞻性的地理环境暴露队列研究,非常重要的一项数据。
对于诸如地图,导航和监视之类的各种应用,市区的语义标记是一项必不可少但具有挑战性的任务。光检测和测距(LiDAR)系统的飞速发展为这项任务提供了使用3D点云的可能解决方案,该点云可访问,负担得起,准确且适用。在所有类型的平台中,具有LiDAR的机载平台可以用作市区大规模3D映射的高效工具。在这种背景下,已经开发了大量算法和方法来充分探索3D点云的潜力。但是,对于评估已开发算法和方法的性能至关重要的,可公开访问的大规模注释数据集的创建仍处于早期阶段。在这项工作中,我们提出了在高密度和复杂的市区中获取的大规模空中LiDAR点云数据集,用于评估语义标记方法。该数据集覆盖了大约1平方千米的高密度建筑物的市区,并包含超过300万个点,并标记了五类对象。此外,利用几种基线方法的结果进行了实验,证明了该数据集作为评估语义标记方法的基准的可行性和能力。慕尼黑工大团队的一套数据集,语义标记的航空LiDAR数据集。
3.Coastal vulnerability to climate change in China’s Bohai Economic Rim/中国环渤海地区沿海地区对气候变化的脆弱性
气候变化和人类活动给城市沿海地区带来了各种各样的压力。对沿海脆弱性的综合评估对于有效的干预措施和长期规划至关重要。但是,很少有基于对城市沿海地区的生态和物理特征以及社会经济状况进行综合分析的研究。这项研究建立了一个整体框架,从生物物理暴露,敏感性和适应能力三个方面评估沿海脆弱性,并将其应用于中国广阔而重要的开发区环渤海经济圈。针对总5627公里海岸线中的每1 km2段,开发了一个综合脆弱性指数(CVI),并通过绘制当前和未来气候变化情景下CVI的分布模式,确定了最容易造成沿海灾害的地区。 CVI显示出空间异质性,较高的值集中在西南和东北海岸,而较低的值集中在南部海岸。目前,约有35万人的海岸线中有20%极易受到沿海灾害的影响。在2100年的未来情景中,随着海平面上升,更多的海岸线将变得高度脆弱,受高度威胁的人口数量估计将增加13-24%。在沿海城市中,东营被归类为脆弱性最高的国家,这主要是由于交通和医疗服务差以及人均GDP低,这导致适应能力低下。我们的结果可通过突出优先领域并确定优先级的最重要决定因素,促进针对气候变化适应和可持续沿海管理的针对特定地点的干预措施而使决策者受益。欧阳志云老师团队的研究,分析海岸带对气候变化的脆弱性。研究的框架值得参考,包括暴露,敏感性和适应能力的综合评估。
正确估计初始状态变量和模型参数对于确定数值模型预测的准确性至关重要。在这项工作中,我们开发了基于集成卡尔曼滤波器和Common Land Model 3.0版(CoLM)的一维土地数据同化方案。该方案用于改善土壤温度剖面的估算。叶面积指数(LAI)也由MODIS LAI生产动态更新,并且MODIS地表温度(LST)产品被吸收到CoLM中。在2002年10月1日至2003年9月30日期间,通过对CEOP蒙古参考站中的四个自动气象站(BTS,DRS,MGS和DGS)进行观测,对该方案进行了测试和验证。结果表明,数据同化可以改善估计土壤温度剖面约为1K。与模拟相比,BTS和DGS处土壤热通量的同化结果分别约为13 W m-2和DRS和MGS处分别为2 W m-2。此外,将MODIS土地产品同化为地表模型是一种改进地表变量和通量估算的实用而有效的方法。李新老师团队的成果,发表于遥感界top期刊RSE,利用集成卡尔曼滤波和MODIS LST进行数据同化,改进土壤温度估算。结合了通用陆面模型的一个研究。从结论看似乎是把土地产品(分类数据)同化为地表模型,这是比较有意思的点,用分类变量同化数值变量。
激光雷达的出现彻底改变了我们从地面和地面上观察和测量植被结构的方式,代表了对3D生态观察定量化的重大进步。激光雷达硬件系统和数据处理算法的发展极大地改善了激光雷达观测在生态研究中的可访问性和易用性。广泛的研究致力于精确地测量和建模激光雷达数据中的植被结构和功能属性,这些数据来自一系列空间尺度(从单个器官到全球尺度)和生态系统类型(例如,森林,农业,草地和城市生态系统) )。随着激光雷达技术和应用的发展,人们越来越认识到研究3D生态系统结构的重要性。研究表明,激光雷达观测可以有效地用于校准和改善生态模型,并产生更详细,更准确的结果,带来了新的生态学见识,对我们现有的知识提出了挑战。尽管如此,我们认为将3D激光雷达观测纳入生态模型仍处于起步阶段,并且尚未充分探索将3D激光雷达观测与多源遥感数据融合以促进对生态过程的新认识的潜力。 3D生态观测的获取应继续拥抱多维大遥感数据时代,带来新的挑战和机遇。通过数据融合探索多时相和多平台遥感数据的潜力,将使下一代生态模型受益。郭庆华老师团队的成果,一篇综述关于LiDAR在3D生态观测与建模中的应用与潜力。适合对LiDAR与生态遥感的同学研读,从而快速了解该领域的发展与现状。发表于遥感界当前IF最高的top期刊IEEE Geoscience and Remote Sensing Magazine 。
背景:短期暴露于PM2.5已与人类发病率和死亡率广泛相关。但是,大多数最新研究都是在每天的时间范围内进行的,而忽略了暴露和结果的日内变化。作为PM2.5中的重要组成部分,尚未对PM1在几个小时内的非常严重的影响进行过研究。方法:2015-2016年,从中国广州收集了针对特定规模的PM(即PM1,PM2.5和PM10),全因急诊室(ED)的就诊和气象因素的每小时数据。进行了时间分层的病例交叉设计,并进行了条件逻辑回归分析,以评估特定大小的PM和ED访视之间的每小时关联,并调整了每小时平均温度和相对湿度。进行了按年龄,性别和季节分层的亚组分析,以确定潜在的影响因素。结果:总共包括292,743例急诊就诊。特定尺寸颗粒物的影响表现出高度相似的滞后模式,其中估计的比值比(OR)从滞后0–3到4–6 h略有上升,随后随着滞后时间的延长而衰减为零。与PM2.5和PM10相比,PM1对急诊就诊的影响略大。例如,在滞后0–3小时,急诊就诊次数增加了1.49%(95%置信区间:1.18-1.79%),1.39%(1.12-1.66%)和1.18%(0.97-1.40%),与10- PM1,PM2.5和PM10分别升高μg/ m3。我们已经发现,随着季节的变化,效果显着变化,与寒冷月份(1.010,1.005至1.015)相比,在寒冷月份(1.017,1.013至1.021),与PM1相关的OR值更大。结论:我们的研究提供了关于PM1暴露在几个小时内对人体健康的不利影响的全新证据。在寒冷的月份,与PM相关的作用明显更强。这些发现可能有助于卫生政策制定者建立每小时的空气质量标准并优化紧急医疗资源的分配。PM1对急诊就诊的影响,PM1是当前还不那么受重视的大气污染物。但是不能忽视的是它对健康的影响,这样子的污染暴露研究是非常具有前瞻性的。
植物表型学是将植物基因组学与环境研究联系起来的新途径,从而改善了植物育种和管理。遥感技术改善了高通量植物的表型。但是,三维(3D)表型的准确性,效率和适用性仍然具有挑战性,尤其是在现场环境中。随着设施和算法的快速发展,光检测和测距(激光雷达)为3D表型提供了强大的新工具。在农业中,已经进行了许多努力来研究使用激光雷达的结构和功能表型的静态和动态变化。这些进展还改善了跨不同时空尺度和学科的3D植物建模,提供了与基因的关联和环境实践分析的更轻松,更便宜的方法,并为育种和管理提供了新见识。除了农业表型以外,激光雷达在林业,园艺和草类表型方面也显示出巨大的潜力。尽管激光雷达在植物表型和建模方面已取得了显着的进步,但基于激光雷达的表型在育种和管理中的综合应用尚未得到充分探索。我们确定了基于激光雷达的表型开发中的三个主要挑战:1)开发低成本,高时空和高光谱激光雷达设施,2)进入多维表型并努力生成新的算法和模型,以及3)拥抱开源和大数据。郭庆华老师组的成果,发表于遥感top期刊ISPRS摄影测量与遥感上。关于LiDAR应用在植物表型学上的优势,进展和前景。感兴趣的同学可以阅读从而快速入门该领域。
我们构建了近实时的每日CO2排放数据集,即Carbon Monitor,以监测自2019年1月1日以来国家层面的化石燃料燃烧和水泥生产所产生的CO2排放变化,每日覆盖近乎全球基础和经常更新的潜力。每天的二氧化碳排放量是根据各种各样的活动数据估算得出的,其中包括31个国家/地区的每小时到每天的发电数据,62个国家/地区的月度生产数据和行业过程的生产指数以及该州的每日流动性数据和流动性指数。全球416个城市的地面运输。各个飞行位置数据和月度数据用于航空和海上运输部门的估算。此外,还使用针对206个国家/地区的每日气温进行校正的月度燃料消耗数据来估算商业和住宅建筑的排放量。这个碳监测器数据集通过受工作日和节假日以及COVID-19大流行的不断发展影响的每日,每周和季节性变化来显示CO2排放的动态性质。 Carbon Monitor近实时CO2排放数据集显示,与2019年同期相比,2020年1月1日至6月30日全球CO2排放量下降了8.8%,并在4月下旬检测到CO2排放量的回升,主要是这归因于中国经济活动的复苏以及其他国家/地区部分禁售的放松。每日更新的二氧化碳排放数据集可以为相关科学研究和政策制定提供一系列机会。清华大学刘竹老师团队开发的近实时每日CO2排放数据集。有对应的一篇NC论文,感兴趣的可以看,本篇论文主要描述数据。
人们越来越意识到城市的绿色空间对居民的健康有益。尽管大量研究集中在绿地数量上,但对绿地质量的关注却很少。现有的评估绿地质量的方法要么是劳动密集型的,要么是费时的。这项研究开发了一种新的机器学习方法,可基于从中国广州收集的街景图像来评估绿地质量。它还检查了绿地暴露差异是否与邻里社会经济地位(SES)相关。验证过程表明,我们的评分系统在预测训练数据以外的基于街景的绿地质量方面达到了很高的准确性。结果还表明,聚集的NDVI(归一化植被指数),街景绿色量和质量之间在空间分布上存在明显差异。回归模型表明,邻域SES与NDVI不相关。尽管邻里SES与街景绿色量和质量指标值都相关,但街景绿色质量对邻里SES的变化更为敏感。我们的工作表明,建议政策制定者和规划者更多地关注城市地区的绿地质量和绿地暴露差异。中山大学刘晔老师团队的研究,利用街景图像评估绿地质量,以及分析绿地暴露差异与社会经济地位的关系,比较新的研究。后续可以与健康数据关联。
背景:青春期男性通常被认为在医疗上不那么容易受害,导致社区保健减少,但是环境意识(准备和知识)对空气污染风险自我预防策略的影响更大。但是,社会环境经验可以改变对环境的主观理解,从而改变他们的环境意识。方法:采用两阶段分析来评估社会环境观念对551名青春期男性的空气污染风险的准备和知识的影响。在第一阶段,我们用高斯回归评估对整体准备和知识的影响,在第二阶段中,我们用二项式回归评估具体的准备和知识。结果:第一阶段分析表明,社会环境观念影响了整体准备,但没有影响整体知识。尤其是,对自己的环境知识了解程度低,会对整体准备产生负面影响,而对于较大的家庭而言,可以感知地对整体准备产生积极影响。第二阶段的分析进一步暗示了感知,准备和知识之间的复杂机制。具体而言,家庭周围的室外空气质量较差,以及对自己的环境了解不足,会对照料家庭成员的具体准备产生不利影响。本身对环境的了解不足,也会对室外空气污染的防范以及对能见度,口罩,心血管疾病和死亡风险的了解产生负面影响。恶劣的室内环境会对戴口罩的准备工作产生负面影响。但是,参加很少的体育活动会对戴口罩的准备工作以及戴口罩,温室气体和对流层臭氧的知识产生负面影响,但对朦胧的日子对户外活动的准备产生积极影响。可以看出,低中学历对对流层臭氧的知识产生了积极影响。父母和大家庭对环境的了解不足,也对特定的准备产生了积极影响。家里室内空气质量差对死亡风险的认识产生积极影响。结论:由于青春期男性的准备和知识的复杂性,应有针对性地制定进一步的环境和健康行动(例如社区服务,环境教育和健康研讨会),并采取适当的预防策略。一项分析高密度城市里男性社会和环境观念对空气污染风险防范和知识影响的研究,社会经济地位对健康认知影响的研究。
背景:城市温室气体(GHG)排放的量化是应对气候变化的重要任务。包括空间上明确的排放估算在内的排放清单有助于准确跟踪排放变化,识别排放源以及制定减缓气候变化的政策。当前许多可用的网格化排放估算是基于国家或州范围内排放估算的分类,这可能有助于描述城市范围内的排放,但在跟踪国家以下各级的变化方面价值有限。因此,应该采用真正的自下而上的方法对城市温室气体排放进行量化。结果:得出了来自日本东京都的化石燃料二氧化碳(FFCO2)排放的多分辨率,空间显式估计。收集了点(例如发电厂和废物焚化炉),线路(主要是交通)和区域(例如住宅和商业区)源的空间明确的排放数据。排放是根据为源位置计算的排放率绘制的。将活动,排放和空间数据进行了整合,并使用地理信息系统方法将结果可视化。结论:2014年东京都的FFCO2年度总排放量为43916 Gg CO2,其中道路运输部门(16323 Gg CO2)占总量的37.2%。通过与日本东亚空气污染物排放网格数据库(EAGrid-Japan)和人为CO2开源数据清单(ODIAC)进行比较,验证了空间排放模式,这证明了该方法在整个国家其他地区的适用性。高分辨率空间显示估计化石燃二氧化碳排放。基于点线面三者结合的空间排放清单编制。
在全球范围内,城市一直是温室气体(GHG)排放的主要来源,因此在减少二氧化碳排放的努力中发挥着越来越重要的作用。但是,由于缺乏或与能源相关的统计数据质量较低,尤其是对一些欠发达地区而言,量化城市一级的CO2排放通常是一项艰巨的任务。为了解决这个问题,本研究使用了一组开放访问数据和机器学习方法来估计和预测中国整个城市的二氧化碳排放量。递归特征消除和Boruta等两种特征选择技术用于提取重要的关键变量和输入参数,以模拟CO2排放。最后,从31个预测变量中选择18个来建立CO2排放的预测模型。我们发现,城市环境污染的统计指标(如工业SO2和人均粉尘排放量)是预测中国城市水平CO2排放的最重要变量。与其他方法相比,XGBoost模型的估计精度最高,R2 R> 0.98,相对误差较低(约0.8%)。通过组合地理空间和气象插值预测变量(例如DEM,年平均降水量和气温),可以适度提高CO2排放预测精度。当其余变量保持不变时,我们还观察到城市人均二氧化碳排放量与城市经济增长之间呈S型关系,而不是U型。本文提供的发现提供了概念的第一个证明,即在城市地区容易获得的社会经济统计记录和地理空间数据具有借助机器学习算法准确预测城市水平CO2排放的潜力。我们的方法可用于为欠发达地区频繁生成碳足迹图,其中缺乏与能源相关的详细统计数据,以协助政策制定者设计减少和分配碳排放量减少目标的具体措施。结合开放获取数据和机器学习构建城市二氧化碳排放制图。值得注意的是这里得出人均碳排放量与经济是S型关系,不是常见的U型。
已经提出将生态系统服务的概念纳入规划和管理实践中,以此作为改善城市生态系统管理的一种方式。然而,由于许多政治和技术障碍,该想法的采用缓慢。技术障碍之一是缺乏用于城市预测拟议政策和行动对城市生态系统服务影响的工具。为了解决这一差距,我们基于社会生态模型框架开发了一种城市生态系统服务模型。以中国北京的PM2.5去除服务为例,我们展示了如何使用此模型来模拟不同政策方案对特定生态系统服务的影响。我们的模拟结果表明,该城市生态系统贡献的PM2.5去除服务可以帮助降低其社会系统中的PM2.5排放,从而形成了积极的反馈。在2016年至2035年期间,北京城市绿地提供的PM2.5清除服务在三种政策方案中有很大不同,包括照常营业,限制城市增长和调整能源结构。根据PM2.5清除服务的预测,我们得出结论,北京应优先考虑通过城市规划限制城市增长的政策。我们的研究表明,从长远来看,生态系统服务的反馈效应非常重要。此外,本研究开发的模型提供了一个有用的工具,可以模拟城市规划和管理对城市生态系统服务的影响。清华大学杨军老师团队的成果,将社会生态模型应用到了生态系统服务当中,去分析PM2.5去除服务的影响。非常有意思的一篇论文,代码也已开源,更详细的内容可以参见杨军老师团队微信公众号推送文章。
鉴于大部分人暴露在城市的PM2.5中都是在室内进行的,因此降低室内PM2.5的水平可能提供一种更可行,更直接的方法,以挽救因PM2.5暴露而造成的大量生命和经济损失。我们旨在评估与实现新建立的中国室内空气指南和一些假设的室内PM2.5指南值相关的过早死亡率和经济损失的减少。我们使用2015年中国339个城市的1497个监测点的室外PM2.5浓度,结合稳态质量平衡模型,估算了室外渗透PM2.5的室内浓度。使用针对城市居民的省份特定时间活动模式,我们估算了室外和室内暴露于室外PM2.5的情况。然后,我们继续使用基于人口普查的局部浓度响应模型和统计寿命估计值来计算整个中国城市PM2.5暴露引起的过早死亡和经济损失。最后,我们通过满足当前基于24小时的准则以及各种假设的室内PM2.5限值,估计了可避免的死亡率和相应的经济损失。 2015年,在中国大陆城市地区,城市特定的室外和室内PM2.5年度平均浓度分别为9-108μg/ m3和5-56μg/ m3。室内暴露每天占总时间加权暴露的62%–91%,每年68%–83%。在每日室内浓度达到当前准则75μg/ m3、37.5μg/ m3和25μg/ m3的情况下,总死亡人数和经济损失的潜在减少量为16.9(95%CI:0.7-62.1)千,分别为87.7(95%CI:9.7–197.7)千和165.5(95%CI:30.8–304.0)千。相应减少的经济损失分别为5.7(95%CI:0.2-34.8)十亿美元,29.4(95%CI:2.4-109.6)十亿美元和55.2(95%CI:7.7-168.0)十亿美元。对于假定的室内PM2.5限值,死亡和经济损失将在0–75μg/ m3范围内成倍减少。研究结果表明,降低室内源自室外的PM2.5浓度在挽救中国大量生命和经济损失方面是有效的。该分析提供了定量证据,以支持实施室内空气质量指南或PM2.5。非常有意思的环境健康研究,结合居民时空行为模式和室外室内PM2.5暴露的死亡和经济损失。同时考虑室内室外的一个非常全面的空气污染暴露研究。
15.Mapping routine measles vaccination in low- and middle-income countries/绘制低收入和中等收入国家的常规麻疹疫苗图
自1974年以来,全球一直在推荐使用安全,高效的麻疹疫苗,但在2017年,五岁以下儿童中有超过1,700万例麻疹病例和83,400例死亡,其中超过99%的病例发生在中低等收入国家(LMIC)1,2,3,4。对于常规的首剂含麻疹疫苗(MCV1)覆盖率而言,全球可比性,年度和本地估计对于了解地理精确的免疫模式,朝着实现全球疫苗行动计划(GVAP)的目标以及在干扰中处于高风险地区至关重要接受由冠状病毒病2019(COVID-19)引起的疫苗接种计划5,6,7,8。在这里,我们对101个中低收入国家从2000年至2019年的5×5 km2像素和第二行政级别的常规儿童期MCV1覆盖率进行了年度估算,量化了地理不平等并通过地理偏远性评估了疫苗接种状况。在从2000年到2010年获得MCV1广泛普及之后,2010年至2019年之间,一半以上的地区覆盖率下降,使得许多中低收入和中等收入国家远离GVAP目标,即到2019年所有地区覆盖率达到80%。农村地区的MCV1覆盖率低于城市地区尽管总体上有较大比例的未接种疫苗的儿童生活在城市地区;提供基本疫苗接种服务的策略应针对两种地理环境。这些结果为决策者提供了加强常规MCV1免疫计划并为所有儿童提供公平疾病保护的工具。疫苗覆盖率的疾病负担小组的分析结果,基于多源数据结合地统计模型实现了101个中低收入国家2000-2019年5公里的麻疹疫苗覆盖地图。
16.Spatial and Temporal Analysis of Lung Cancer in Shenzhen, 2008–2018/2008-2018年深圳市肺癌的时空分析
肺癌是中国最常被诊断出的癌症。中国南方地区肺癌的发病趋势和地理分布尚未见报道。本研究探讨了2008年至2018年深圳肺癌发病率的时间趋势和空间分布。肺癌发病率数据是从2008年至2018年在深圳癌症登记系统中登记的人口中获得的。肺癌的标准化发病率使用联接点回归模型进行了分析。 Moran的I方法用于空间自相关分析,并进一步绘制了深圳的空间聚类图。从2008年到2018年,肺癌的平均原始发病率为27.1(1 / 100,000),年百分比变化为2.7%(p <0.05)。组织学类型肺癌的最大平均比例被确定为腺癌(69.1%),女性观察到呈上升趋势,年平均变化率为14.7%。空间自相关分析表明,深圳的一些地点是高发生率的空间聚类区。了解肺癌的发病模式有助于监测和预防。深圳市肺癌的时空分析,结合时空统计模型挖掘疾病流行模式。
建筑物是遥感(RS)图像中最重要的景观之一,并且在从城市规划到其他社会经济研究的广泛应用中得到了广泛的分析。随着超高分辨率(VHR)RS图像变得越来越容易获得,当前的建筑物提取方法面临着复杂场景中各种外观,不同比例和复杂建筑物结构的挑战。随着上下文感知深度学习方法的发展,许多著作已证明捕获上下文信息可以提供空间关系线索,以对对象进行可靠的识别和检测。在本文中,我们提出了一种新颖的本地-全局双流网络(DS-Net),该网络可以自适应地捕获本地和远程信息,以便在VHR RS图像中准确绘制建筑物屋顶。 DS-Net的本地分支和全局分支以互补的方式相互配合,在输入图像上具有不同的视野。通过定义明确的双流体系结构,DS-Net可以学习本地和全球分支机构的分层表示形式,并且进一步开发了深度功能共享策略以强制两个分支机构进行更多的协作集成。进行了广泛的实验以验证我们的模型在三个广泛使用的VHR RS数据集上的有效性:马萨诸塞州建筑物数据集,Inria航空影像标签数据集和DeepGlobe建筑物检测挑战数据集。从经验上讲,在定量测量和视觉评估方面,与当前的最新技术相比,拟议的DS-Net具有竞争性或优越的性能。一个新的神经网络用于VHR遥感图像提取建筑物。武大张良培老师团队的成果。从结果上看,是一个非常不错的神经网络模型。














 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









