










我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的。首先通过这篇文章,你能学到以下几点:
1.可以了解Python简单爬取图片的一些思路和方法
2.学习Selenium自动、测试分析动态网页和正则表达式的区别和共同点
3.了解作者最近学习得比较多的搜索引擎和知识图谱的整体框架
4.同时作者最近找工作,里面的一些杂谈和建议也许对即将成为应届生的你有所帮助
5.当然,最重要的是你也可以尝试使用这个爬虫去爬取自己比较喜欢的图片
总之,希望文章对你有所帮助。如果作者又不足之处或错误的地方,还请海涵~
参考:
[python学习] 简单爬取图片网站图库中图片
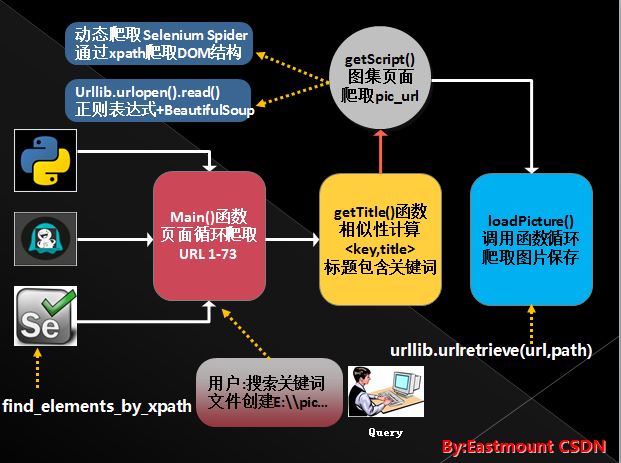
其基本步骤为:
第一步:循环遍历图集列表URL
main()函数中循环输入列表url,并调用getTitle(key,url)判断主题(title)中是否包含输入的关键词(key),如"极品飞车"。
这里因为游讯图库存在第一个BUG,图集共73页,url采用顺序形式存储,每页存在很多主题(title);当然很多网站都是这样的,如CSDN博客、CSDN下载、搜狐博客等。
http://pic.yxdown.com/list/0_0_1.html
http://pic.yxdown.com/list/0_0_73.html
第二步:通过Selenium和Phantomjs寻找路径爬取主题和URL
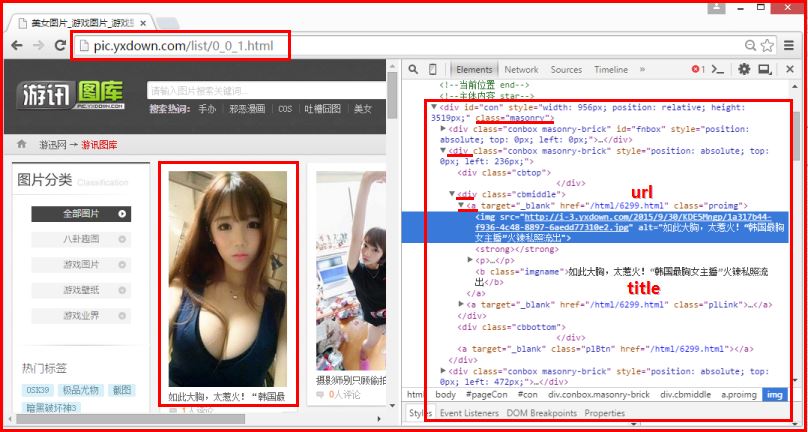
如下图所示,在函数getTitle()中通过selenium访问无界面的浏览器Phantomjs,再遍历HTML的DOM树结构。
 其中核心代码如下:
其中核心代码如下:
driver.find_elements_by_xpath("//div[@class='masonry']/div/div[2]/a")
它是Selenium按照路径定位元素,其中DOM树表示寻找class='masonry'的div,然后是子div,第二个div,最后是<a target='_blank',此处可以爬取主题title.text和属性title.get_attribute("href")。对应源码:
<div class='masonry'>
<div class='conbox'>
<div></div><div class='cbmiddle'> //div[2]
<a target="_blank" href="/html/6299.html" class="proimg"> //URL
<img src="http://yxdown.com/xxx.jpg" alt="...韩国女主播...">
<p><span>1440人看过</span> <em>8张</em></p>
<b class="imgname">...韩国女 主播 ....</b> //主题
</a>
</div>
</div>
<div class= 'conbox'>第二个主题</div>
<div class= 'conbox'>第二个主题</div>
....
</div>
同时获取的href属性 自动补齐,如: http://pic.yxdown.com/html/6299.html
此处的driver.find_elements_by_xpath方法就比传统的正则表达式好,同时它返回一个List。后面第三部分会详细介绍下Selenium常用的方法。在raw_input输入关键字比较过程中如果存在中文乱码问题,参考 这篇文章
第三步:根据主题创建文件夹并去到具体页面爬取图片
通过比较关键词key是否包含在主题title,如"主播"。如果在则创建该文件夹,同时移除同名文件:
if os.path.isfile(path): #Delete file
os.remove(path)
elif os.path.isdir(path): #Delete dir
shutil.rmtree(path,True)
os.makedirs(path) #create the file directory
再调用getScript(elem_url,path)函数去爬取所在页面的图集
第四步:通过正则表达式获取图片url
此时去到具体的图集如: http://pic.yxdown.com/html/5533.html#p=1
你有两种方法获取图片,第一种方法是通过Selenium模拟鼠标操作,点击"查看原图"再另存为图片或者获取源码<img src="http://xxx.jpg">属性,再或者是获取"查看原图"的当前url,driver.current_url。
<a href="javascript:;" οnclick="return false;" id="Original">查看原图</a>
第二种方法是由于游讯图库的第二个bug,它把所有图片都保存在<script></script>,则通过urllib2获取原图original即可。
res_original = r'"original":"(.*?)"' #原图
m_original = re.findall(res_original,script)
第五步:最后调用函数loadPicture(pic_url, pic_path)下载图片即可
讲到此处,整个爬虫基本讲述完毕。使用Selenium的优点主要是:DOM树结构爬取,可能Spider也是采用find_element_by_xpath()方法,都是类似的;第二个优点是获取动态JS、AJax的资源或文件。但是正则表达式也有它的好处和方便。
前面我为什么画了一副框架图,主要是最近研究搜索引擎和知识图谱比较多,所以这幅图给人更直观的感觉。第二部分会详细说到。
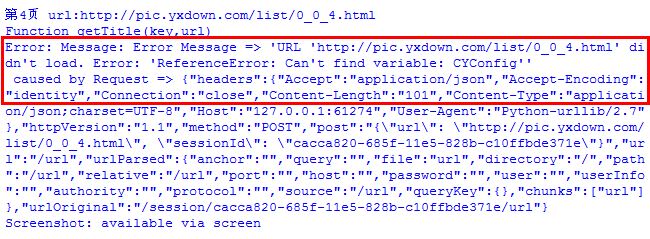
同时,你可能会遇到如下错误,可能和加载响应有关:
 搜索引擎的通常是用户输入查询词,搜索引擎返回搜索结果。主要包括流程是:
搜索引擎的通常是用户输入查询词,搜索引擎返回搜索结果。主要包括流程是:
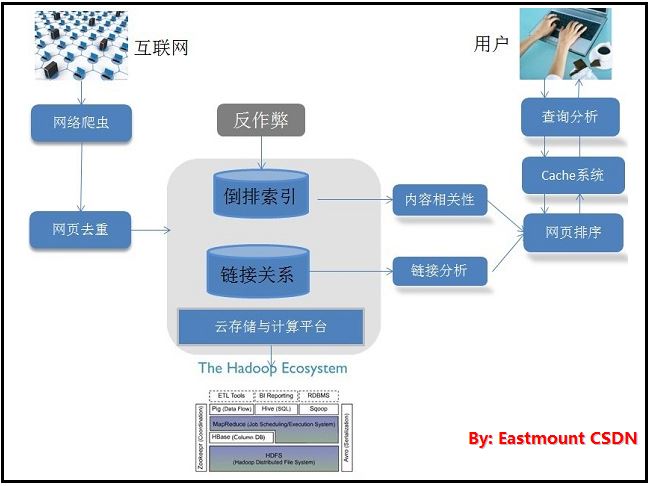
搜索引擎后台计算系统
搜索引擎的信息来源于互联网网页,通过网络爬虫将整个互联网的信息获取到本地,因此互联网页面中有很大部分内容是相同或相似的,“网页去重”模块会对此作出检测并去除重复内容。
之后,搜索引擎会对网页进行解析,抽取出网页主体内容及页面中包含的指向其他页面的链接。为加快响应用户查询的速度,网页内容通过“倒排索引”这种高效查询数据结构保存,网页之间的链接关系也会保存。因为通过“链接分析”可以判断页面的相对重要性,对于为用户提供准确的搜索结果帮助很大。
同时由于海量数据信息巨大,所以采用云存储与云计算平台作为搜索引擎及相关应用的基础支撑。上述是关于搜索引擎如何获取及存储海量的网页相关信息,不需要进行实时计算,所以被看做是搜索引擎的后台计算系统。
搜索引擎前台计算系统
搜索引擎的最重要目的是为用户提供准确全面的搜索结果,如何响应用户查询并实时地提供准确结果构成了搜索引擎前台计算系统。
当搜索引擎接到用户的查询词后,首先对查询词进行分析,希望能够结合查询词和用户信息来正确推导用户的真正搜索意图。先在缓存中查找,缓存系统中存储了不同的查询意图对应的搜索结果,如果能在缓存中找到满足用户需求的信息,则直接返回给用户,即节省资源又加快响应速度。如果缓存中不存在,则调用“网页排序”模块功能。
“网页排序”会根据用户的查询实时计算哪些网页是满足用户信息需求的,并排序输出作为搜索结果。而网页排序中最重要的两个因素是:内容相似性因素(哪些网页和用户查询相关)和网页的重要性因素(哪些网页质量好或相对重要,通过链接分析结果获得)。然后网页进行排序,作为用户查询的搜索结果。
同时,搜索引擎的“反作弊”模块主要自动发现那些通过各种手段将网页的搜索排名提高到与其网页质量不相称的位置,这会严重影响搜索体验。现在也出现一种成功的新互联网公司屏蔽搜索引擎公司爬虫的现象,比如Facebook对Google的屏蔽,国内淘宝对百度的屏蔽,主要是商业公司之间的竞争策略,也可看做是垂直搜索和通用搜索的竞争。
2.知识图谱
这是搜狗知立方知识图谱的框架图。详见:文章
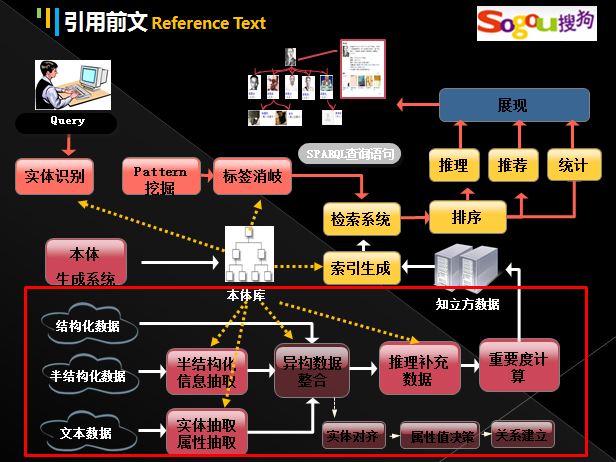 知识图谱(Knowledge Graph)于2012年5月首先由Google提出,其目标在于描述真实世界中存在的各种实体和概念,及实体、概念之间的关联关系,从而改善搜索结果。紧随其后,国内搜狗提出了“知立方”、微软的Probase和百度的“知心”。其实质就是真正让计算机去"理解"用户的需求和搜索意图。
知识图谱(Knowledge Graph)于2012年5月首先由Google提出,其目标在于描述真实世界中存在的各种实体和概念,及实体、概念之间的关联关系,从而改善搜索结果。紧随其后,国内搜狗提出了“知立方”、微软的Probase和百度的“知心”。其实质就是真正让计算机去"理解"用户的需求和搜索意图。
知立方数据库构建包括本体构建(各类型实体挖掘、属性名称挖掘、编辑系统)、实例构建(纯文本属性、实体抽取、半结构化数据抽取)、异构数据整合(实体对齐、属性值决策、关系建立)、实体重要度计算、推理完善数据。
3.爬虫框架猜想
说了这么多,你是不是还不知道我想表达什么内容啊?
我在设想如果上面那个Python图片爬虫添加以下几点:
(1)图片来源不是定向的某个网站,而是开放的网络、图库、数据库
(2)搜索中加入一些更复杂的搜索,利用一些NLP分词技术处理
(3)通过一些相似计算,采用更高效的VSM、聚类、神经网络、人脸识别等,计算关键词和图片或标题的相似度,甚至实现百度图片那种识别某张图是某某明星
(4)再建立倒排索引、链接分析加快检索系统
(5)海量图片利用云计算、云存储的支持,采用分布式并行更高效的操作
(6)实现图片智能识别、图片相关推荐,再根据不同用户的log分析用户的真正搜索意图
通过以上几点是不是能实现一个智能的图片知识计算引擎呢?谷歌、百度图片那些智能应用是不是也是这样的呢?感觉非常有意思啊!
PS:以后有机会自己研究研究,并且自己再写一些更强大的智能爬取吧!
定位username元素的方法如下:
[1] 第一个form元素通过一个input子元素,name属性和值为username实现
[2] 通过id=loginForm值的form元素找到第一个input子元素
[3] 属性名为name且值为username的第一个input元素
2.driver接口获取值
通过WebElement接口可以获取常用的值,这些值同样非常重要。
安装过程:http://blog.csdn.net/eastmount/article/details/47785123
1.可以了解Python简单爬取图片的一些思路和方法
2.学习Selenium自动、测试分析动态网页和正则表达式的区别和共同点
3.了解作者最近学习得比较多的搜索引擎和知识图谱的整体框架
4.同时作者最近找工作,里面的一些杂谈和建议也许对即将成为应届生的你有所帮助
5.当然,最重要的是你也可以尝试使用这个爬虫去爬取自己比较喜欢的图片
总之,希望文章对你有所帮助。如果作者又不足之处或错误的地方,还请海涵~
一. Python定向爬取海量图片
运行效果如下图所示:
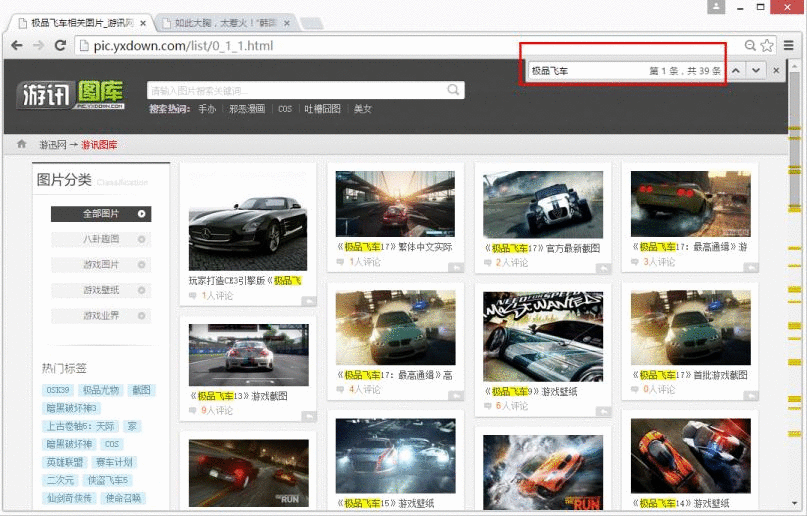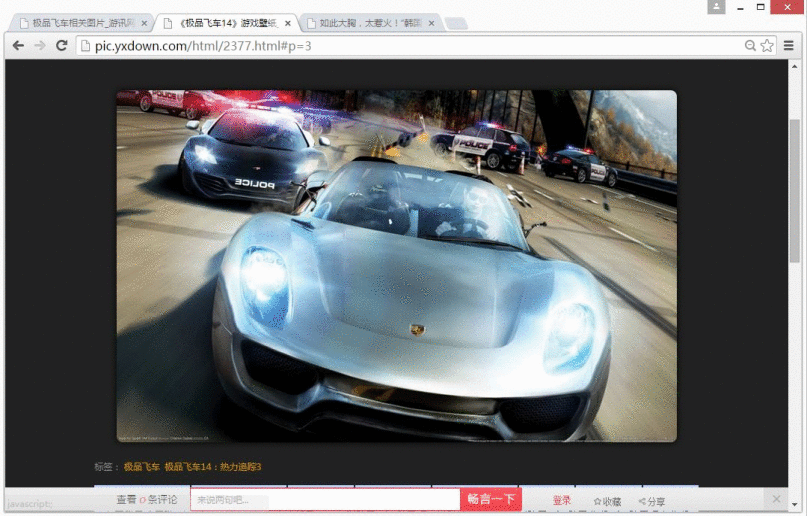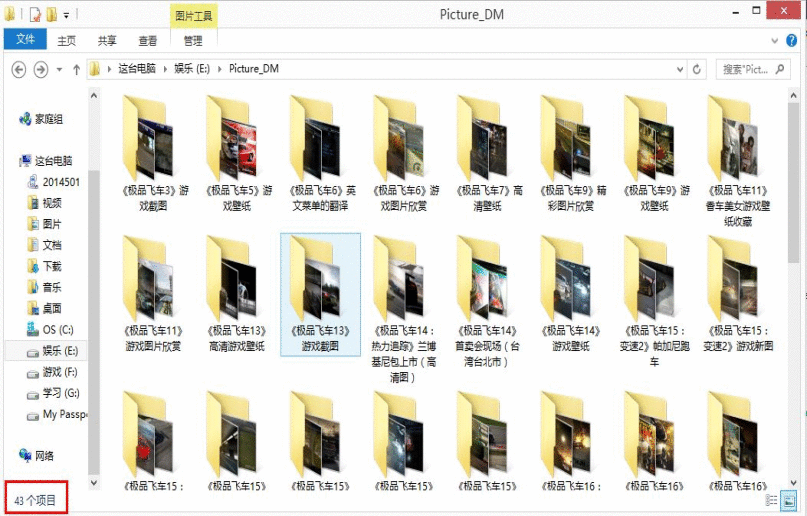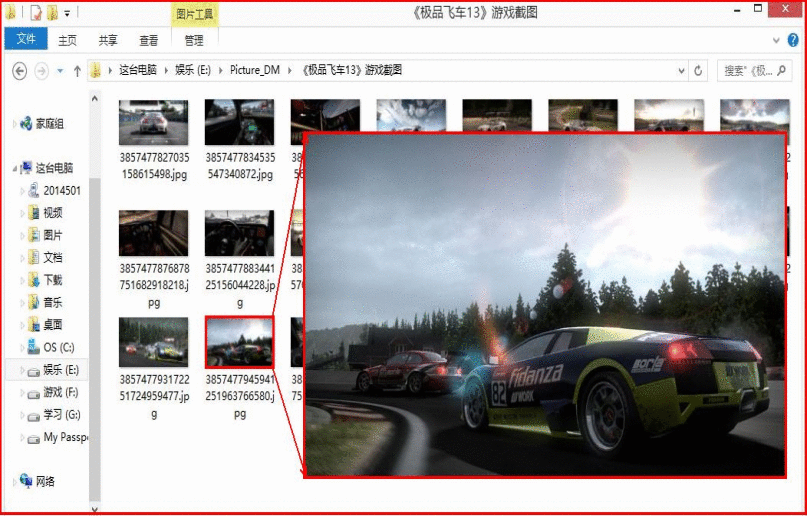
这是从游讯图库中爬取图片(非常不错的网站,推荐大家去浏览),其它网站方法类似去修改。运行py文件后,输入“极品飞车”可以爬取主题相关的图集。
程序源代码如下图所示:
# -*- coding: utf-8 -*-
"""
Crawling pictures by selenium and urllib
url: http://pic.yxdown.com/list/0_0_1.html
Created on 2015-10-02 @author: Eastmount CSDN
"""
import time
import re
import os
import sys
import urllib
import shutil
import datetime
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#Open PhantomJS
driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
#driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#Download one Picture
def loadPicture(pic_url, pic_path):
pic_name = os.path.basename(pic_url) #delete path, get the filename
urllib.urlretrieve(pic_url, pic_path + pic_name)
#Visit the picture page and get <script>(.*?)</script> original
def getScript(elem_url,path):
print elem_url
print path
'''
#Error: Message: Error Message => 'Element does not exist in cache'
driver.get(elem_url)
pic_url = driver.find_element_by_xpath("//div[@id='wrap']/div/div[2]/a")
print pic_url.text
'''
#By urllib to download the original pics
count = 1
html_content = urllib.urlopen(elem_url).read()
html_script = r'<script>(.*?)</script>'
m_script = re.findall(html_script,html_content,re.S|re.M)
for script in m_script:
res_original = r'"original":"(.*?)"' #原图
m_original = re.findall(res_original,script)
for pic_url in m_original:
loadPicture(pic_url, path)
count = count + 1
else:
print 'Download ' + str(count) + ' Pictures'
#Get the Title of the URL
def getTitle(key, url):
try:
#print key,type(key)
count = 0
print 'Function getTitle(key,url)'
driver.get(url)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='masonry']/div/div[2]/a"))
elem_title = driver.find_elements_by_xpath("//div[@class='masonry']/div/div[2]/a")
for title in elem_title:
#title.text-unicode key-str=>unicode
#print key,title.text
elem_url = title.get_attribute("href")
if key in title.text:
#print key,title.text
path="E:\\Picture_DM\\"+title.text+"\\"
if os.path.isfile(path): #Delete file
os.remove(path)
elif os.path.isdir(path): #Delete dir
shutil.rmtree(path,True)
os.makedirs(path) #create the file directory
count = count + 1
#print elem_url
getScript(elem_url,path) #visit pages
except Exception,e:
print 'Error:',e
finally:
print 'Find ' + str(count) + ' pages with key\n'
#Enter Function
def main():
#Create Folder
basePathDirectory = "E:\\Picture_DM"
if not os.path.exists(basePathDirectory):
os.makedirs(basePathDirectory)
#Input the Key for search str=>unicode=>utf-8
key = raw_input("Please input a key: ").decode(sys.stdin.encoding)
print 'The key is : ' + key
#Set URL List Sum:1-73 Pages
print 'Ready to start the Download!!!\n\n'
starttime = datetime.datetime.now()
num=1
while num<=73:
url = 'http://pic.yxdown.com/list/0_0_'+str(num)+'.html'
print '第'+str(num)+'页','url:'+url
#Determine whether the title contains key
getTitle(key,url)
time.sleep(2)
num = num + 1
else:
print 'Download Over!!!'
#get the runtime
endtime = datetime.datetime.now()
print 'The Running time : ',(endtime - starttime).seconds
main()第一步:循环遍历图集列表URL
main()函数中循环输入列表url,并调用getTitle(key,url)判断主题(title)中是否包含输入的关键词(key),如"极品飞车"。
这里因为游讯图库存在第一个BUG,图集共73页,url采用顺序形式存储,每页存在很多主题(title);当然很多网站都是这样的,如CSDN博客、CSDN下载、搜狐博客等。
http://pic.yxdown.com/list/0_0_1.html
http://pic.yxdown.com/list/0_0_73.html
第二步:通过Selenium和Phantomjs寻找路径爬取主题和URL
如下图所示,在函数getTitle()中通过selenium访问无界面的浏览器Phantomjs,再遍历HTML的DOM树结构。
driver.find_elements_by_xpath("//div[@class='masonry']/div/div[2]/a")
它是Selenium按照路径定位元素,其中DOM树表示寻找class='masonry'的div,然后是子div,第二个div,最后是<a target='_blank',此处可以爬取主题title.text和属性title.get_attribute("href")。对应源码:
<div class='masonry'>
<div class='conbox'>
<div></div><div class='cbmiddle'> //div[2]
<a target="_blank" href="/html/6299.html" class="proimg"> //URL
<img src="http://yxdown.com/xxx.jpg" alt="...韩国女主播...">
<p><span>1440人看过</span> <em>8张</em></p>
<b class="imgname">...韩国女 主播 ....</b> //主题
</a>
</div>
</div>
<div class= 'conbox'>第二个主题</div>
<div class= 'conbox'>第二个主题</div>
....
</div>
同时获取的href属性 自动补齐,如: http://pic.yxdown.com/html/6299.html
此处的driver.find_elements_by_xpath方法就比传统的正则表达式好,同时它返回一个List。后面第三部分会详细介绍下Selenium常用的方法。在raw_input输入关键字比较过程中如果存在中文乱码问题,参考 这篇文章
第三步:根据主题创建文件夹并去到具体页面爬取图片
通过比较关键词key是否包含在主题title,如"主播"。如果在则创建该文件夹,同时移除同名文件:
if os.path.isfile(path): #Delete file
os.remove(path)
elif os.path.isdir(path): #Delete dir
shutil.rmtree(path,True)
os.makedirs(path) #create the file directory
再调用getScript(elem_url,path)函数去爬取所在页面的图集
第四步:通过正则表达式获取图片url
此时去到具体的图集如: http://pic.yxdown.com/html/5533.html#p=1
你有两种方法获取图片,第一种方法是通过Selenium模拟鼠标操作,点击"查看原图"再另存为图片或者获取源码<img src="http://xxx.jpg">属性,再或者是获取"查看原图"的当前url,driver.current_url。
<a href="javascript:;" οnclick="return false;" id="Original">查看原图</a>
第二种方法是由于游讯图库的第二个bug,它把所有图片都保存在<script></script>,则通过urllib2获取原图original即可。
res_original = r'"original":"(.*?)"' #原图
m_original = re.findall(res_original,script)
第五步:最后调用函数loadPicture(pic_url, pic_path)下载图片即可
def loadPicture(pic_url, pic_path):
pic_name = os.path.basename(pic_url)
urllib.urlretrieve(pic_url, pic_path + pic_name)讲到此处,整个爬虫基本讲述完毕。使用Selenium的优点主要是:DOM树结构爬取,可能Spider也是采用find_element_by_xpath()方法,都是类似的;第二个优点是获取动态JS、AJax的资源或文件。但是正则表达式也有它的好处和方便。
前面我为什么画了一副框架图,主要是最近研究搜索引擎和知识图谱比较多,所以这幅图给人更直观的感觉。第二部分会详细说到。
同时,你可能会遇到如下错误,可能和加载响应有关:
二. 搜索引擎和知识图谱杂谈
1.搜索引擎
下面是《这就是搜索引擎·张俊林》里面那张经典的框架图。
搜索引擎后台计算系统
搜索引擎的信息来源于互联网网页,通过网络爬虫将整个互联网的信息获取到本地,因此互联网页面中有很大部分内容是相同或相似的,“网页去重”模块会对此作出检测并去除重复内容。
之后,搜索引擎会对网页进行解析,抽取出网页主体内容及页面中包含的指向其他页面的链接。为加快响应用户查询的速度,网页内容通过“倒排索引”这种高效查询数据结构保存,网页之间的链接关系也会保存。因为通过“链接分析”可以判断页面的相对重要性,对于为用户提供准确的搜索结果帮助很大。
同时由于海量数据信息巨大,所以采用云存储与云计算平台作为搜索引擎及相关应用的基础支撑。上述是关于搜索引擎如何获取及存储海量的网页相关信息,不需要进行实时计算,所以被看做是搜索引擎的后台计算系统。
搜索引擎前台计算系统
搜索引擎的最重要目的是为用户提供准确全面的搜索结果,如何响应用户查询并实时地提供准确结果构成了搜索引擎前台计算系统。
当搜索引擎接到用户的查询词后,首先对查询词进行分析,希望能够结合查询词和用户信息来正确推导用户的真正搜索意图。先在缓存中查找,缓存系统中存储了不同的查询意图对应的搜索结果,如果能在缓存中找到满足用户需求的信息,则直接返回给用户,即节省资源又加快响应速度。如果缓存中不存在,则调用“网页排序”模块功能。
“网页排序”会根据用户的查询实时计算哪些网页是满足用户信息需求的,并排序输出作为搜索结果。而网页排序中最重要的两个因素是:内容相似性因素(哪些网页和用户查询相关)和网页的重要性因素(哪些网页质量好或相对重要,通过链接分析结果获得)。然后网页进行排序,作为用户查询的搜索结果。
同时,搜索引擎的“反作弊”模块主要自动发现那些通过各种手段将网页的搜索排名提高到与其网页质量不相称的位置,这会严重影响搜索体验。现在也出现一种成功的新互联网公司屏蔽搜索引擎公司爬虫的现象,比如Facebook对Google的屏蔽,国内淘宝对百度的屏蔽,主要是商业公司之间的竞争策略,也可看做是垂直搜索和通用搜索的竞争。
2.知识图谱
这是搜狗知立方知识图谱的框架图。详见:文章
知立方数据库构建包括本体构建(各类型实体挖掘、属性名称挖掘、编辑系统)、实例构建(纯文本属性、实体抽取、半结构化数据抽取)、异构数据整合(实体对齐、属性值决策、关系建立)、实体重要度计算、推理完善数据。
3.爬虫框架猜想
说了这么多,你是不是还不知道我想表达什么内容啊?
(1)图片来源不是定向的某个网站,而是开放的网络、图库、数据库
(2)搜索中加入一些更复杂的搜索,利用一些NLP分词技术处理
(3)通过一些相似计算,采用更高效的VSM、聚类、神经网络、人脸识别等,计算关键词和图片或标题的相似度,甚至实现百度图片那种识别某张图是某某明星
(4)再建立倒排索引、链接分析加快检索系统
(5)海量图片利用云计算、云存储的支持,采用分布式并行更高效的操作
(6)实现图片智能识别、图片相关推荐,再根据不同用户的log分析用户的真正搜索意图
通过以上几点是不是能实现一个智能的图片知识计算引擎呢?谷歌、百度图片那些智能应用是不是也是这样的呢?感觉非常有意思啊!
PS:以后有机会自己研究研究,并且自己再写一些更强大的智能爬取吧!
三. Selenium简单基础学习
前面我在Python爬虫这个专题中讲述了很多关于Selenium的文章,包括爬取百度百科InfoBox、配置安装过程等。下面是简单的Selenium定位元素的介绍:
1.定位元素方法
官网地址:http://selenium-python.readthedocs.org/locating-elements.html
这里有各种策略用于定位网页中的元素(locate elements),你可以选择最适合的方案,Selenium提供了一下方法来定义一个页面中的元素:
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
除了上面给出的公共方法,这里也有两个在页面对象定位器有用的私有方法。这两个私有方法是find_element和find_elements。
常用方法是通过xpath相对路径进行定位,同时CSS也是比较好的方法。举例:
- <html>
- <body>
- <form id="loginForm">
- <input name="username" type="text" />
- <input name="password" type="password" />
- <input name="continue" type="submit" value="Login" />
- <input name="continue" type="button" value="Clear" />
- </form>
- </body>
- <html>
- username = driver.find_element_by_xpath("//form[input/@name='username']")
- username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]")
- username = driver.find_element_by_xpath("//input[@name='username']")
[2] 通过id=loginForm值的form元素找到第一个input子元素
[3] 属性名为name且值为username的第一个input元素
2.driver接口获取值
通过WebElement接口可以获取常用的值,这些值同样非常重要。
- size 获取元素的尺寸
- text 获取元素的文本
- get_attribute(name) 获取属性值
- location 获取元素坐标,先找到要获取的元素,再调用该方法
- page_source 返回页面源码
- driver.title 返回页面标题
- current_url 获取当前页面的URL
- is_displayed() 设置该元素是否可见
- is_enabled() 判断元素是否被使用
- is_selected() 判断元素是否被选中
- tag_name 返回元素的tagName
安装过程:http://blog.csdn.net/eastmount/article/details/47785123
四. 找工作杂谈:你只是看起来很努力
最近找工作之余看了《你只是看起来很努力》,非常喜欢里面的故事,而这些故事仿佛就是自己的折射,倒映着我们的身影,在此分享与君卿共勉,希望能引起你的共鸣。

我们看起来每天熬夜,却只是拿着手机点了无数个赞;
看起来在图书馆坐了一天,却真的只是坐了一天;
看起来买了很多书,只不过晒了个朋友圈;
看起来每天很晚地离开办公室,上班的时间却在偷懒;
那些所谓的努力时光,是真的头脑风暴了,还是,只是看起来很努力而已?
任何没有计划的学习,都只是作秀而已;
任何没有走心的努力,都只是看起来很努力。
牢记一句话:“所有的努力都不是给别人看的,很多时候,英雄都是孤独的”。
书中第一个故事就是一个女孩垂头丧气的对老师说:“老师,我考了四次四级,还没过,究竟是为什么?”看着学生满满的笔记,老师心想,看起来很努力啊,没理由不通过啊!哎,这不就是活生生的自己吗?自己四级六次才通过,六级还由于分数太低被禁考。究其原因…
我们总会陷入这样一个怪圈:看似忙碌,实则焦虑。当我们心血来潮想学习时,买了很多书,却再也没有翻开过;当我们备受刺激想健身时,于是找了很多攻略,但再也没有动过;当我们在社交网络上花费很多时间把认为有用的东西另存为时,直到你的硬盘存得满满当当,然而你却没有看过。我们忙碌,却没有去了解那些精挑细选留下的内容;我们花时间收集,却忘了最重要的其实是花时间去消化。你将会在一遍遍地逃避和自我安慰中变得惴惴不安,拖延和等待也终将击垮你的斗志。这就是我支教时分享过的一句话:“记笔记如果光记不看还不如不记”。
不要看到别人做什么好,就去尝试做什么,那些看起来的光鲜也有属于他们自己的苦逼。当然,打败焦虑的最好办法就是去做那些让你焦虑的事情。希望你看完这几句话之后,也会有所感悟,真切地做起身边的每一件事。路还是要一步步地走,可以走得很慢,但却不能停止。
最近找工作也不是很顺利,这也验证了一点:
努力的人很多,这个世界最不差的就是优秀的人,尤其是程序员,除非你无可替代。优秀是不够的,一定要卓越,多学点拿得出手的东西,否则你只会得到一句“虽然你很优秀,但你运气不好,这位置已经有人了”。
如果你的简历上都是些会Java语言、MySQL、HTML、Python等,这并没有什么亮点。还不如:对Java虚拟内核有过研究、熟悉PHP什么开发框架、MongoDB做过应用、Ajax\JavaScript异步消息传输、熟悉Socket\TCP通讯、研究过SVM\神经网络算法等。
同时能内推的,尽量找师兄师姐帮忙内推,笔试题目各式各样,各种基础而且较深的知识,包括OS、计算机网络、数据库、Linux、JavaScript、C++面向对象、算法等,所以推荐内推直接考察你的项目能力。如果实在没有机会内推,就需要尽早的准备基础知识,否则你会吃亏。一般8月、9月、10月高峰期,所以暑假6-7月就要开始准备了。同时推荐两个地方:一个是LeetCode刷题,这个是真心的有用啊!还有一个就是牛客网刷基础的选择题。
再强调一遍:这个世界优秀的人太多,你需要的是卓越!
其实不论多忙,我都会坚持写博客,我认为这个过程并不是学习了,而是休息放松的过程,而且能够让我体会到分享的乐趣,非常开心~困得不行了
总之,希望文章对你有所帮助,如果不喜欢我的这种杂乱的叙述方式,请不要喷我,毕竟花费了自己的一夜经历完成,尊重作者的劳动果实吧!欢迎随便转载~
(By:Eastmount 2015-10-2 早上9点
http://blog.csdn.net/eastmount/
)
看起来在图书馆坐了一天,却真的只是坐了一天;
看起来买了很多书,只不过晒了个朋友圈;
看起来每天很晚地离开办公室,上班的时间却在偷懒;
那些所谓的努力时光,是真的头脑风暴了,还是,只是看起来很努力而已?
任何没有计划的学习,都只是作秀而已;
任何没有走心的努力,都只是看起来很努力。
牢记一句话:“所有的努力都不是给别人看的,很多时候,英雄都是孤独的”。
书中第一个故事就是一个女孩垂头丧气的对老师说:“老师,我考了四次四级,还没过,究竟是为什么?”看着学生满满的笔记,老师心想,看起来很努力啊,没理由不通过啊!哎,这不就是活生生的自己吗?自己四级六次才通过,六级还由于分数太低被禁考。究其原因…
我们总会陷入这样一个怪圈:看似忙碌,实则焦虑。当我们心血来潮想学习时,买了很多书,却再也没有翻开过;当我们备受刺激想健身时,于是找了很多攻略,但再也没有动过;当我们在社交网络上花费很多时间把认为有用的东西另存为时,直到你的硬盘存得满满当当,然而你却没有看过。我们忙碌,却没有去了解那些精挑细选留下的内容;我们花时间收集,却忘了最重要的其实是花时间去消化。你将会在一遍遍地逃避和自我安慰中变得惴惴不安,拖延和等待也终将击垮你的斗志。这就是我支教时分享过的一句话:“记笔记如果光记不看还不如不记”。
不要看到别人做什么好,就去尝试做什么,那些看起来的光鲜也有属于他们自己的苦逼。当然,打败焦虑的最好办法就是去做那些让你焦虑的事情。希望你看完这几句话之后,也会有所感悟,真切地做起身边的每一件事。路还是要一步步地走,可以走得很慢,但却不能停止。
最近找工作也不是很顺利,这也验证了一点:
努力的人很多,这个世界最不差的就是优秀的人,尤其是程序员,除非你无可替代。优秀是不够的,一定要卓越,多学点拿得出手的东西,否则你只会得到一句“虽然你很优秀,但你运气不好,这位置已经有人了”。
如果你的简历上都是些会Java语言、MySQL、HTML、Python等,这并没有什么亮点。还不如:对Java虚拟内核有过研究、熟悉PHP什么开发框架、MongoDB做过应用、Ajax\JavaScript异步消息传输、熟悉Socket\TCP通讯、研究过SVM\神经网络算法等。
同时能内推的,尽量找师兄师姐帮忙内推,笔试题目各式各样,各种基础而且较深的知识,包括OS、计算机网络、数据库、Linux、JavaScript、C++面向对象、算法等,所以推荐内推直接考察你的项目能力。如果实在没有机会内推,就需要尽早的准备基础知识,否则你会吃亏。一般8月、9月、10月高峰期,所以暑假6-7月就要开始准备了。同时推荐两个地方:一个是LeetCode刷题,这个是真心的有用啊!还有一个就是牛客网刷基础的选择题。
再强调一遍:这个世界优秀的人太多,你需要的是卓越!
其实不论多忙,我都会坚持写博客,我认为这个过程并不是学习了,而是休息放松的过程,而且能够让我体会到分享的乐趣,非常开心~困得不行了
总之,希望文章对你有所帮助,如果不喜欢我的这种杂乱的叙述方式,请不要喷我,毕竟花费了自己的一夜经历完成,尊重作者的劳动果实吧!欢迎随便转载~















 1340
1340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











