







最简单的MapReduce应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。main 函数将作业控制和文件输入/输出结合起来。
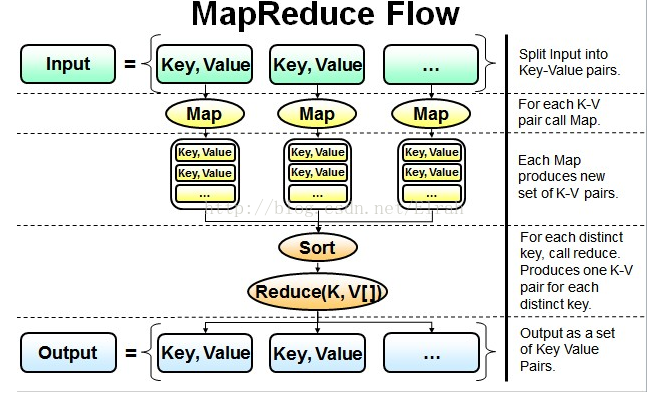
并行读取文本中的内容,然后进行MapReduce操作
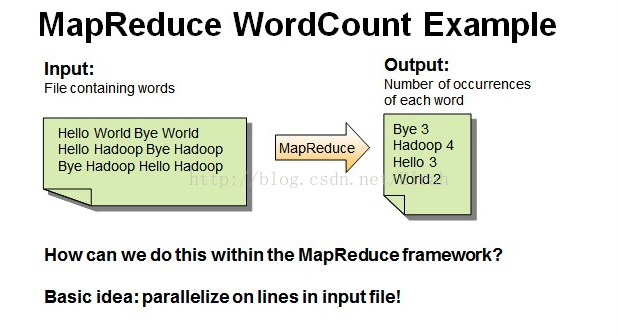
- Map过程:并行读取文本,对读取的单词进行map操作,每个词都以<key,value>形式生成。
我的理解:
一个有三行文本的文件进行MapReduce操作。
读取第一行Hello World Bye World ,分割单词形成Map。
<Hello,1> <World,1> <Bye,1> <World,1>
读取第二行Hello Hadoop Bye Hadoop ,分割单词形成Map。
<Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1>
读取第三行Bye Hadoop Hello Hadoop,分割单词形成Map。
<Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
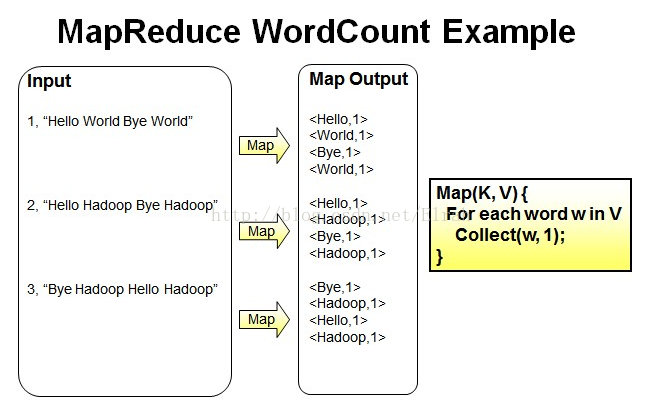
- Reduce操作是对map的结果进行排序,合并,最后得出词频。
经过进一步处理(combiner),将形成的Map根据相同的key组合成value数组。
<Bye,1,1,1> <Hadoop,1,1,1,1> <Hello,1,1,1> <World,1,1>
循环执行Reduce(K,V[]),分别统计每个单词出现的次数。
<Bye,3> <Hadoop,4> <Hello,3> <World,2>
WordCount程序:
package mr;
import java.io.IOException;
import java.net.URI;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyWordCount {
static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
/**IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类,这些类实现了WritableComparable接口,
*都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为int,String 的替代品。
*Context:收集Mapper输出的<k,v>对。
*Context的write(k, v)方法:增加一个(k,v)对到context
*程序员主要编写Map和Reduce函数.这个Map函数使用StringTokenizer函数对字符串进行分隔,通过write方法把单词存入word中
*write方法存入(单词,1)这样的二元组到context中
*/
public void map(LongWritable k1, Text v1, Context context)
throws java.io.IOException, java.lang.InterruptedException
{
String[] lines= v1.toString().split("\\s+");
for(String word: lines){
context.write(new Text(word), new IntWritable(1));
}
System.out.println("map......");
}
}
static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws java.io.IOException, java.lang.InterruptedException
{
int sum=0;
Iterator<IntWritable> it=values.iterator(); //it是一个集合
while(it.hasNext()){
sum+= it.next().get(); //it.next()是一个泛型--IntWritable,用get()方法把它转换成int类型
}
context.write(key, new IntWritable(sum));
System.out.println("reduce......");
}
}
private static String INPUT_PATH="hdfs://master:9000/input/1.txt";
private static String OUTPUT_PATH="hdfs://master:9000/output/c/";
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(new URI(OUTPUT_PATH),conf);
//如果路径中的文件存在,则自动删除,重新创建输出文件
if(fs.exists(new Path(OUTPUT_PATH)))
fs.delete(new Path(OUTPUT_PATH));
Job job=new Job(conf,"myjob");//创建一个job
job.setJarByClass(MyWordCount.class);//通过传入的class 找到job的jar包
job.setMapperClass(MyMapper.class);//设置map/reducer处理类
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setCombinerClass(MyReduce.class); //设置Combine处理类
FileInputFormat.addInputPath(job,new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
job.waitForCompletion(true);
//Job运行,true表示将运行进度等信息及时输出给用户,false的话只是等待作业结束
}
}map函数:
public void map(LongWritable k1, Text v1, Context context)
throws java.io.IOException, java.lang.InterruptedExceptionreduce函数:
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws java.io.IOException, java.lang.InterruptedExceptionmain函数:
Configuration conf=new Configuration(); Job job=new Job(conf,"myjob"); job.setJarByClass(MyWordCount.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);













 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









