






初级桌面搜索系统实现(Small Dream Search V0.5 Released)
EmilMatthew(EmilMatthew@126.com)
摘要:
实现了一个初级的桌面搜索系统,该系统目前可以对由acscii字母所组成的单个字符串进行查询。对文档中的关键词进行权重判定采用的是idf方法
关键词: IR,TF_IDF,Desktop Search
The Implement of a basic desktop search engine
(Small Dream Search V0.5 Released)
EmilMatthew(EmilMatthew@126.com)
Abstract:
In this paper , I describe the implement of a basic desktop search engine which I have just finished recently . This engine , which called as “Small Dream Search” , supports the query for a single string as a key word currently . I use tf idf algorithm to determine the key word’s weight in each related document.
KEY WORDS: IR,TF_IDF,Desktop Search
1背景介绍:
信息时代,搜索已成为人们使用网络获取知识的一个重要途径,一些著名的搜索引擎已俨然成为了搜索的代名词。虽然,我们并不能过度的去依赖于搜索引擎来获取知识,但是它们毕竟为人们获取知识的途径上开创了一条崭新的大道。从程序设计的实践角度而言,设计一个功能及规模较为小巧的桌面搜索系统,无疑又是一次从理论到实践的非常好的锻炼机会。
2程序的总体设计:
这个桌面搜索系统主要由两部分组成:主机端(Claw)和客户查询端(Client),下面分别介绍之:
2.1主机端(Claw)
主机端主要负责对已有的指定路径内的所有文件进行扫描,统计各文件中各单词出现的频率,建立相应的数据库(这里采用倒排文件的方式)。
2.2客户端(Client)
客户端主要进行查询的工作,当键入关键的查询单词时,如果在数据库中,有该单词的倒排文件,则可以得到与该单词相关联的所有已扫描文件的信息,最终以一个含有文件路径及摘要的网页作为输出加以呈现。
3程序的详细设计:
下面具体来谈一下设计时的一些重点:
3.1主机端(Claw)
主机端的运行框架是这样的:
For each file in the searchDir (including its subDir)
{
If file’s suffix is legal then
Parse the file and save info to the db
End if
}
总的说来,无非就是一个遍历指定路径下的所有文件(包括子路径中的文件)再加上扫描单个文件并将信息记录至库中的操作。
3.1.1遍历指定路径下的所有文件:
这里采用递归的形式进行遍历,较非递归的形式效率稍逊。
parseDir(dirStruct curDir)
{
For all file’s or subDir in the curDir
{
If it is a subDir
parseDir(subDir)
Else // it is a file
parseSingleFile(fileName)
}
}
这里在实现时所需要用到的相关函数,是C语言中<io.h>中的几个较为重要的函数以及结构体_finddata_t:
struct _finddata_t {
unsigned attrib;
time_t time_create; /* -1 for FAT file systems */
time_t time_access; /* -1 for FAT file systems */
time_t time_write;
_fsize_t size;
char name[260];
};
long _findfirst(const char *, struct _finddata_t *); //找到当前文件夹下第一个含有查找项的文件或目录的句柄
int _findnext(long, struct _finddata_t *); //依着上次找到的文件,找下一个文件或目录
int _findclose(long); //关闭查找句柄,不关将引起内存泄漏。
另外,在判定是否是目录时,可采用下面的判定:
If tempFileInfo.attrib&_A_SUBDIR //tempFileInfo为_findfirst或_findnext中的第二个参数.
有两个目录”..”上一层或”.”,如不需要,应删除。
另外,还需要改变路径的一个函数(在<direct.h>中)
void _chdir(const char* pathName);
3.1.2遍历单个文件中,采集各单词出现的频率,并记录进入相应的倒排文件中
3.1.2.1倒排文件
首先介绍一下什么是倒排文件,通常,对于一个文件进行单词出现频率的统计记录时,可以采用这样的形式:
someFile:
str1 freq1
str2 freq2
… …
这便是所谓正排的形式,是以文件名作为索引的方式,而倒排呢?便是以各单词作为索引,而将该单词出现的文件名及该单词在该文件中出现的频率作为内容加以存储,如下:
Str1
relateFile1 freq1
relateFile2 freq2
……
当然,可以对relateFile1加以编码处理,如采用MD5算法,以节省存储空间。这里仅仅按原路径字符串的形式加以保存。
3.1.2.2扫描文件,将符合条件的字符串取出,加以统计
这里涉及到三方面的工作,一个是将各单词从文件中取出,第二个是进行合法性检查,最后是进行统计。
[a]将各单词从文件中取出:
这可以算作是个filter的工作:
主框架如下:
while(file not end)
{
do
{
Get a new charà tmpChar;
if(file reach end)
goto out1;
}while(tmpChar is not a ascii code);
out:
while(tmpChar is a ascii code)
{
If tmpChar is capitalization then
Change to lowcase
Equip tmpChar to newString
Get a new charà tmpChar;
if(file reach end)
{
Break;
}
}
Make new string’s ending;
}
[b]合法性检查:
主要进行的合法性检查有字符串过短(仅为一个字符)、字符串过长(单个词长超过30个字母)以及对搜索意义不大的字符串的过滤(如a , the ,what ,be 等)。这一部分内容较简单,故略去伪码描述。
[c]统计单词在当前文章中的出现频率并入库:
统计单词出现的频率较易,这里重点谈一下入库的操作:
这里,对于单词的倒排文件,采用一个hash函数,将各单词的ascii码值转换成一个整数值,并以10000个文件为单位,存放于单词倒排文件夹中。如0号文件夹中,存放的即为单词的hash码为0-9999的倒排文件。1号文件夹中,为hash码为10000-19999的倒排文件,依次类推。
所以,当一个单词要入库时,采用以下的框架找到其合适的倒排文件位置:
Flag=0
Do
{
If(invert file name is hash(curString) not be created)
{
Create the invert file and save the first file address and curString’s freq to invert file
Flag=1
}
Else
{
If(invert file name is hash(curString) has been created && it is corresponed to curString)
{
Append the file address and curString’s freq to invert file
Flag=1
}
Else
{
Using hashValue=(hashValue+1)%maxLen strategy to prepare the str’s corresponded file
}
}
}while(!Flag)
由于对于一个文件,这里涉及了较多的IO操作,所以,仍有较大的改进余地。
3.2客户查询端(Client)
比起主机查询端,客户查询端的工作要轻松不少,主要就是对输入的关键字进行hash处理,找到其对应的倒排文件,提取其中的文件路径信息,并运用相应的权重计算策略,加以排序,最终,以摘要的形式呈现。
这里介绍一下目前实现的权重计算策略,采用的是tf_idf算法。
所谓idf指的是某个单词在搜索时的显著度影响,比如说,这个单词在所有文件中出现的次数较少,那么搜索这个关键词时,与之相关的文件就会一下凸显出来;反之,如果某个单词在许多文件章中都出现的,那么,搜索它时就很难有一个较好的区分结果,有点“泯然众人”之感。
所以,可以定义IDFi=log(N/ni) 其中:N为现在库中的总文件数,而ni则是表示含有字符串i的文件的数目。
再令Fi,j为字符串i在文档j中的出现的频率后的正交化处理后的结果:
Fi,j=Fi,j/maxl freql,j //这一步由主机端处理
则有字符串对应于其出现文档j的权重值:
Wi,j=Fi,j*IDFi
另一种更具区分效果的权重计算方式:
Wi,j=(0.5+0.5*Fi,j)*Log(N/ni)
对权重值按降序排列,即得最终的相关文档的排序结果。
4程序配置文件中参数的说明:
4.1主机端:
fArgus.txt
gSupChs=0 // 是否支持中文,0表示不支持
gSearchDB=f:/testSearch/DSearchDB // 存放倒排文件的库,该文件夹需自己创建
gGlobalVal=f:/testSearch/GlobalVal // 存放全局变量的文件所在文件夹,需自己创建
gMode=0 // 模式:0表示从文件读入搜索路径,1则从屏幕上读取。
gInputDBDir=f:/testSearch/SearchAdd // 搜索的文件夹位置,目前不支持有空格,请不要在路径后加/,如要扫描C盘,用C:即可
fEleWords.txt
存放需要过滤的单词
A
The
… …
fSuffix.txt
存放可接受的后缀
Suf1
Suf2
… …
4.2客户端:
gSearchDB=f:/testSearch/DSearchDB //同主机端
gGlobalVal=f:/testSearch/GlobalVal //同主机端
gHtmlHome=f:/testSearch/HtmlHome //存放搜索结果页面的文件夹,其中需放置引擎图标flag.jpg图片
gAlgoType=1 //选择算法,1:tf_idf
gCMode=0 //模式:同主机端
gCSearchWord=apple //搜索关键词
如找到相关的文件时,将会出现下面的搜索结果界面:
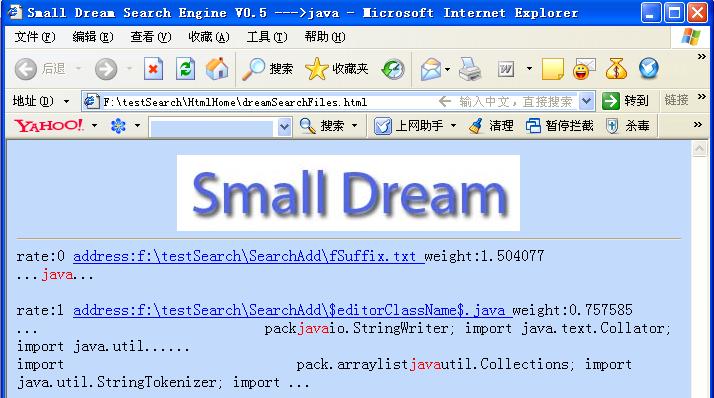
欢迎试用及调试,提出批评与整改意见!
5 To Version1.0的改进之处:
1将文件遍历改成非递归形式。
2可支持多个关键词的扫描。
3支持中文路径,但不支持中文文件。
4改进文件入库存的IO操作,加速抓取。
5采用多线程模式,加速抓取。
6对重复入库的文件加以调整。
7可支持多个路径的扫描。
8加强系统的可靠性:比如,中断扫描时,仍能保证库中的文件及相关的数据受到最少的影响。
9可辨认文件名中含有多个.的文件。
10配置文件中路径带空格可以接受。
11倒排文件中的路径采用MD5或相应的算法进行压缩处理。
参考资料:
[1]Ricardo Baeza-Yates , Berthier Riberiro-Neto, Modertn Information Retrieval,Addision Welety,2005.
[2] 李晓明、闫宏飞、王继民,搜索引擎 原理、技术与系统 ,科学出版社 ,2005
完成日: 06/06/20
附录:
1测试程序下载:
http://emilmatthew.51.net/EmilPapers/0623DreamSearch/code.rar
若直接点击无法下载(或浏览),请将下载(或浏览)的超链接粘接至浏览器地( 推荐MYIE或GREENBORWSER)址栏后按回车.若不出意外,此时应能下载.
若下载中出现了问题,请参考:
http://blog.csdn.net/emilmatthew/archive/2006/04/08/655612.aspx
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









