






实现功能如:
将a.xls中的第11列数据复制到b.xls表格的第一列中
将表格路径写到txt中,python读取txt数据作为参数(这是为了将py文件生成exe给没有python环境的人用的时候可以通过配置txt参数实现不同需求)
代码如下:
#!/user/bin/env python
# -*- coding:utf-8 -*-
# @Time :2020/6/11 22:25
# @Author Wu Zi Jing
# @File :copyid.py
from xlutils.copy import copy
import xlrd
import codecs
from xlwt import *
class copydata():
def Copyid_Excel(self):
f_space = open("D:\\sheet\\Setdata.txt", "r")
line_space = f_space.readlines()
aimway = []
for i in range(0, len(line_space)):
line_space[i] = line_space[i].strip("\n")
aimway.append(line_space[i].split(",")[0])
aimway.append(line_space[6].split(",")[1])
print(aimway)
#print(aimway[0])
fileName = aimway[0]
fileName2 = aimway[1]
bk = xlrd.open_workbook(fileName)
shxrange = range(bk.nsheets)
try:
sh = bk.sheet_by_name(aimway[3])
except:
print("代码出错")
nrows = sh.nrows # 获取行数
bk2 = xlrd.open_workbook(fileName2, formatting_info=True) #formatting_info=True保留原Excel格式
wb = copy(bk2)
#sheet = wb.get_sheet(0)
sheet = wb.get_sheet(aimway[4])
for i in range(1, nrows):
row_data = sh.row_values(i)
# 获取第i行第3列数据
# sh.cell_value(i,3)
# ---------写出文件到excel--------
print("-----正在写入 " + str(i) + " 行")
sheet.write(i + 1, int(aimway[6]), label=sh.cell_value(i, int(aimway[5]))) # 读取第12列数据,向第2行第1列写入获取到的值
sheet.write(i + 1, int(aimway[7]), label=sh.cell_value(i, int(aimway[5]))) # 读取第12列数据,向第2行第10列写入获取到的值
wb.save(aimway[2])
if __name__ == '__main__':
a =copydata()
a.Copyid_Excel()
生成exe命令:
pyinstaller -F copyid.py
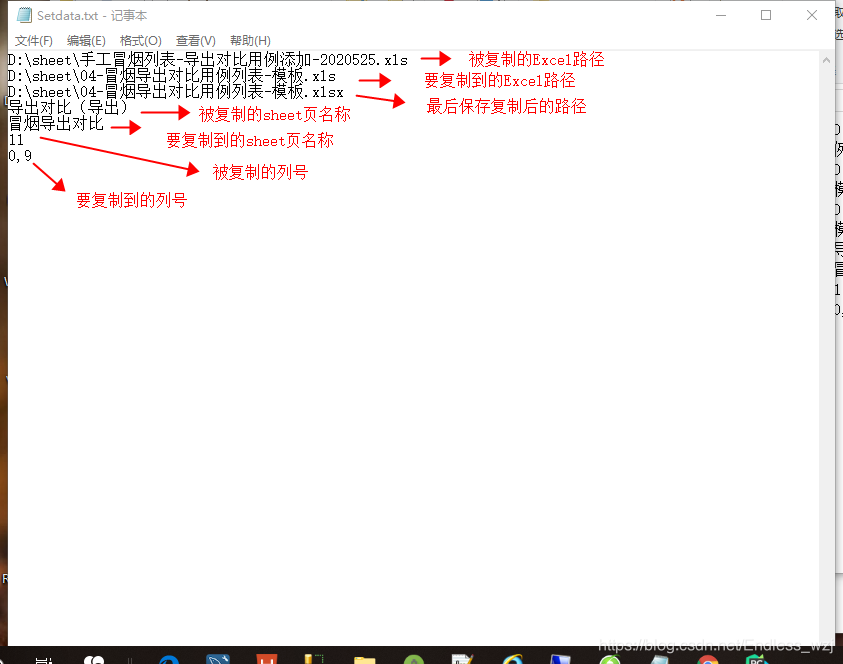
配置参数说明:














 2101
2101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









