







We want to calculate the derivatives of the cost with respect to all the parameters, for use in gradient descent. Now, there’s often millions, or even tens of millions of parameters in a neural network. So, reverse-mode differentiation, called back propagation in the context of neural networks, gives us a massive speed up!
(Are there any cases where forward-mode differentiation makes more sense? Yes, there are! Where the reverse-mode gives the derivatives of one output with respect to all inputs, the forward-mode gives us the derivatives of all outputs with respect to one input. If one has a function with lots of outputs, forward-mode differentiation can be much, much, much faster.)
Back propagation is also a useful lens for understanding how derivatives flow through a model. This can be extremely helpful in reasoning about why some models are difficult to optimize. The classic example of this is the problem of vanishing gradients in recurrent neural networks.
以上 参考博客
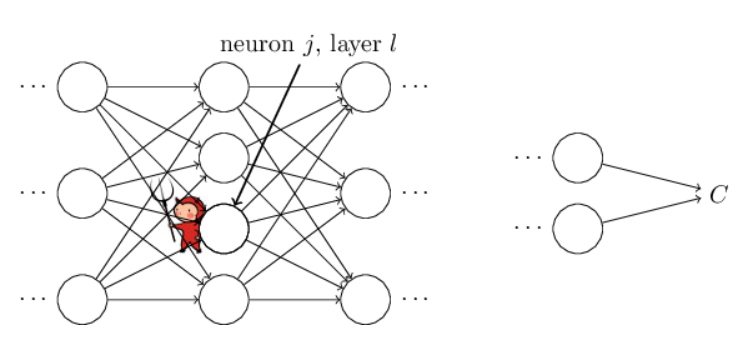
BP算法可以理解成,修改网络中w和b的值如何影响到C(cost function)的值。其实也就是我们常说的求偏差。我们首先引入了一个中间值δ(jl),表示第l层的第j个神经元的error,不会打符号啊......左边表示下标j,右边表示上标l。BP将会提供给我们一套计算δ(jl)的流程,再接下来我们就可以通过δ(jl)来计算C关于w和b的偏导数了。
CSDN符号写起来太麻烦了......大家去看下边的推荐阅读链接吧,虽然是英文的,但是写的很好,我读了整整一晚上,但是收获很大。
Backpropagation algorithm:

对了,注意BP算法和梯度下降算法不是一个概念,不要混淆。
BP相比传统定义式(前向)求梯度速度大大提升,传统是一次一个一个算,BP则可以一次全部算出来。
(详细见推荐阅读:In what sense is backpropagate a fast algorithm?)
而且BP不是万能药,早在上世纪80年代,就已经发现BP并不能训练DeepNN,是后来的人们想出了一些聪明的方法来让BP训练深网成为可能的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









