







2006_Efficient Learning of Sparse Representations with an Energy-based Model
此文也是Deep learning三大breakthrough文章之一,其实就是稀疏的autoencoder,以下为摘要。
该篇论文是使用Autoencoder作为深度多层神经网络的building block的比较早期的工作.
模型结构图:
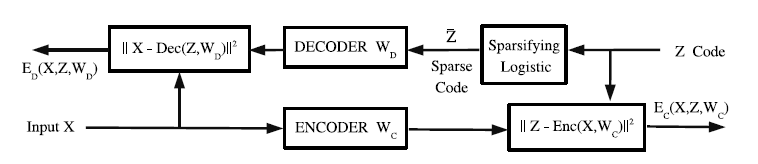
encoder
Sparsifying Logistic
decoder
能量函数为:
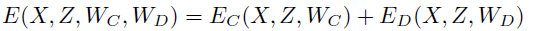
其中,


Sparsifying Logistic是一个非线性模块,它的输入输出如下:
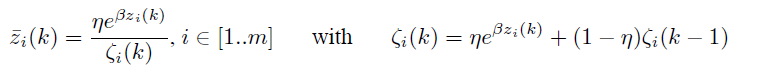
i是code的第i个component,
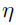 控制稀疏度,
控制稀疏度,
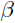 控制输出的饱和度(softness)
控制输出的饱和度(softness)
控制稀疏度,
控制输出的饱和度(softness)
另一种观点是类似于sigmoid函数,右边除以
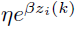 ,得到:
,得到:
,得到:

学习过程:
Loss function:

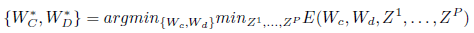

实验:
1. Feature Extraction from natural image patches
dataset: Berkeley segmentation dataset

2. Feature Extraction from handwritten numerals

3. Learning Local Features for MNIST dataset
用文中叙述的方法预训练LeNet-5的第一层,将网络结构改为50-50-200-10,用5*5的image patches训练,得到50维的稀疏表示,用此参数初始化CNN的第一层。















 3411
3411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









