







How does the bia unit of neural network come out?
Let's assume the parameters matrix(vector) is Θ =
In order to let variables matrix(vector) is suitable for multiply, we make a extra = 1 for the input vector.
Therefore, both vectors have n+1 length.
Some trick for gradient descent
1) Scaling
According to others' experience, if the input variables are in the similar range then it will more 'direct' in the process of gradient descent. Here is the picture for comparison I stole from Andrew Ng's lecture:
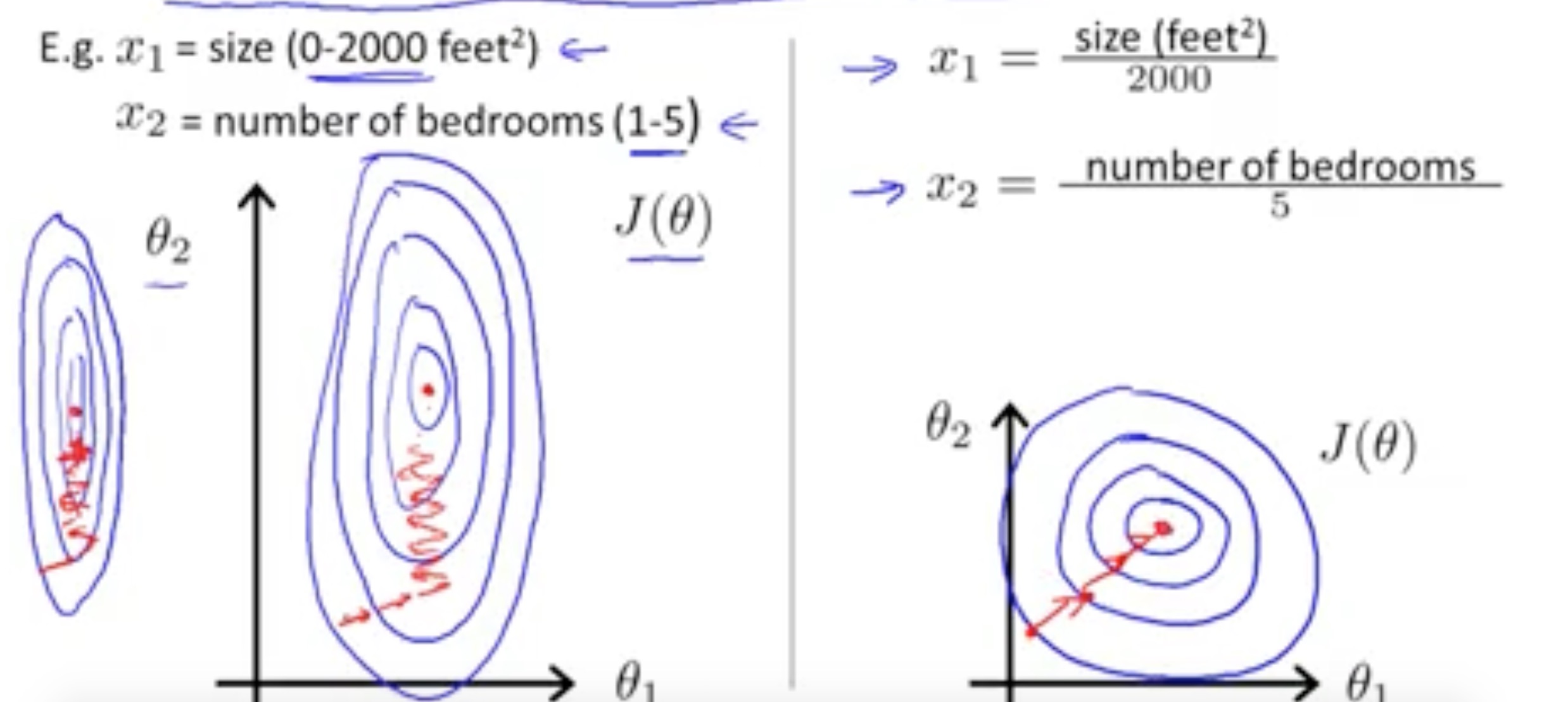
This is the first kind of scaling. It just 'normalize' the variables to a similar range.
Another scaling mean is to make the 'zero mean':

2) Adjusting the learning rate a:
If you are meeting a problem of the gradient descent doesn't make the cost function value less and less, it will be very likely that you have set a learning rate larger than it should be.
Maybe the situations are like:
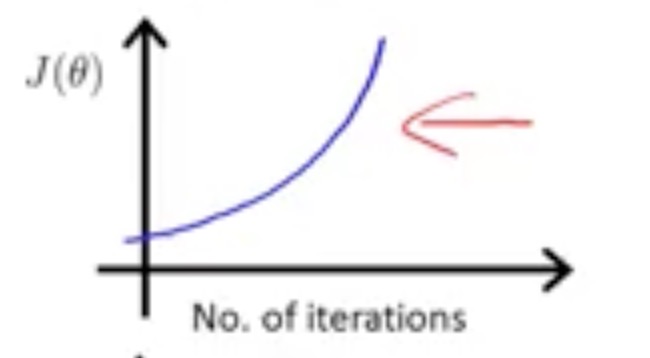
Or:
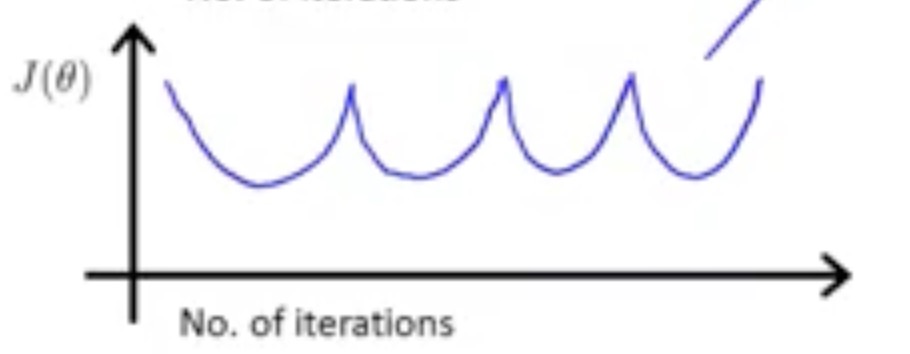
Just make the learning rate smaller.
The reason for leading to this may be:
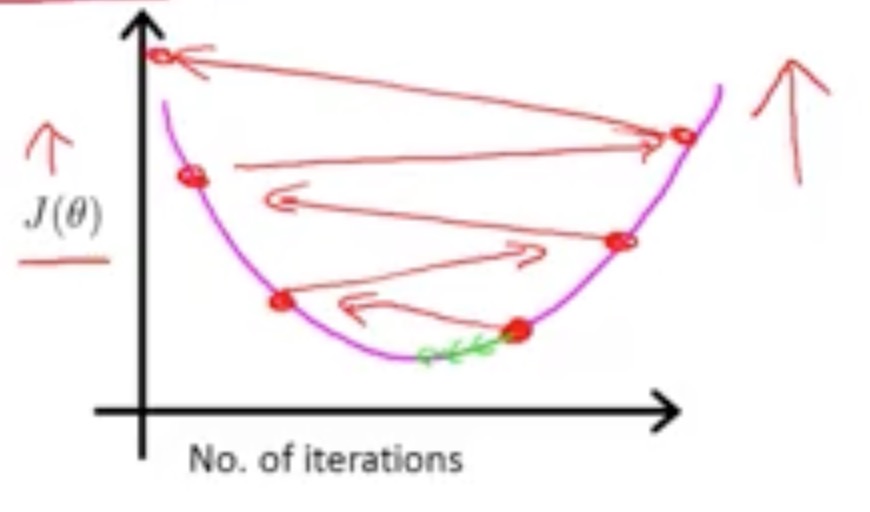
The red line function is the cost function then if the a is too big, it will jump to the opposite side directly.
Reference:
Pictures come from the course given by Andrew Ng















 1777
1777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









