







First of all, let's add something missed from the previous section:
What is the practical meaning of output of sigmoid function?
It is the posterior possibility of y = 1. P(y=1 |x,Θ) = ? If we want to get P(y=0 |x,Θ) = 1 - P(y=1 |x,Θ).
Second, the Θ matrix is decided by the training data. And the decision boundary is decided by the Θ parameters.
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
How can we define the cost function of logistic regression?
First, let us look back to linear regression's cost function:

However, if we apply this to logistic regression, we will encounter the non-convex problem(The cost function become non-convex function). Here is the non-convect example raised by Andrew Ng:

Therefore, when we perform gradient descent in a non-convex function, it cannot be guarantee that it will reach the global minimum.
In contrast, what does convex function look like?
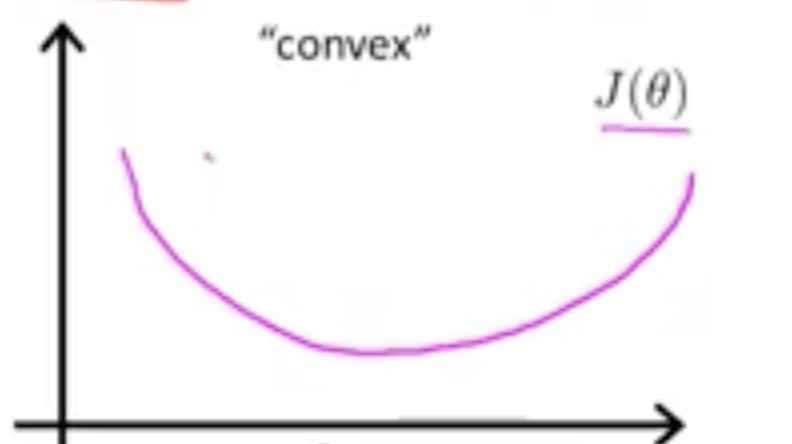
Therefore, if we perform gradient descent in such kind of function, we can guarantee to have the global minimum.
Here is the definition of cost(not cost function) for logistic regression:
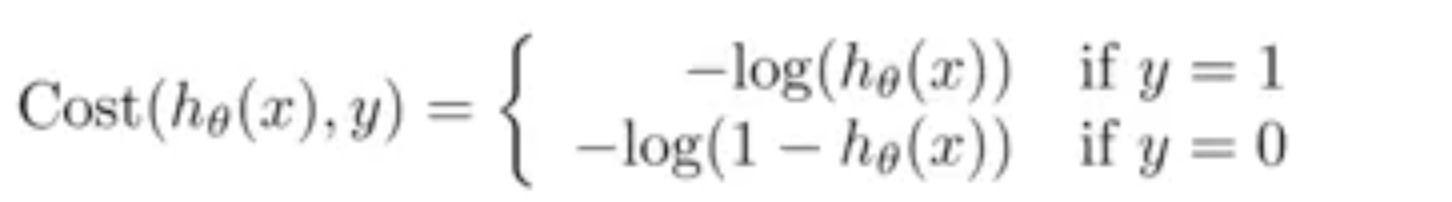
Here is the relevant pictures for this:

So the range [0,1] for -logz is:
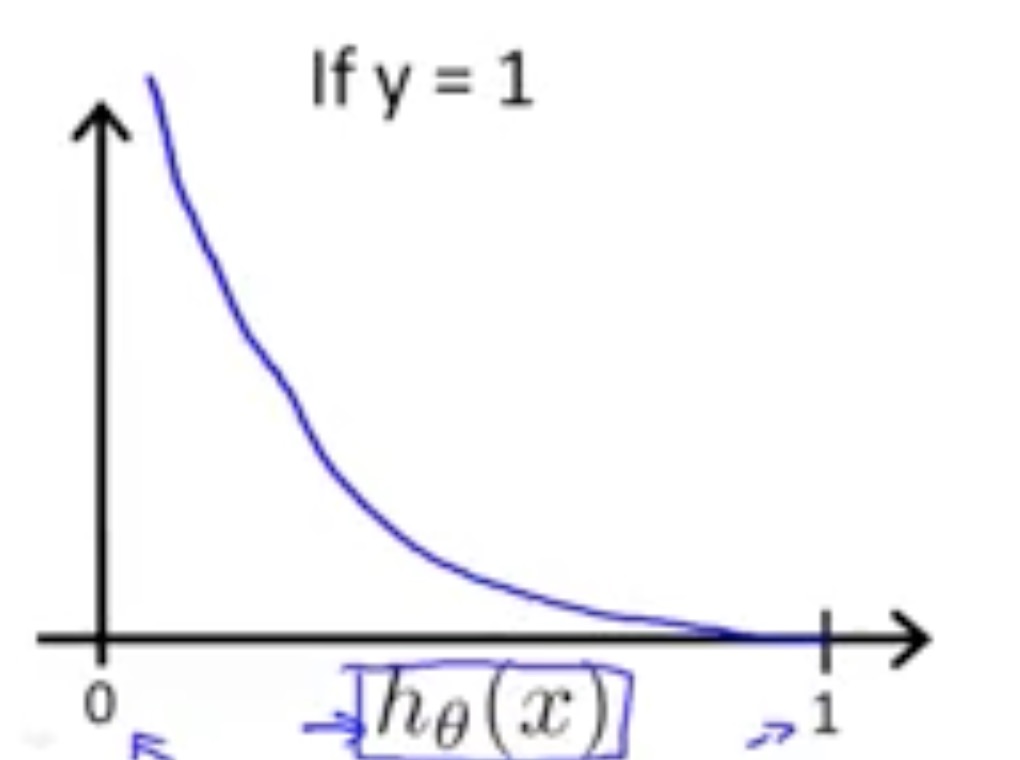
And the picture for -log(1-z) is:
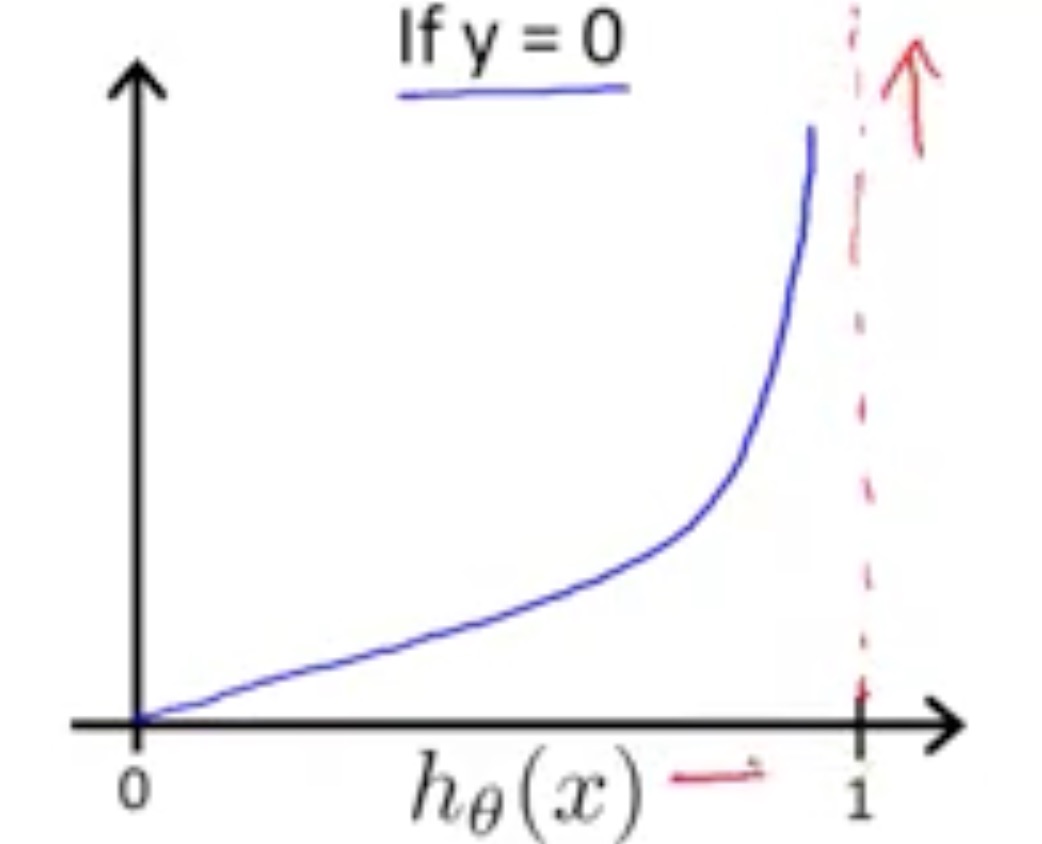
Then in order to compress(cost) this expression, we change this a little:
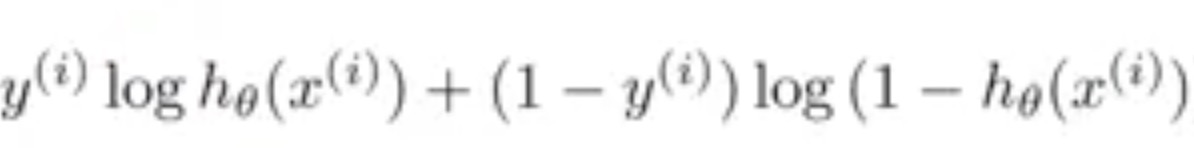
Therefore, we can get the cost function for logistic regression:

However, if we perform gradient descent to such equation, we can see the result is the same as linear regression:
















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









