









概要
作为计算机视觉领域的三大任务之一(图像分类,目标检测,图像分割),图像分割这些年也获得了长足的发展,它被广泛用于在医学图像和自然图像的分割上,除此之外,图像分割也被用于在道路分割上,这对于自动驾驶的发展具有极其重要的意义。
图像分割到目前为止,大致分为三类:
1.语义分割(Semantic Segmentation)
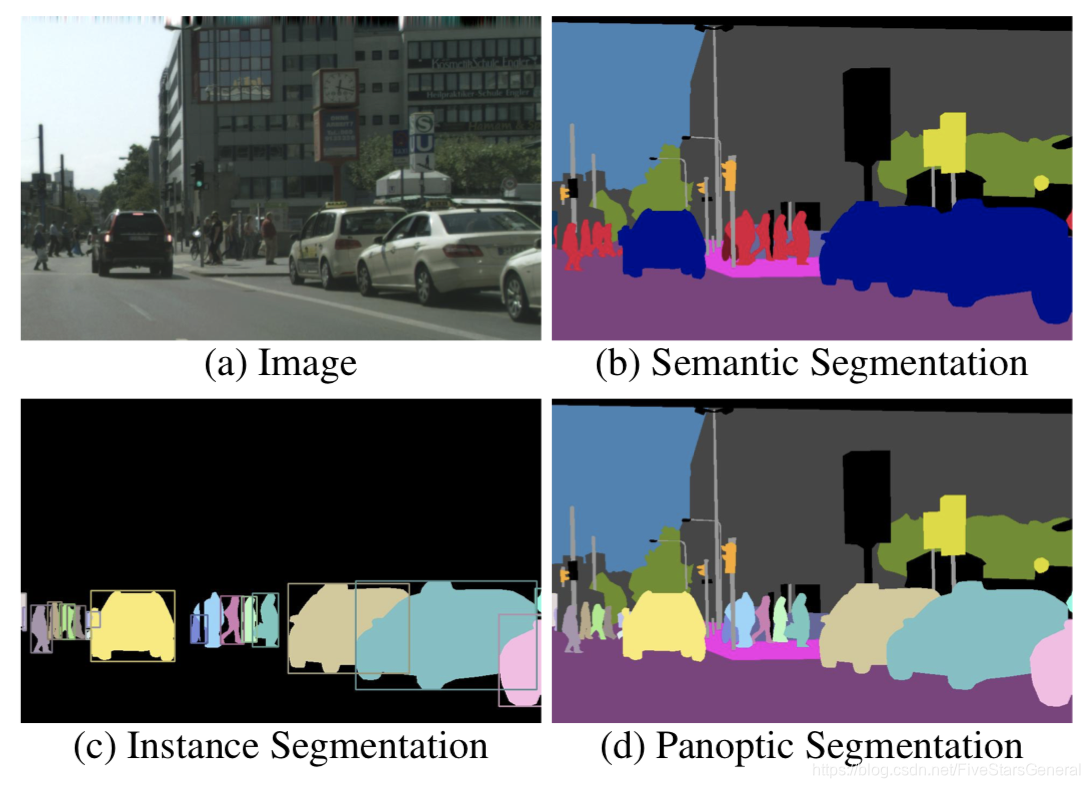
图像语义分割的意思就是机器自动分割并识别出图像中的内容,如下图(b),能够区分物体和背景。
2.实例分割(Instance Segmentation)
图像实例分割,不仅要分割出图像中的不同类别,而且还要对同一类别的不同个体作出区分。如下图(c),对于人和汽车的不同个体都作出区分。
3.全景分割(Panoptic Segmentation)
Panoptic Segmentation 中文名为全景分割,是由 Facebook 的大神联手推出的结合 instance segmentation 和 semantic segmentation 的新任务。作者发现,instance segmentation 只能够分别物体,但是没有办法对 stuff 进行预测。而传统的 semantic segmentation 不能够区分物体。作者提出了同时对物体进行分割,并且对 stuff 进行分类的新任务,如下图(d)。
言归正传…回到全卷积网络:
全卷积神经网络(Fully Convolutional Network,FCN)是在2015年由美国加州大学伯克利分校的Jonathan Long等人提出的用于图像语义分割的一种框架。
论文地址:Fully Convolutional Networks for Semantic Segmentation
代码地址:FCN on Github
核心思想
三个keys:
1.卷积化:去掉全连接层,以卷积层代替,可以适应任意尺寸的输入。
简而言之,FCN将CNN中的FC层去掉换以卷积层替代。传统的CNN在预测图像分类时,最后经过以SoftMax输出的是一维的概率值向量,这些概率值分别对应每个预测种类的预测概率,取最大的那个为预测类别。
而,语义分割不同,语义分割所要得到的是像素级别的分割。而FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷基层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后在上采样的特征图进行像素的分类。全卷积网络(FCN)是从抽象的特征中恢复出每个像素所属的类别。即从图像级别的分类进一步延伸到像素级别的分类。
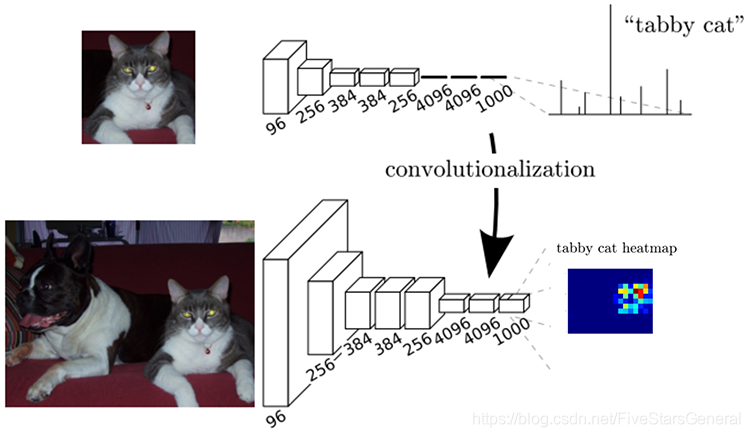
FCN将传统CNN中的全连接层转化成一个个的卷积层。如下图所示,在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别的概率。FCN将这3层表示为卷积层,卷积核的大小(通道数,宽,高)分别为(4096,1,1)、(4096,1,1)、(1000,1,1)。所有的层都是卷积层,故称为全卷积网络。
那这样做有什么优势呢?首先,卷积层表示的是局部的信息,而全连接层则是描绘的是全局信息。用和全连接层相同维度大小的卷积层替换掉全连接层,能够使得卷积网络在一张更大的输入图像上滑动,使得输出图像具有位置信息。
2.上采样:在网络深处以上采样(反卷积)增大图像尺寸,提高输出精确度。
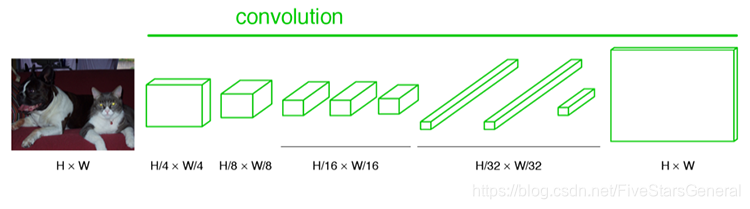
在论文中FCN使用了上采样。这里用的是反卷积操作,相比下采样是使得图像越来越小,而上采样则是使得图像变大。
例如经过5次卷积(和pooling)以后,图像的分辨率依次缩小了2,4,8,16,32倍。对于最后一层的输出图像,需要进行32倍的上采样,以得到原图一样的大小。这个上采样是通过反卷积(deconvolution)实现的。
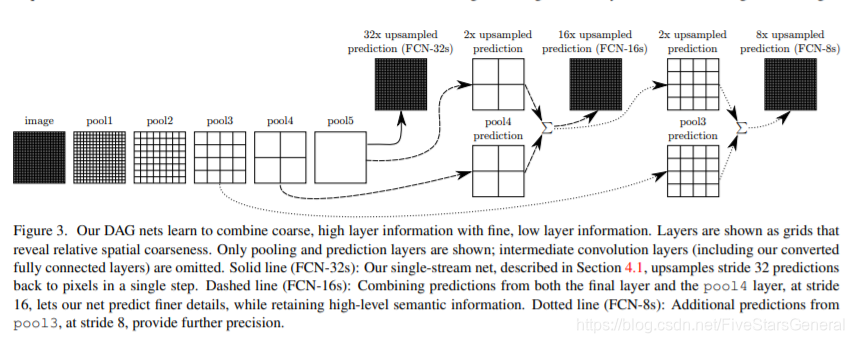
3.dense prediction:采用skip方法结合网络不同层之间的信息,增加模型精确度和鲁棒性。
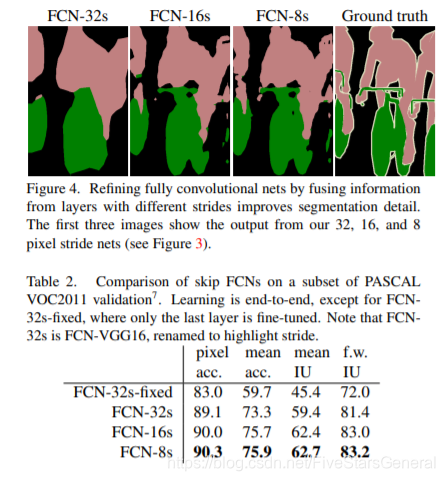
这种方式在文章中也提到,使用skip方法结合多层信息,如深层次的粗糙信息和低层次的精确信息。因为作者发现对第5层的输出(32倍放大)反卷积到原图大小,得到的结果还是不够精确,一些细节无法恢复。于是Jonathan将第4层的输出和第3层的输出也依次反卷积,分别需要16倍和8倍上采样,结果就精细一些了。
这种做法的好处是兼顾了local和global信息。
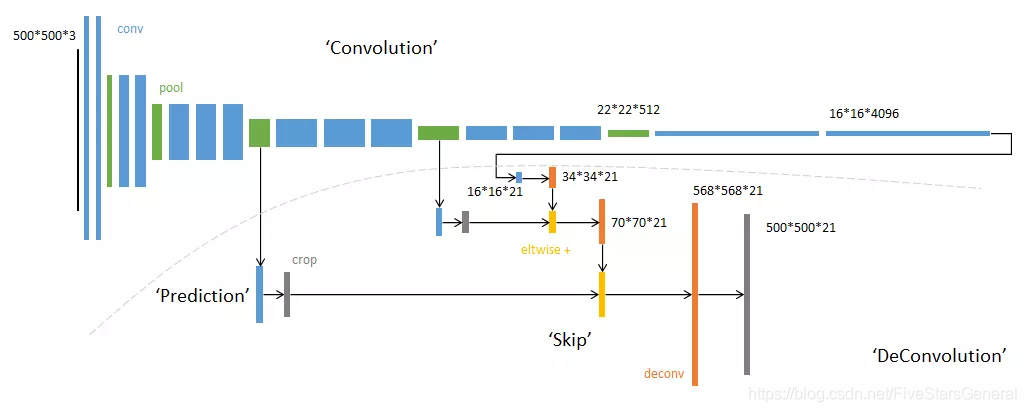
整体网络结构
这篇博文:FCN的学习及理解(Fully Convolutional Networks for Semantic Segmentation)
解释的我觉得很好,所以作为理解,拿来借鉴一下~
整体网络架构分为两部分:虚线上部分和虚线下部分:
虚线上部分表示的是全卷积网络,用来提取图像特征。
全连接层转换为卷积层:在两种变换中,将全连接层转化为卷积层在实际运用中更加有用。假设一个卷积神经网络的输入是 224x224x3 的图像,一系列的卷积层和下采样层将图像数据变为尺寸为 7x7x512 的激活数据体。AlexNet使用了两个尺寸为4096的全连接层,最后一个有1000个神经元的全连接层用于计算分类评分。我们可以将这3个全连接层中的任意一个转化为卷积层:
针对第一个连接区域是[7x7x512]的全连接层,令其滤波器尺寸为F=7,这样输出数据体就为[1x1x4096]了。
针对第二个全连接层,令其滤波器尺寸为F=1,这样输出数据体为[1x1x4096]。
针对最后一个全连接层也做类似的,令其F=1,最终输出为[1x1x1000]。
虚线下部分代表的是图像经过卷积层的不同阶段所产生的的深度为21的预测图像的分类结果。
例如:第一个模块输入16*16*4096,卷积模板尺寸1*1,输出16*16*21。
相当于对每个像素施加一个全连接层,从4096维特征,预测21类结果。
实验效果
参考链接:
FCN 全卷积网络 Fully Convolutional Networks for Semantic Segmentation
FCN于反卷积(Deconvolution)、上采样(UpSampling)
FCN的学习及理解(Fully Convolutional Networks for Semantic Segmentation)














 8676
8676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









