






官方文档地址: https://scikit-learn.org/stable/modules/svm.html
支持向量机是一种有监督的学习算法,常用在分类、回归和异常值检测。支持向量机的优点如下:
• 在高维的数据空间中有效
• 在样本的维度(特征个数)大于样本数时仍有效
• 在决策函数中只使用训练数据的一部分,即支持向量,省内存
• 通用性高,根据不同的决策函数使用不同的核函数,可以使用常见的Kernel,也可以自己定制
但是也有如下的缺点:
• 当样本的特征数远大于样本的数量时,容易过拟合,这是核函数和正则化方式的选择对于模型的效果起着重要的作用
• 支持向量机并不直接给出样本的估计概率,通常需要需要五折交叉验证计算所需的参数
scikit-learn中的支持向量机接收密集样本向量和稀疏样本向量作为输入。然而要使用SVM对稀疏数据进行预测,它必须适合于这样的数据。为了获得最佳性能,密集样本使用C-ordered numpy.ndarray,稀疏样本使用scipy.sparse.csr_matrix,其中dtype=float64。
Classification 分类
SVC、NuSVC和LinearSVC是能够对数据集执行多分类的类。下图是SVC使用不同的核函数时的分类效果
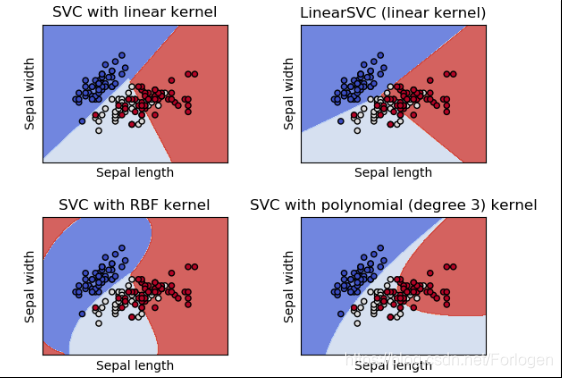
SVC和NuSVC是相似的方法,但是接受的参数集略有不同,并且有不同的数学公式。另一方面,linear SVC是另一种实现支持向量分类的情况下的线性核。LinearSVC不接受关键字kernel,因为LinearSVC 已经假定为线性的。它也缺少SVC和NuSVC的一些成员,比如support_。
与其他分类器一样,SVC、NuSVC和LinearSVC将两个数组作为输入:一个数组X大小为[n_samples,n_features],其中包含训练样本;一个数组y为类标签(字符串或整数),大小为[n_samples]。
SVM决策函数依赖于训练数据的某个子集,称为支持向量。这些支持向量的一些属性可以在成员属性support_vectors_、support_和n_support中找到。
Muti-classclassification
SVC和MuSVC在多分类问题上使用OVO策略,如果n_class是类的数量,则在同一个数据集上,对于二分类问题将构造n_class * (n_class - 1) / 2个分类器。为了给其他分类器提供一致的接口,decision_function_shape选项允许将“一对一”分类器的结果集合到shape的决策函数(n_samples, n_classes):
clf = svm.SVC(gamma='scale', decision_function_shape='ovo')
另外LinearSVC使用OVR策略,因此最后将得到n_class个模型,如果最后仅有两类则将只会训练一个模型。
LinearSVC还使用multi_class='crammer_singer’选项实现了另一种多类策略,即Crammer和Singer制定的所谓的多类SVM。这种方法是一致的,但对于one-vs-rest分类则不适用。在实践中one-vs-rest分类策略通常是首选的,虽然结果基本相似但运行时长明显更少。
对于使用one-vs-rest的LinearSVC,具有形为 [n_class, n_features]和[n_class]的属性coef_和intercept_。系数的每一行对应于n_class中的一个“one-vs-rest”分类器,拦截器也是类似的,按“one”类的顺序排列。
在“one-vs-one”SVC中,属性的布局更加复杂。在使用线性内核的情况下,coef_和intercept_属性的形状分别为[n_class * (n_class - 1) / 2, n_features]和[n_class * (n_class - 1) / 2]。这类似于上面描述的LinearSVC的布局,每一行对应一个二进制分类器。类0到n的顺序是“0 vs 1”、“0 vs 2”、……“0 vs n”、“1 vs 2”、“1 vs 3”、“1 vs n”……“n - 1 vs n”。
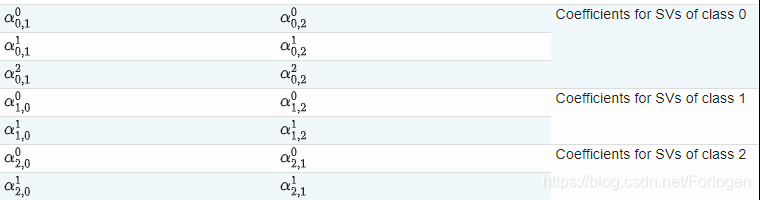
dual_coef_的形为[n_class-1, n_SV],布局有点难把握。列对应于任何n_class * (n_class - 1) / 2“one-vs- 1”分类器中涉及的支持向量。每个支持向量都用于n_class - 1分类器。每一行中的n_class - 1项对应于这些分类器的对偶系数。
考虑一个三类问题,其中类0有三个支持向量v00、v01、v02,类1和类2分别有两个支持向量v10、v11和v20、v21。对于每个支持向量vij,有两个对偶系数。我们叫支持向量的系数vij分类器类之间我和kαi kj。然后dual_coef_看起来是这样的:
Scores and probabilities
SVC和NuSVC的decision_function方法为每个样本给出分别属于每个类的得分(或者在二进制情况下,每个样本给出一个得分)。当构造器函数选项probability = True 时,将启用类成员概率估计值(来自predict_proba和predict_log_proba方法)。在二进制情况下,使用Platt scale(支持向量机得分的逻辑回归)对概率进行校准,并通过对训练数据的额外交叉验证进行拟合。
对于大型数据集来说,Platt scaling中涉及的交叉验证的消耗是巨大的。此外,概率估计可能与得分不一致,因为通过argmax计算的得分可能和通过argmax计算的概率值不一致(例如在二分类问题中,样本根据predict方法可能被预测标记为属于某个类的概率小于predict_proba方法值的一半)。Platt的方法也有理论问题,如果需要信心分数,但这些分数不一定是概率,那么建议设置probability=False,以及使用decision_function而不是predict_proba。
Unbalanced problems
当数据集存在样本不平衡的问题,需要对某些特定的类或是独立样本给予更多的关注,我们可以使用class_weight和sample_weight关键字。
SVC(而不是NuSVC)在fit方法中实现关键字class_weight。它是一个形式为{class_label: value}的字典,其中value是一个大于零的浮点数,它将class_label类的参数C设置为C * value。
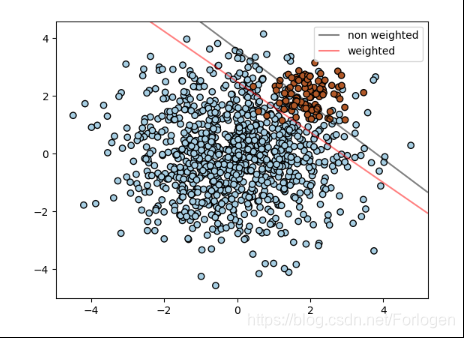
SVC、NuSVC、SVR、NuSVR和OneClassSVM也同样在fit方法中通过sample_weight对各个样本进行衡量。与class_weight类似,它们将第i个示例的参数C设置为C * sample_weight[i]。
Regression回归
支持向量机的分类方法可以推广到回归问题上,称为支持向量回归。支持向量分类(如上所述)生成的模型只依赖于训练数据的子集,因为构建模型的成本函数并不关心超出边界的训练点。类似地,支持向量回归生成的模型只依赖于训练数据的一个子集,因为用于构建模型的成本函数忽略了任何接近于模型预测的训练数据。
支持向量回归有三种不同的实现:SVR、NuSVR和LinearSVR。LinearSVR提供了比SVR更快的实现,但只考虑线性内核,而NuSVR实现的公式与SVR和LinearSVR略有不同。
与分类一样,fit方法将取X, y作为参数向量,只是在这种情况下,y应该是浮点值而不是整数值。
Density estimation,novelty detection
OneClassSVM实现了一个用于离群点检测的单类SVM.
Complexity
支持向量机的计算和存储需求随着训练向量的数量的增加而迅速增加。支持向量机的核心是一个二次规划问题(QP),它将支持向量从训练数据中分离出来。这个基于libsvm的实现所使用的QP求解器在O(n_features×n_samples2)和O(n_features×n_samples3)之间进行伸缩,这取决于实际使用libsvm缓存的效率(依赖于数据集)。如果数据非常稀疏,nfeatures应该被样本向量中非零特征的平均数量所代替。
对于线性情况,liblinear实现在linear SVC中使用的算法比基于libsvm的SVC实现要有效得多,并且几乎可以线性扩展到数百万个样本/特征。
Tipes on Practical Use
• 避免复制数据:对于SVC、SVR、NuSVC和NuSVR,如果传递给某些方法的数据不是C-ordered连续的,并且精度是双精度的,那么在调用底层C实现之前,将对其进行复制。您可以通过检查给定的numpy数组的flags属性来检查它是否是C-ordered的。
对于LinearSVC(和LogisticRegression),以数字数组形式传递的任何输入都将被复制并转换为liblinear内部稀疏数据表示(双精度浮点数和非零组件的int32索引)。如果您想要适应一个大规模的线性分类器,而不需要复制一个密集的numpy c-ordered双精度数组作为输入,我们建议使用SGDClassifier类。目标函数可以配置为几乎与线性svc模型相同。
• 内核缓存大小:对于SVC、SVR、NuSVC和NuSVR,对于较大的问题,内核缓存的大小对运行时间有很大的影响。如果有足够的RAM可用,建议将cache_size设置为比默认值200(MB)更高的值,比如500(MB)或1000(MB)。
• C的设置: C默认值为1,这是一个合理的默认选择。如果你有很多噪声数据,你应该减少它。相比于估计它和正则化相关性更大一些。
LinearSVC在C变大时对C的敏感性较低,当达到一定阈值后预测结果停止改善。与此同时,更大的C值需要更多的时间来训练,有时需要10倍的时间。
• 支持向量机算法对数据的规模敏感,因此强烈建议对数据进行规模调整。例如,将输入向量X上的每个属性缩放到[0,1]或[- 1,1],或者将其标准化为均值为0,方差为1。注意,必须对测试向量应用相同的缩放,才能获得有意义的结果。
• NuSVC/OneClassSVM/NuSVR中的参数nu近似于训练误差和支持向量的比例。
• 在SVC中,如果分类的数据是不平衡的(例如很多正的和很少负的),设置class_weight='balanced’或尝试不同的惩罚参数C。
• 底层实现的随机性:SVC和NuSVC的底层实现仅使用随机数生成器洗牌数据进行概率估计(当概率设置为True时)。这种随机性可以用random_state参数来控制。如果将概率设为False,这些估计器就不是随机的,random_state对结果没有影响。底层的OneClassSVM实现类似于SVC和NuSVC的实现。由于OneClassSVM没有提供概率估计,所以它不是随机的。
底层的LinearSVC实现使用随机数生成器来选择特征,当用双坐标下降(dual = True时)。因此,对于相同的输入数据,结果略有不同并不罕见。如果发生这种情况,尝试使用较小的tol参数。这种随机性也可以通过random_state参数来控制。当dual设置为False时,LinearSVC的底层实现不是随机的,random_state对结果没有影响。
• 使用LinearSVC通过(loss=‘l2’, penalty=’ L1 ', dual=False)提供的L1惩罚得到稀疏解,即只有特征权值的子集不同于零,并且对决策函数有贡献。增加 C 生成一个更复杂的模型(选择了更多的特性)。可以使用l1_min_c计算生成“null”模型的C值(所有权重均为零)。
Kernel functions 核函数
常用的核函数:
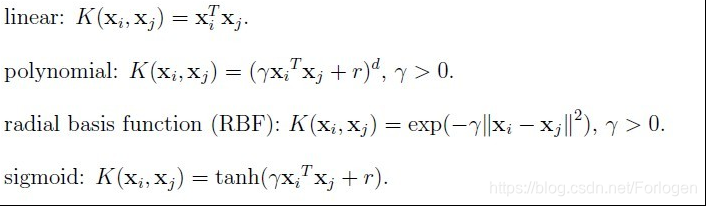
通过**kernel=**关键来选择不同的核函数
Custom kernels
你也可以通过编写python函数或设置kernel=‘precomputed’来定制自己的核函数。带有自定义核函数的分类器的行为与任何其他分类器基本都是一样的。
Using Python functions as kernels
您还可以通过将函数传递给构造函数中的关键字kernel来使用自己定义的内核。内核必须接受两个形为(n_samples_1, n_features), (n_samples_2, n_features)的矩阵作为参数,并返回一个形状的内核矩阵(n_samples_1, n_samples_2)。下面的代码定义了一个线性内核,并创建了一个分类器实例,将使用该内核:
import numpy as np
from sklearn import svm
def my_kernel(X, Y):
return np.dot(X, Y.T)
clf = svm.SVC(kernel=my_kernel)
Using the Gram matrix
设置kernel=‘precomputed’,在fit方法中传递Gram矩阵而不是X。此时必须提供所有训练向量与测试向量之间的核值。
clf = svm.SVC(kernel='precomputed')
# linear kernel computation
gram = np.dot(X, X.T)
clf.fit(gram, y)
Parameters of the RBF Kernel
在训练径向基函数(RBF)核支持向量机时,必须考虑两个参数:C和gamma。参数C对所有SVM核函数都是通用的,它利用训练样本的错误分类来抵消决策曲面的简单性。较小的C会使的决策边界光滑,而较大的C则主要是为了对所有训练实例进行正确分类。gamma定义了单个训练示例的影响程度,gama越大,其他的样本就越容易受到影响。选择合适的C和gamma对SVM的性能至关重要。建议使用网格搜索sklearn.model_selection.GridSearchCV以选择合适的gama和C的值。
关于SVM中公式的推导可参见另一篇 从零推导支持向量机
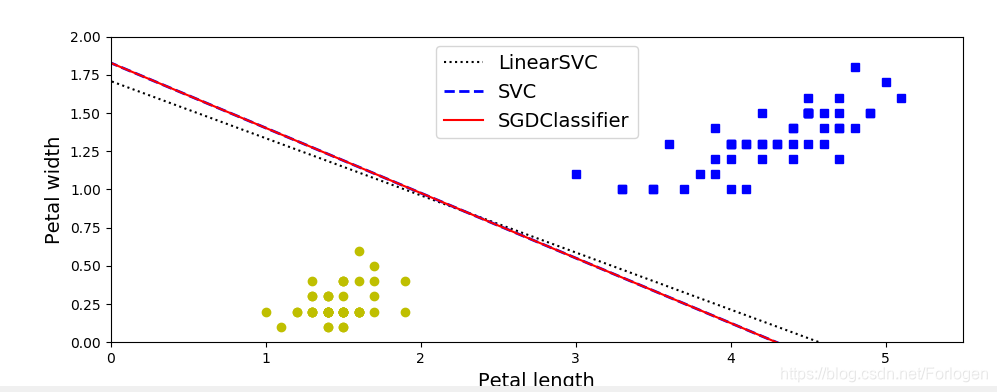
代码实例:
## # 以鸢尾花数据集为例,学习scikit-learn中关于SVM的用法
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
from sklearn.svm import SVC
from sklearn.linear_model import SGDClassifier
# 导入数据集
iris = datasets.load_iris()
X = iris["data"][:, (2, 3)] # petal length, petal width
y = iris["target"]
# 这里只判断是否是setosa或versicolor
setosa_or_versicolor = (y == 0) | (y == 1)
X = X[setosa_or_versicolor]
y = y[setosa_or_versicolor]
# 参数设置
C = 5
alpha = 1 / (C * len(X))
# 三种不同的分类器
lin_clf = LinearSVC(loss="hinge", C=C, random_state=42)
svm_clf = SVC(kernel="linear", C=C)
sgd_clf = SGDClassifier(loss="hinge", learning_rate="constant", eta0=0.001, alpha=alpha,
max_iter=100000, tol=-np.infty, random_state=42)
# 数据预处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 拟合数据
lin_clf.fit(X_scaled, y)
svm_clf.fit(X_scaled, y)
sgd_clf.fit(X_scaled, y)
# 输出对应的参数
print("LinearSVC: ", lin_clf.intercept_, lin_clf.coef_)
print("SVC: ", svm_clf.intercept_, svm_clf.coef_)
print("SGDClassifier(alpha={:.5f}):".format(sgd_clf.alpha), sgd_clf.intercept_, sgd_clf.coef_)
# 计算每个决策边界的斜率和截距
w1 = -lin_clf.coef_[0, 0]/lin_clf.coef_[0, 1]
b1 = -lin_clf.intercept_[0]/lin_clf.coef_[0, 1]
w2 = -svm_clf.coef_[0, 0]/svm_clf.coef_[0, 1]
b2 = -svm_clf.intercept_[0]/svm_clf.coef_[0, 1]
w3 = -sgd_clf.coef_[0, 0]/sgd_clf.coef_[0, 1]
b3 = -sgd_clf.intercept_[0]/sgd_clf.coef_[0, 1]
# 将决策边界转换到原始尺度
line1 = scaler.inverse_transform([[-10, -10 * w1 + b1], [10, 10 * w1 + b1]])
line2 = scaler.inverse_transform([[-10, -10 * w2 + b2], [10, 10 * w2 + b2]])
line3 = scaler.inverse_transform([[-10, -10 * w3 + b3], [10, 10 * w3 + b3]])
# 将决策边界可视化
plt.figure(figsize=(11, 4))
plt.plot(line1[:, 0], line1[:, 1], "k:", label="LinearSVC")
plt.plot(line2[:, 0], line2[:, 1], "b--", linewidth=2, label="SVC")
plt.plot(line3[:, 0], line3[:, 1], "r-", label="SGDClassifier")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs")
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo")
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.legend(loc="upper center", fontsize=14)
plt.axis([0, 5.5, 0, 2])
plt.show()
结果:















 2985
2985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









