






引言
因特网互联设备的发展,提供了大量易于访问的时序数据。越来越多的公司有兴趣去挖掘这类数据,意图从中获取一些有意义的洞悉,并据此做出决策。技术的最新进展提高了时序数据的收集、存储和分析效率,激发了人们对如何处理此类数据的考量。然而,大多数现有时序数据体系结构的处理能力,可能无法跟上时序数据的爆发性增长。
作为一家根植于数据的公司,Netflix已习惯于面对这样的挑战,多年来一直在推进应对此类增长的解决方案。该系列博客文章分为两部分发表,我们将分享Netflix在改进时序数据存储架构上的做法,如何很好地应对数据规模的成倍增长。
时序数据:会员视频观看记录
每天,Netflix的全部会员会观看合计超过1.4亿小时的视频内容。观看一个视频时,每位会员会生成多个数据点,存储为视频观看记录。Netflix会分析这些视频观看数据,实时准确地记录观看书签,并为会员提供个性化推荐。具体实现可参考如下帖子:
我们是如何知道会员观看视频的具体位置的?
如何帮助会员在Netflix上发现值得继续观看的视频?
视频观看的历史数据将会在以下三个维度上取得增长:
随时间的推进,每位会员会生成更多需要存储的视频观看数据。
随会员数量的增长,需要存储更多会员的视频观看数据。
随会员每月观看视频时间的增加,需要为每位会员存储更多的视频观看数据。
Netflix经过近十年的发展,全球用户数已经超过一亿,视频观看历史数据也在大规模增长。这篇博客帖子将聚焦于其中的一个重大挑战,就是我们的团队是如何解决视频观看历史数据的规模化存储的。
基本架构的初始设计

下图展示了最初使用的数据模型中的读操作和写操作流。
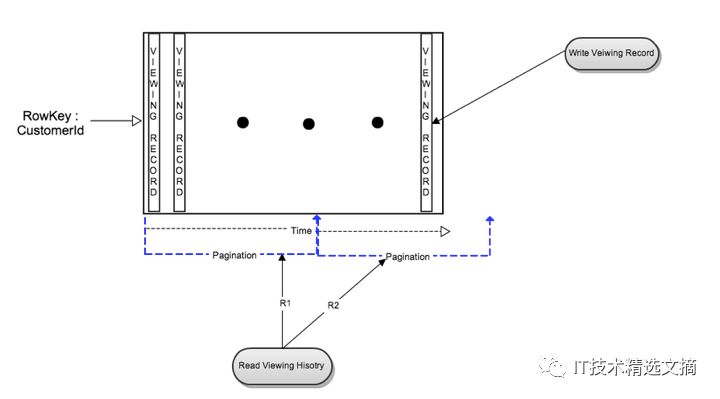
图1:单表数据模型
写操作流
当一位会员开始播放视频时,一条观看记录会以一个新列的方式插入。当会员暂停或停止观看视频流时,观看记录会做更新。在Cassandra中,对单一列值的写操作是快速和高效的。
读操作流

延迟的原因
下面介绍一些Cassandra的内部机制,进而理解为什么我们最初的简单设计会产生性能下降。随着数据的增长,SSTable的数量也随之增加。因为只有最近的数据是维护在内存中的,因此在很多情况下,检索观看历史记录时需要同时读取内存表和SSTable。这对于读取延迟具有负面影响。同样,随着数据的增长,合并(Compaction)操作将占用更多的IO和时间。此外,随着一行记录越来越宽,读修复(Read repair)和全列修复(Full column repair)也会变慢。
缓存层
Cassandra可以很好地对观看数据执行写操作,但是需要改进读操作上的延迟。为优化读操作延迟,我们考虑以增加写路径上的工作为代价,在Cassandra存储前增加了一个内存中的分片缓存层(即EVCache)。缓存实现为一种基本的键-值存储,键是CustomerId,值是观看历史数据的二进制压缩表示。每次Cassandra的写操作,将额外生成一次缓存查找操作。一旦缓存命中,直接给出缓存中的已有值。对于观看历史记录的读操作,首先使用缓存提供的服务。一旦缓存没有命中,再从Cassandra读取条目,压缩后插入到缓存中。
在添加了缓存层后,多年来Cassandra单表存储方法一直工作很好。在Cassandra集群上,基于CustomerId的分区提供了很好的扩展。到2012年,查看历史记录的Cassandra集群成为了Netflix的最大专用Cassandra集群之一。为进一步实现存储的规模化,团队需要实现集群的规模翻番。这意味着,团队需要冒险进入Netflix在使用Cassandra上尚未涉足的领域。同时,Netflix业务也在持续快速增长,其中包括国际会员的增长,以及企业即将推出的自制节目业务。
重新设计:实时存储和压缩存储

写操作流
对于新的观看记录,使用同上的方法写入到LiveVH。
读操作流
为有效地利用新设计的优点,团队更新了观看历史API,提供了读取近期数据和读取全部数据的选项。
读取近期观看历史:在大多数情况下,近期观看历史仅需从LiveVH读取。这限制了数据的规模,进而给出了更低的延迟。
读取完整观看历史:实现为对LiveVH和CompressVH的并行读操作。
考虑到数据是压缩的,并且CompressedVH具有更少的列,因此读取操作涉及更少的数据,这显著地加速了读操作。
CompressedVH更新流
在从LiveVH读取观看历史记录时,如果记录数量超过了一个预设的阈值,那么最近观看记录将由后台任务打包(roll up)、压缩并存储在CompressedVH中。打包数据存储在一个行标识为CustomerId的新行中。新打包的数据在写入后会给出一个版本,用于读操作检查数据的一致性。只有验证了新版本的一致性后,才会删除旧版本的打包数据。出于简化的考虑,在打包中没有考虑加锁,由Cassandra负责处理非常罕见的重复写问题(即以最后写入的数据为准)。
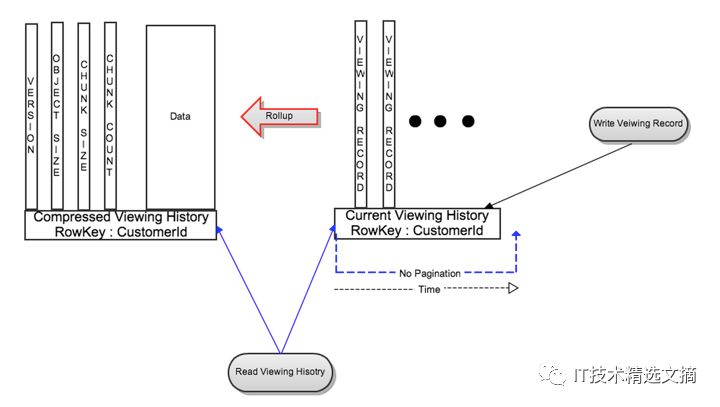
图2:实时数据和压缩数据的操作模型
如图2所示,CompressedVH的打包行中还存储了元数据信息,其中包括最新版本信息、对象规模和分块信息,细节稍后介绍。记录中具有一个版本列,指向最新版本的打包数据。这样,读取CustomerId总是会返回最新打包的数据。为降低存储的压力,我们使用一个列存储打包数据。为最小化具有频繁观看模式的会员的打包频率,LiveVH中仅存储最近几天的观看历史记录。打包后,其余的记录在打包期间会与CompressedVH中的记录归并。
通过分块实现自动扩展
通常情况是,对于大部分的会员而言,全部的观看历史记录可存储在一行压缩数据中,这时读操作流会给出相当不错的性能。罕见情况是,对于一小部分具有大量观看历史的会员,由于最初架构中的同一问题,从一行中读取CompressedVH的性能会逐渐降低。对于这类罕见情况,我们需要对读写延迟设置一个上限,以避免对通常情况下的读写延迟产生负面影响。
为解决这个问题,如果数据规模大于一个预先设定的阈值,我们会将打包的压缩数据切分为多个分块,并存储在不同的Cassandra节点中。即使某一会员的观看记录非常大,对分块做并行读写也会将读写延迟控制在设定的上限内。
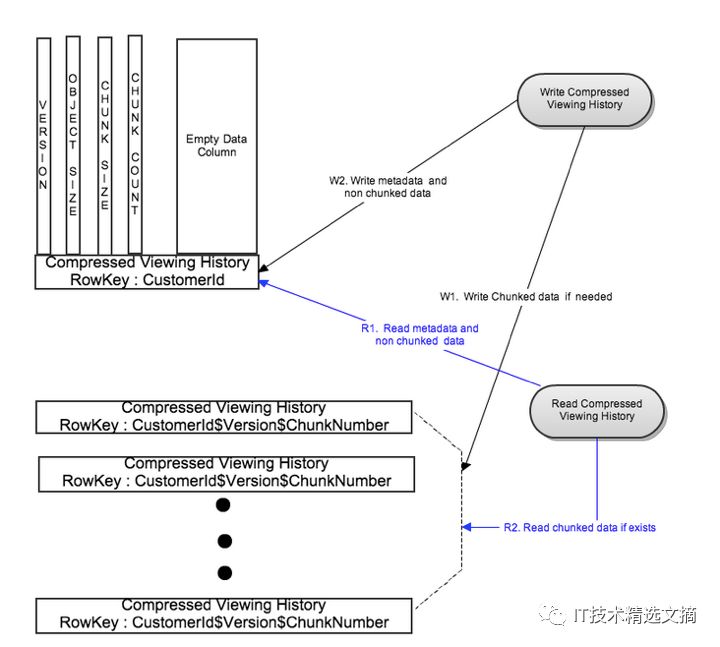
图3:通过数据分块实现自动扩展
写操作流
如图3所示,打包压缩数据基于一个预先设定的分块大小切分为多个分块。各个分块使用标识CustomerId$Version$ChunkNumber并行写入到不同的行中。在成功写入分块数据后,元数据会写入一个标识为CustomerId的单独行中。对非常大的打包观看数据,这一做法将写延迟限制为两次写操作。这时,元数据行实现为一个不具有数据列的行。这种实现支持对元数据的快速读操作。
为加快对通常情况(即经压缩的观看数据规模小于预定的阈值)的处理,我们将元数据与观看数据合并为一行,消除查找元数据的开销,如图2所示。
读操作流
在读取时,首先会使用行标识CustomerId读取元数据行。对于通常情况,分块数是1,元数据行中包括了打包压缩观看数据的最新版本。对于罕见情况,存在多个压缩观看数据的分块。我们使用元数据信息(例如版本和分块数)对不同分块生成不同的行标识,并行读取所有的分块。这将读延迟限制为两次读操作。
改进缓存层
为了支持对大型条目的分块,我们还改进了内存中的缓存层。对于存在大量观看历史的会员,整个压缩的观看历史可能无法置于单个EVCache条目中。因此,我们采用类似于对CompressedVH模型的做法,将每个大型缓存条目分割为多个分块,并将元数据存储在首个分块中。
结果
在引入了并行读写、数据压缩和数据模型改进后,团队达成了如下目标:
通过数据压缩,实现了占用更少的存储空间;
通过分块和并行读写,给出了一致的读写性能;
对于通常情况,延迟限制为一次读写。对于罕见情况,延迟限制为两次读写。
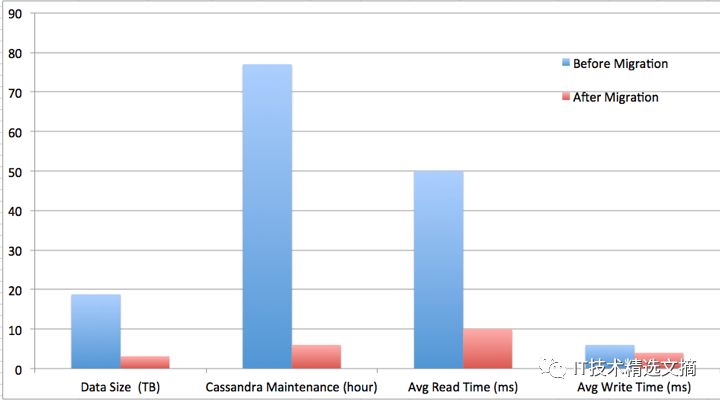
图4:运行结果
团队实现了数据规模缩减约6倍,Cassandra维护时间降低约13倍,平均读延迟降低约5倍,平均写时间降低约1.5倍。更为重要的是,团队实现了一种可扩展的架构和存储空间,可适应Netflix观看数据的快速增长。
公众号推荐:
公众号:VOA英语每日一听
微信号: voahk01
可长按扫码关注,谢谢















 2545
2545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









