






在命令行终端上工作时,经常会碰到一个头疼的问题就是中文乱码。今天对乱码这一块儿的问题做了一个梳理,留作后用,也希望对读者有所帮助。
这里我所理解的牵涉编码的地方一共有五处:
- Python代码文件前两行声明的编码
- Python代码文件实际存储所使用的编码
- Vim的显示编码
- Linux系统的文件编码
- SecureCRT等终端设置的显示编码
严格来讲,五码一致的时候,如果文件没有损坏,应该是能够正常显示了。
先介绍一些背景知识:
一、Python内部编码
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码
代码中字符串的默认编码与代码文件本身的编码一致。
如果字符串是这样定义:s=u'中文',则该字符串的编码就被指定为unicode了,即python的内部编码,而与代码文件本身的编码无关。因此,对于这种情况做编码转换,只需要直接使用encode方法将其转换成指定编码即可。
(参考链接:http://www.jb51.net/article/17560.htm)
二、Python编码声明
如果python代码文件中包含中文,就一定要在代码文件的前两行(注意:一定要是前两行)做出编码声明,否则python代码默认采用ASCII保存,这样遇到中文字符就会报错。在代码头部声明编码的方式有三种:
- # coding=<encoding name>
- # -*- coding: <encoding name> -*-
- # vim: set fileencoding=<encoding name>
三、Vim中有关编码的选项
在 Vim 中,有四个与编码有关的选项,它们是:fileencodings、fileencoding、encoding 和 termencoding。
encoding 是 Vim 内部使用的字符编码方式。当我们设置了 encoding 之后,Vim 内部所有的 buffer、寄存器、脚本中的字符串等,全都使用这个编码。
termencoding 是 Vim 用于屏幕显示的编码,在显示的时候,Vim 会把内部编码转换为屏幕编码,再用于输出。
当 Vim 从磁盘上读取文件的时候,会对文件的编码进行探测。如果文件的编码方式和 Vim 的内部编码方式不同,Vim 就会对编码进行转换。转换完毕后,Vim 会将 fileencoding 选项设置为文件的编码。当 Vim 存盘的时候,如果 encoding 和fileencoding 不一样,Vim 就会进行编码转换。
编码的自动识别是通过设置fileencodings 实现的,注意是复数形式。fileencodings 是一个用逗号分隔的列表,列表中的每一项是一种编码的名称。当我们打开文件的时候,VIM 按顺序使用 fileencodings 中的编码进行尝试解码,如果成功的话,就使用该编码方式进行解码,并将 fileencoding 设置为这个值,如果失败的话,就继续试验下一个编码。
(参考链接:http://www.cnblogs.com/xuxm2007/archive/2012/07/18/2556653.html)
四、Linux系统的编码设置
Linux的系统编码设置可以通过设置locale来完成,直接在命令行敲locale,然后回车,即可查看当前系统的编码设置,与保存文件相关的设置是LC_CTYPE。
如LC_CTYPE=zh_CN.gb18030,即把系统的编码设置成为了gb18030。
Locale的详细说明可以参考:http://blog.csdn.net/angelseyes/article/details/4820586
下面结合一些实例来加深理解:
先看下面两个代码文件:

左边的文件名为 cp936.py,采用cp936编码,右边文件名为 utf-8.py,采用utf-8编码。
下面看看不同的系统编码和终端(secureCRT)编码设置下的情况:(后文有详细附图)
|
| 终端编码:gb18030 | 终端编码:UTF-8 | ||||
| 系统编码:gb18030 | cp936.py | cat | 正常 | cp936.py | cat | 乱码 |
| vim 打开 | 正常 | vim 打开 | 乱码 | |||
| | 正常 | | 乱码 | |||
| print decode | 正常 | print decode | 乱码 | |||
| utf-8.py | cat | 乱码 | utf-8.py | cat | 正常 | |
| vim 打开 | 正常 | vim 打开 | 乱码 | |||
| | 乱码 | | 正常 | |||
| print decode | 正常 | print decode | 乱码 | |||
| 系统编码:UTF-8 | cp936.py | cat | 正常 | cp936.py | cat | 乱码 |
| vim 打开 | 乱码 | vim 打开 | 正常 | |||
| | 正常 | | 乱码 | |||
| print decode | 乱码 | print decode | 正常 | |||
| utf-8.py | cat | 乱码 | utf-8.py | cat | 正常 | |
| vim 打开 | 乱码 | vim 打开 | 正常 | |||
| | 乱码 | | 正常 | |||
| print decode | 乱码 | print decode | 正常 | |||
可以看到左上和右下区中,因为系统编码和终端编码一致,所以绝大部分情况都是正常的,乱码的情况在于文件编码与系统编码不一致,导致不能正常显示。可以使用iconv命令将代码文件的编码转为跟系统一致,这样cat出来或者直接print就不会乱码了。
左下和右上区,因为系统编码和终端编码不一致,所以出现了大范围乱码,所以处理的首选方案是将系统的编码和终端的编码调到一致。当然这时候也有一些方法先让文件正常显示,但是要从根本上解决还是最好将系统编码与终端编码调到一致。
比如右上区,要使vim正常显示文件,只需要 set termencoding=utf-8,即把vim的显示编码调整为跟终端编码一致即可。
要解决print decode的乱码,只需将decode以后的unicode码再encode为终端编码即可正常显示。
要解决cat和直接print的乱码,就需要使用iconv命令将代码文件的编码转为与终端编码一致,就可以正常cat了。
附图:
系统编码:gb18030 终端编码:gb18030
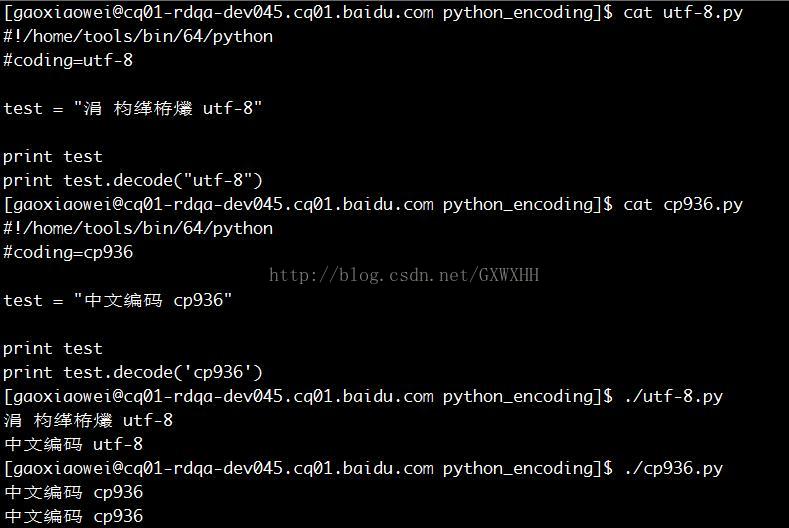
使用vim打开

系统编码:gb18030 终端编码:UTF-8
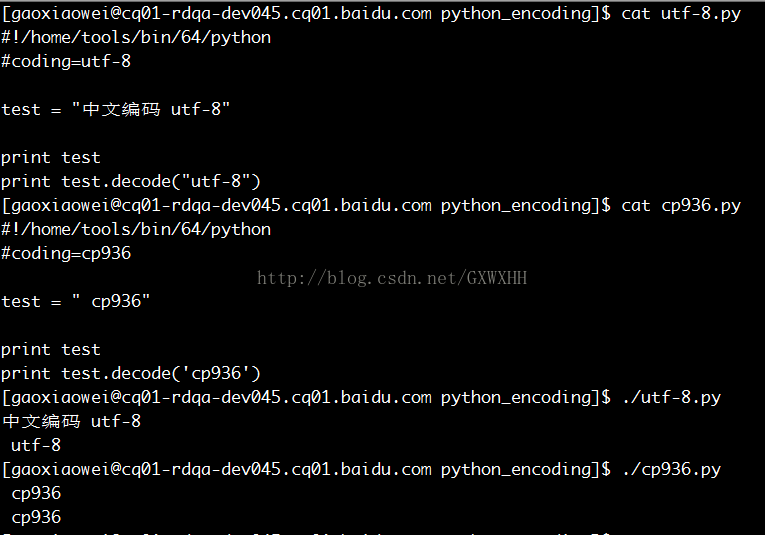
使用vim打开

系统编码:UTF-8 终端编码: gb18030
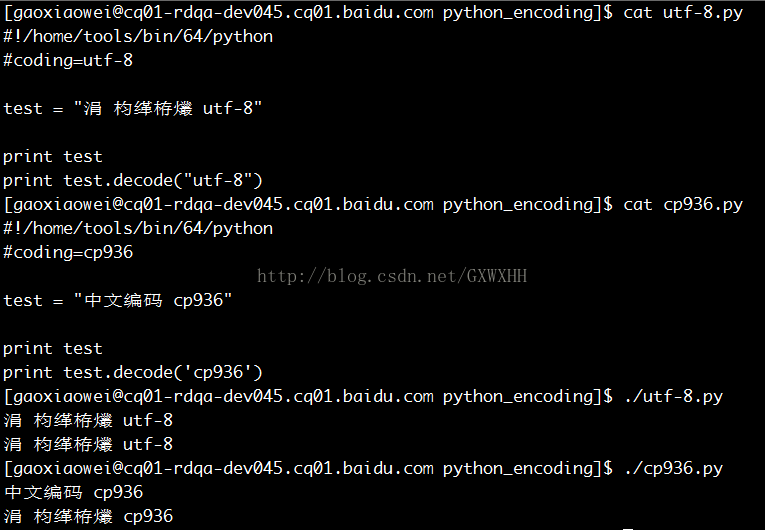
使用vim打开

系统编码:UTF-8 终端编码: UTF-8
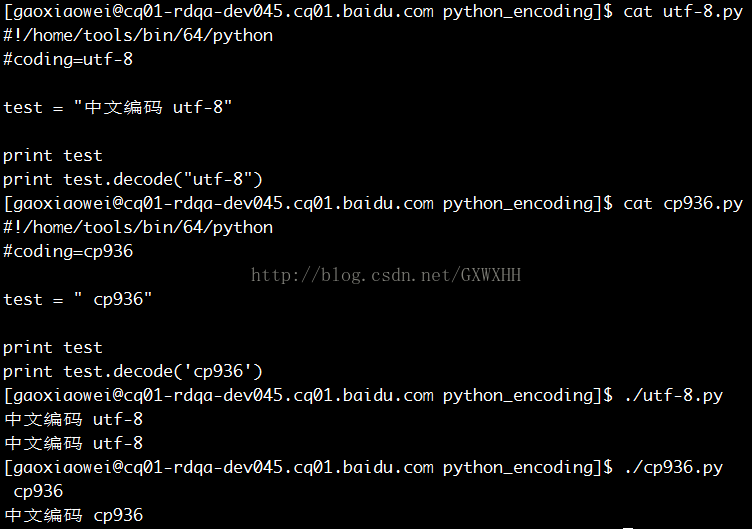
使用vim打开















 3827
3827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









