







python爬虫爬取csdn博客专家所有博客内容:
全部过程采取自动识别与抓取,抓取结果是将一个博主的所有 文章存放在以其名字命名的文件内,代码如下
#coding:utf-8
import urllib2
from bs4 import BeautifulSoup
import os
import re
#import sys
#reload(sys)
#sys.setdefaultencoding("utf-8")
def getPage(href): #伪装成浏览器登陆,获取网页源代码
headers = {
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
req = urllib2.Request(
url = href ,
headers = headers
)
try:
post = urllib2.urlopen(req)
except urllib2.HTTPError,e:
print e.code
print e.reason
return post.read()
url = 'http://blog.csdn.net/experts.html'
def getEvery(url):
hrefList = []
page = BeautifulSoup(getPage(url))
div = page.find('div',class_='side_nav')
liList = div.find_all('li')
for li in liList:
href = 'http://blog.csdn.net' + li.a.get('href')
if href!='http://blog.csdn.net/experts.html':
hrefList.append(href)
return hrefList
#第一部分:得到首页博客专家各个系列链接
#===============================================================================
def getAll(href): #得到每个类别所有专家的姓名和博客首页地址
page=BeautifulSoup(getPage(href)) #得到移动专家首页源代码,并beautifulsoup化
div = page.find('div',class_='list_3',id='experts')
for li in div.find_all('li'):
name = li.get_text()
href = li.a.get('href')
getBlog(name,href)
#第二部分:得到每类所有专家的姓名和首页链接
#===============================================================================
def getPageNum(href):
num =0
page = getPage(href)
soup = BeautifulSoup(page)
div = soup.find('div',class_='pagelist')
if div:
result = div.span.get_text().split(' ')
list_num = re.findall("[0-9]{1}",result[3])
for i in range(len(list_num)):
num = num*10 + int(list_num[i]) #计算总的页数
return num
else:
return 0
def getText(name,url):
page = BeautifulSoup(getPage(url))
span_list = page.find_all('span',class_='link_title')
div_list = page.find_all('div',class_='article_description')
k =0
str1 = 'none'
fp = open("text\%s.txt" % name,"a")
# 获取文章内容和内容
for div in div_list:
title = span_list[k].a.get_text().strip()
text = div.get_text()
title = title.encode('utf-8') #转换成utf-8编码,否则后文写不到文件里
text = text.encode('utf-8')
#print title
k+=1
fp.write(str(title) + '\n' + str(text) + '\n')
fp.write('===========================================' + '\n')
fp.close()
def getBlog(name,href):
i =1
for i in range(1,(getPageNum(href)+1)):
url = href + '/article/list/' + str(i)
print url
getText(name,url)
i+=1
print href,'======================================OK'
#第三部分:得到每类所有专家的博客内容链接
#===============================================================================
if __name__=="__main__":
hrefList = getEvery(url)
for href in hrefList:
getAll(href)
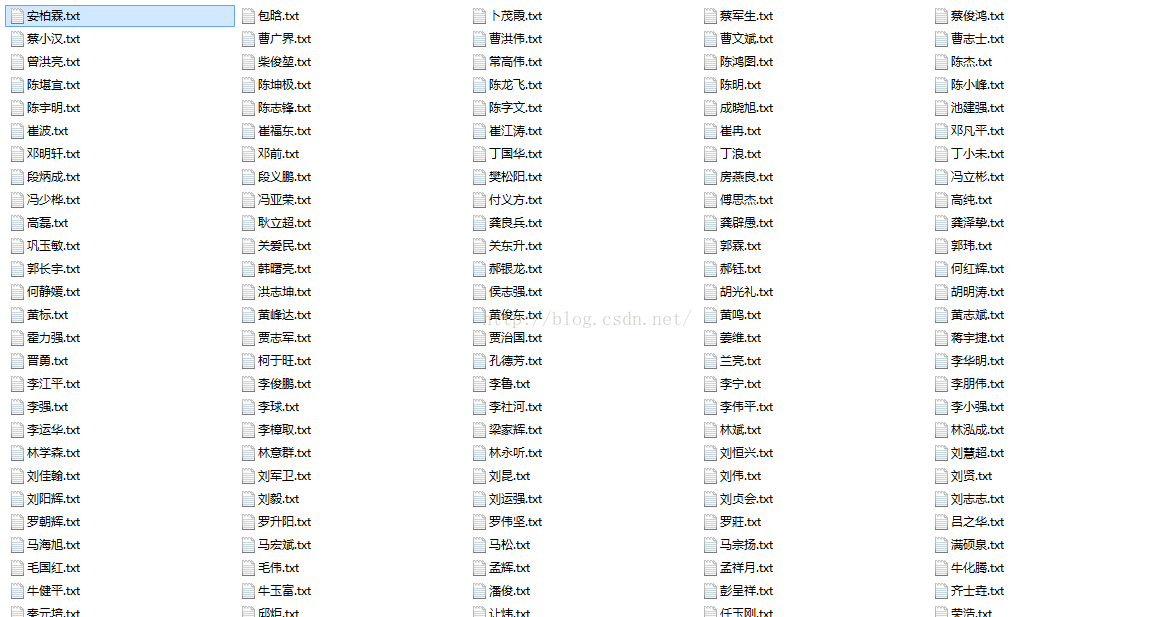
结果如下:

扫一扫 关注微信公众号!号主 专注于搜索和推荐系统,尝试使用算法去更好的服务于用户,包括但不局限于机器学习,深度学习,强化学习,自然语言理解,知识图谱,还不定时分享技术,资料,思考等文章!
【技术服务】,详情点击查看:https://mp.weixin.qq.com/s/PtX9ukKRBmazAWARprGIAg















 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









