







1.简介
(1) 贝叶斯分类器的分类原理发源于古典概率理论,是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。朴素贝叶斯分类器(Naive Bayes Classifier)做了一个简单的假定:给定目标值时属性之间相互条件独立,即给定元组的类标号,假定属性值有条件地相互独立,即在属性间不存在依赖关系。朴素贝叶斯分类模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。
(2) Mahout 实现了Traditional Naive Bayes 和Complementary Naive Bayes,后者是在前者的基础上增加了结果分析功能(Result Analyzer).
(3) 主要相关的Mahout类:
org.apache.mahout.classifier.naivebayes.NaiveBayesModel
org.apache.mahout.classifier.naivebayes.StandardNaiveBayesClassifier
org.apache.mahout.classifier.naivebayes.ComplementaryNaiveBayesClassifier
2.数据
使用20 newsgroups data (http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz) ,数据集按时间分为训练数据和测试数据,总大小约为85MB,每个数据文件为一条信息,文件头部几行指定消息的发送者、长度、类型、使用软件,以及主题等,然后用空行将其与正文隔开,正文没有固定的格式。
3.目标
根据新闻文档内容,将其分到不同的文档类型中。
4.程序
使用Mahout自带示例程序,主要的训练类和测试类分别为TrainNaiveBayesJob.java和TestNaiveBayesDriver.java,JAR包为mahout-core-0.7-job.jar,详细代码见(mahout-distribution-0.7/core/src/main/java/org/apache/mahout/classifier/naivebayes/trainning,mahout-distribution-0.7/core/src/main/java/org/apache/mahout/classifier/naivebayes/test).
5.步骤
(1) 数据准备
①将20news-bydate.tar.gz解压,并将20news-bydate中的所有子文夹中的内容复制到20news-all中,该步骤已经完成,20news-all文件夹存放在hdfs:/share/data/ Mahout_examples_Data_Set中
②将20news-all放在hdfs的用户根目录下
user@hadoop:~/workspace$hadoop dfs -cp /share/data/Mahout_examples_Data_Set/20news-all .
③从20newsgroups data创建序列文件(sequence files)
user@hadoop:~/workspace$mahout seqdirectory -i 20news-all -o 20news-seq
④将序列文件转化为向量
user@hadoop:~/workspace$mahout seq2sparse -i ./20news-seq -o ./20news-vectors -lnorm -nv -wt tfidf
⑤将向量数据集分为训练数据和检测数据,以随机40-60拆分
user@hadoop:~/workspace$mahout split -i ./20news-vectors/tfidf-vectors --trainingOutput ./20news-train-vectors --testOutput ./20news-test-vectors --randomSelectionPct 40 --overwrite --sequenceFiles -xm sequential
(2)训练朴素贝叶斯模型
user@hadoop:~/workspace$mahout trainnb -i ./20news-train-vectors -el -o ./model -li ./labelindex -ow -c
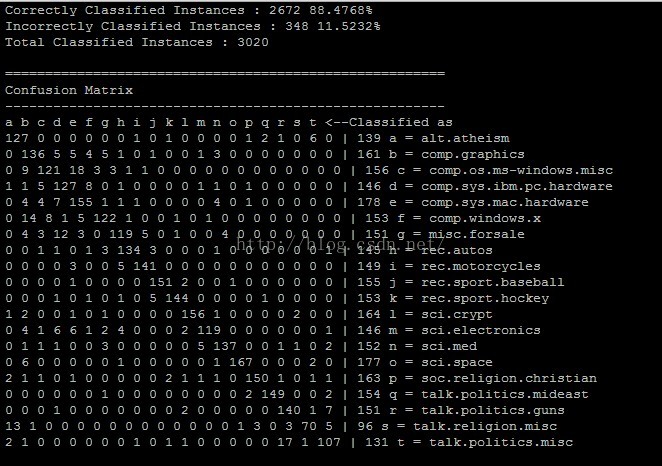
(3)检验朴素贝叶斯模型
user@hadoop:~/workspace$mahout testnb -i ./20news-train-vectors -m ./model -l ./labelindex -ow -o 20news-testing -c
结果如下:
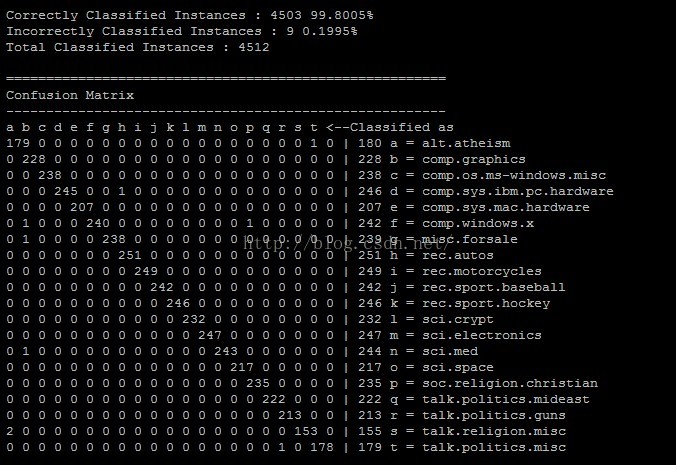
(4)检测模型分类效果
user@hadoop:~/workspace$mahout testnb -i ./20news-test-vectors -m ./model -l ./labelindex -ow -o ./20news-testing -c
结果如下:
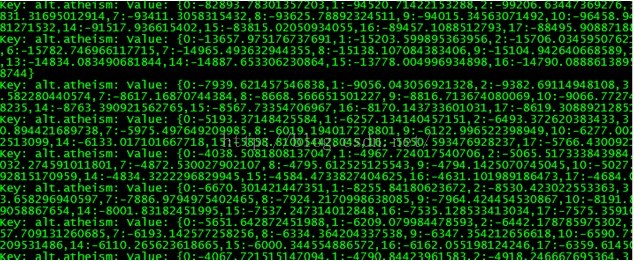
(5)查看结果,将序列文件转化为文本
user@hadoop:~/workspace$mahout seqdumper -i ./20news-testing/part-m-00000 -o ./20news_testing.res
user@hadoop:~/workspace$cat 20news_testging.res
结果如下:

扫一扫 关注微信公众号!号主 专注于搜索和推荐系统,尝试使用算法去更好的服务于用户,包括但不局限于机器学习,深度学习,强化学习,自然语言理解,知识图谱,还不定时分享技术,资料,思考等文章!
【技术服务】,详情点击查看:https://mp.weixin.qq.com/s/PtX9ukKRBmazAWARprGIAg















 2340
2340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









