







另外一篇关于Hive的表,外部表,分区,桶的理解的博客:点击阅读
本文所需要的HIveQL源码和所需的测试用例github地址为:点击查看
一:Hive中的数据类型
Hive支持两种数据类型,一类叫原子数据类型,一类叫复杂数据类型。
原子数据类型包括数值型、布尔型和字符串类型,具体如下表所示:
基本数据类型 | ||
类型 | 描述 | 示例 |
TINYINT | 1个字节(8位)有符号整数 | 1 |
SMALLINT | 2字节(16位)有符号整数 | 1 |
INT | 4字节(32位)有符号整数 | 1 |
BIGINT | 8字节(64位)有符号整数 | 1 |
FLOAT | 4字节(32位)单精度浮点数 | 1.0 |
DOUBLE | 8字节(64位)双精度浮点数 | 1.0 |
BOOLEAN | true/false | true |
STRING | 字符串 | ‘xia’,”xia” |
上表我们看到hive不支持日期类型,在hive里日期都是用字符串来表示的,而常用的日期格式转化操作则是通过自定义函数进行操作。
hive是用java开发的,hive里的基本数据类型和java的基本数据类型也是一一对应的,除了string类型。有符号的整数类型:TINYINT、SMALLINT、INT和BIGINT分别等价于java的byte、short、int和long原子类型,它们分别为1字节、2字节、4字节和8字节有符号整数。Hive的浮点数据类型FLOAT和DOUBLE,对应于java的基本类型float和double类型。而hive的BOOLEAN类型相当于java的基本数据类型boolean。
对于hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
Hive支持基本类型的转换,低字节的基本类型可以转化为高字节的类型,例如TINYINT、SMALLINT、INT可以转化为FLOAT,而所有的整数类型、FLOAT以及STRING类型可以转化为DOUBLE类型,这些转化可以从java语言的类型转化考虑,因为hive就是用java编写的。当然也支持高字节类型转化为低字节类型,这就需要使用hive的自定义函数CAST了。
复杂数据类型包括数组(ARRAY)、映射(MAP)和结构体(STRUCT),具体如下表所示:
复杂数据类型 | ||
类型 | 描述 | 示例 |
ARRAY | 一组有序字段。字段的类型必须相同 | Array(1,2) |
MAP | 一组无序的键/值对。键的类型必须是原子的,值可以是任何类型,同一个映射的键的类型必须相同,值得类型也必须相同 | Map(‘a’,1,’b’,2) |
STRUCT | 一组命名的字段。字段类型可以不同 | Struct(‘a’,1,1,0) |
二:创建表操作实例
1:创建内部表student表
create table student(
id int,
name string,
age int)
comment 'this is student message table'
row format delimited fields terminated by '\t';student.txt数据内容如下:
1 WEEW 23
2 QVCD 32
3 sdfw 43
4 rfwe 12
加载数据(从本地加载数据):
<span style="font-size:14px;">load data local inpath '/home/thinkgamer/MyCode/hive/student.txt' into table student;</span>当然我们也可以从HDFS加载:
load data inpath '/file/student.txt' into table student;查看结果如下:
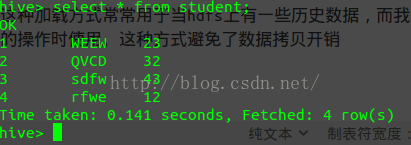
2:创建外部表external_student
comment 是注释说明,row... by "\t" 是指定行分隔符,这样在加载数据时只需保证源文件行的每个字段是以\t分割即可
#创建外部表
create external table external_student(
id int,
name string,
age int)
comment 'this is student message table'
row format delimited fields terminated by '\t'
location "/user/hive/external";hdfs dfs -put /home/thinkgamer/MyCode/hive/external_student /user/hive/external3:创建表copy_student,并从student表中导入数据
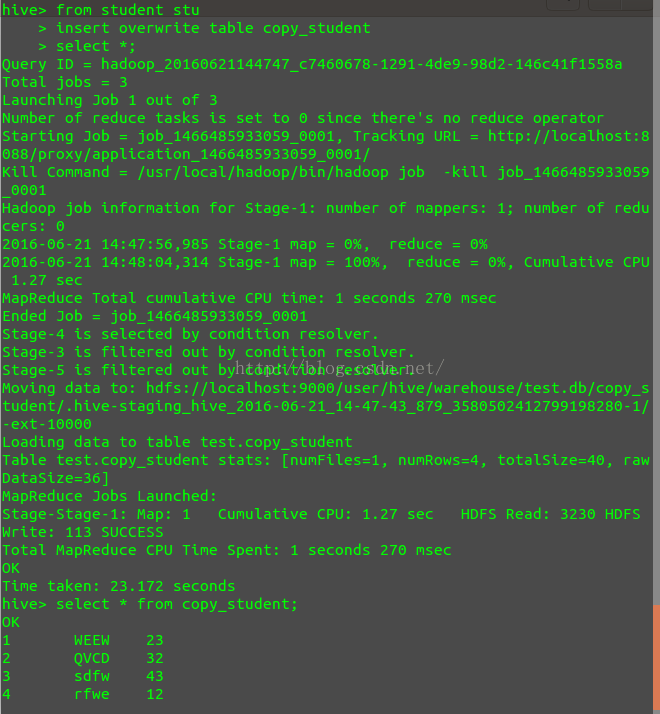
#创建copy_student表,并从student表中导入数据
create table copy_student(
id int,
name string,
age int)
comment 'this is student message table'
row format delimited fields terminated by '\t';from student stu insert overwrite table copy_student select *;过程如图:
4:创建复杂类型的表complex_student
COLLECTION ITEMS TERMINATED BY 指定的是列之间的分隔符
MAP KEYS TERMINATED BY 指的是MAP key value之间的分隔符
#创建复杂类型的表
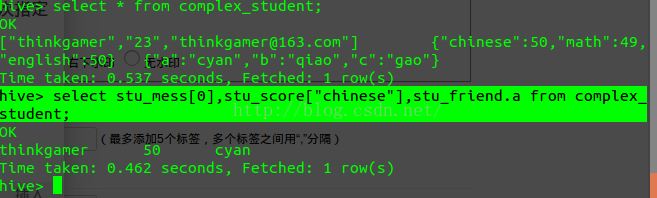
Create table complex_student(stu_mess ARRAY<STRING>,
stu_score MAP<STRING,INT>,
stu_friend STRUCT<a:STRING,b :STRING,c:STRING>)
comment 'this is complex_student message table'
row format delimited fields terminated by '\t'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':';加载数据:
load data local inpath "/home/thinkgamer/MyCode/hive/complex_student" into table complex_student;comlex_student数据格式如下:
thinkgamer,23,thinkgamer@163.com chinese:50,math:49,english:50 cyan,qiao,gao
进行查询:
5:创建分区表
create table partition_student(
id int,
name string,
age int)
comment 'this is student message table'
Partitioned by (grade string,class string)
row format delimited fields terminated by "\t";数据源如下
partition_student
1 WEEW 23
2 QVCD 32
3 sdfw 43
4 rfwe 12
partition_student2
5 hack 43
6 spring 54
7 cyan 23
8 thinkgamer 43
加载数据:
Loading data local inpath 'path' into table partition_student partition (grade=2013, class=34010301)
Loading data local inpath 'path' into table partition_student partition (grade=2013, class=34010302)查看分区:
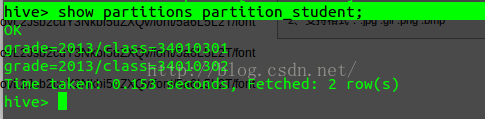
全部查询结果如下:
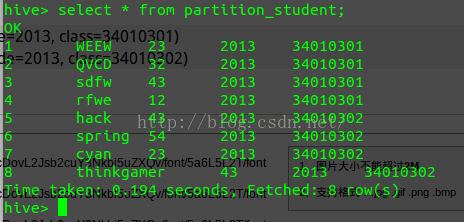
指定分区查询:
select * from partition_student where class=34010301;
so ,问题来了,hive1.1.1对于where的支持是个盲区,bug,每次执行where就会报错,所以这里小编就不过多解释,感兴趣的朋友可以自己百度
6:创建桶
创建临时表student_tmp:
create table student_tmp(
id int,
name string,
age int)
comment 'this is student message table'
row format delimited fields terminated by '\t';load data local inpath '/home/thinkgamer/MyCode/hive/student.txt' into table student_tmp;创建指定桶的个数的表student_bucket:
create table student_bucket(id int,
name string,
age int)
clustered by(id) sorted by(age) into 2 buckets
row format delimited fields terminated by '\t';设置环境变量:
set hive.enforce.bucketing = true;
从student_tmp 装入数据
from student_tmp
insert overwrite table student_bucket
select *;HDFS查看如下:

物理上,每个桶就是表(或分区)目录里的一个文件,桶文件是按指定字段值进行hash,然后除以桶的个数例如上面例子2,最后去结果余数,因为整数的hash值就是整数本身,上面例子里,字段hash后的值还是字段本身,所以2的余数只有两个0和1,所以我们看到产生文件的后缀是*0_0和*1_0,文件里存储对应计算出来的元数据。
Hive的桶,我个人认为没有特别的场景或者是特别的查询,我们可以没有必要使用,也就是不用开启hive的桶的配置。因为桶运用的场景有限,一个是做map连接的运算,我在后面的文章里会讲到,一个就是取样操作了,下面还是引用风生水起博文里的例子:
查看sampling数据:
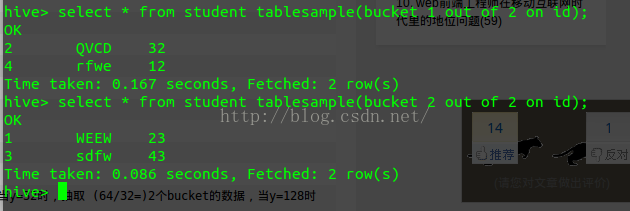
tablesample是抽样语句,语法:TABLESAMPLE(BUCKET xOUTOFy)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取 (64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例 如,table总bucket数为32,tablesample(bucket 3outof16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
三:修改表操作实例
1:hive表重命名
alter table movie_links rename to links;2:删除列
目前的links表有两列
hive> desc formatted links;
OK
# col_name data_type comment
id int
href string
alter table links replace columns(href string);hive>desc formatted links;
OK
# col_name data_type comment
href string 3:清空表
truncate table links;4:添加列
alter table test add columns(age int);5:insert语句
关于insert语句,可以用来在别的表查询结果插入hive 表,也可以通过insert将结果保存在hdfs上
具体可参考:http://blog.csdn.net/yeruby/article/details/23039009
插入一条记录:
create table test(id int,name string);
insert into table test(id,name) values(1,"sdfs");
hive> select * from test;
OK
1 sdfs
Time taken: 0.242 seconds, Fetched: 1 row(s)
insert into table test(id,name) values(2,"aaa"),(1,"bbb"),(3,"ccc");hive> select * from test;
OK
1 sdfs
2 aaa
1 bbb
3 ccc
Time taken: 0.215 seconds, Fetched: 4 row(s)四:Hive不支持的函数(持续更新)
1:hive不支持delete和update函数
HIVE是一个数据仓库系统,这就意味着它可以不支持普通数据库的CRUD操作。CRUD应该在导入HIVE数据仓库前完成。而且鉴于 hdfs 的特点,其并不能高效的支持流式访问,访问都是以遍历整个文件块的方式。hive 0.7 之后已经支持索引,但是很弱,尚没有成熟的线上方案。
倒是可以想尽办法来进行替换,比如说delete,我们可以进行查询,将不需要删除的数据集插入的table中,eg
我们的test表
hive> select * from test;
OK
1 aa 12
2 bb 23
Time taken: 0.207 seconds, Fetched: 2 row(s)
insert overwrite table test select test.* from test where id!=1;
hive> select * from test;
OK
2 bb 23
Time taken: 0.213 seconds, Fetched: 1 row(s













 1294
1294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









