







#Data flow
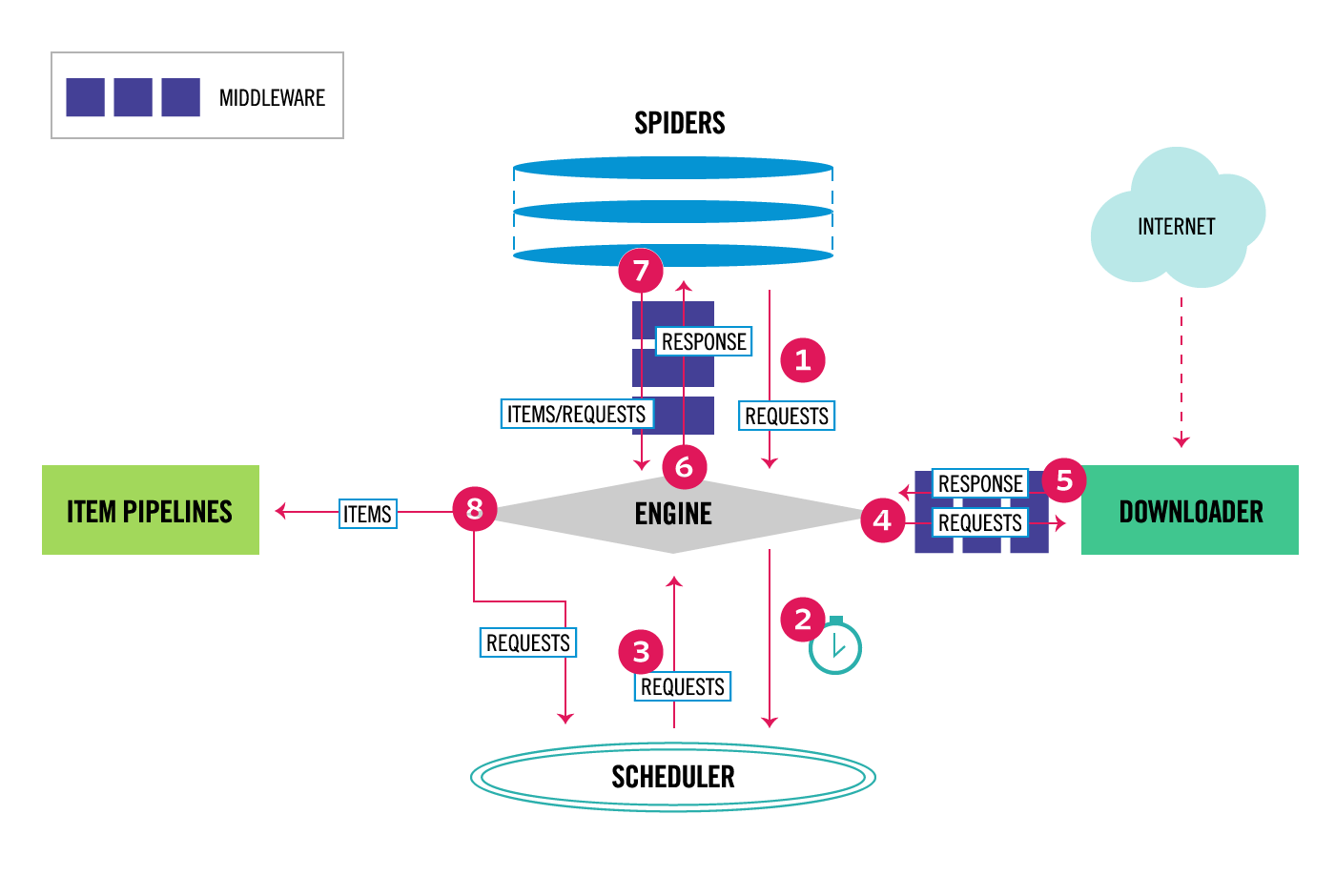
The data flow in Scrapy is controlled by the execution engine, and goes like this:
- The Engine gets the initial Requests to crawl from the Spider.
- The Engine schedules the Requests in the Scheduler and asks for the
next Requests to crawl. - The Scheduler returns the next Requests to the Engine.
- The Engine sends the Requests to the Downloader, passing through the
Downloader Middleware (requests direction). - Once the page finishes downloading the Downloader generates a
Response (with that page) and sends it to the Engine, passing
through the Downloader Middleware (response direction). - The Engine receives the Response from the Downloader and sends it to
the Spider for processing, passing through the Spider Middleware
(input direction). - The Spider processes the Response and returns scraped items and new
Requests (to follow) to the Engine, passing through the Spider
Middleware (output direction). - The Engine sends processed items to Item Pipelines, then send
processed Requests to the Scheduler and asks for possible next
Requests to crawl. - The process repeats (from step 1) until there are no more requests
from the Scheduler.
Scrapy的架构初探
https://zhuanlan.zhihu.com/p/21320942















 5351
5351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









