









再认识redis集群前,若想先知道redis单机版的可查看,springboot整合redis。好了,下面开始了。
每个redis实例可称为一个节点,安装redis并以默认端口启动是节点,不关闭,以另一个端口启动,是一个新节点。在另一台机器安装redis并启动,也是一个新节点。
节点分为主节点 (master) ,从节点 (slave) ,数据从主节点向多个从节点上同步 。
redis3.0开始支持集群,redis集群是没有统一的入口的,客户端(client)连接集群的时候连接集群中的任意节点(node)即可,集群内部的节点是相互通信的(PING-PONG机制)。
一,集群方式
1,主从模式
一个master可以拥有多个slave,但是一个slave只能对应一个master。这样,当某个slave挂了不影响其他slave的读和master的读和写,重新启动后会,数据会从master上同步过来。
在主从模式下,因为只有一个主节点可以写,而主,从节点都可以读,所以通常主节点负责写,从节点负责读。

但是,当唯一的master挂了以后,虽然这样并不影响slave的读,但redis也不再提供写服务,需要将master重启后,redis才重新对外提供写服务。
2,Sentinel模式
sentinel模式是建立在主从模式的基础上,避免单个master挂了以后,redis不能提供写服务。因为从节点上备份了主节点的所有数据,那么当master挂了以后,sentinel会在slave中选择一个作为master,并修改它们的配置文件,其他slave的配置文件也会被修改,比如slaveof属性会指向新的master,比如之前配置的密码。此时,客户端就不是直接连接Redis,而是连接sentinel的ip和port,由sentinel来提供具体Redis服务。
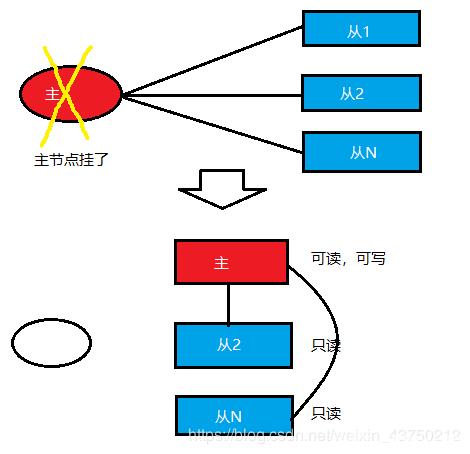
把之前挂了的master重新启动后,它将不再是master而是作为slave接收新的master的同步数据。
3,Cluster模式
Cluster模式是建立在Sentinel模式的基础上的,当数据多到需要动态扩容的时候,前面两种就不行了,需要对数据进行分片,根据一定的规则把redis数据分配到多台机器。

该模式就支持动态扩容,可以在线增加或删除节点,而且客户端可以连接任何一个主节点进行读写,不过此时的从节点仅仅只是备份的作用。至于为何能做到动态扩容,主要是因为Redis集群没有使用一致性hash,而是使用的哈希槽。Redis集群会有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,而集群的每个节点负责一部分hash槽。
那么这样就很容易添加或者删除节点, 比如如果我想新添加个新节点, 我只需要从已有的节点中的部分槽到过来;如果我想移除某个节点,就只需要将该节点的槽移到其它节点上,然后将没有任何槽的A节点从集群中移除即可。由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
需要注意的是,该模式下不支持同时处理多个key(如MSET/MGET),因为redis需要把key均匀分布在各个节点上,并发量很高的情况下同时创建key-value会降低性能并导致不可预测的行为。
简单配置一下Cluster模式:
首先下载redis并解压缩
下载:wget http://download.redis.io/releases/redis-5.0.4.tar.gz
解压: tar redis-5.0.4.tar.gz
然后进入redis目录编译Redis:make
然后你可以在不同ip建rides。
逐个修改redis配置
cd /usr/local/redis/9001vi redis.conf
打开配置文件,按i进入编辑模式,按照出现的顺序,主要需要修改的地方是
bind 192.168.119.128(绑定当前电脑的 IP,这是我虚拟机的,你绑定成你虚拟机的ip)
port 9001(因为我这是一台机器运行6个redis实例,所以要启动6个实例,得为它配置6个不同的端口,若你是6台机器,默认的端口就行,无需更改)
daemonize yes(这是设置是否后台启动 Redis,默认 no ,但是生产环境肯定要默认就开启 Redis,所以这里设置为 yes 。)
pidfile /var/run/redis_9001.pid(_9001这个一定要和第一个配置的端口一样)
dir /usr/local/redis-cluster/9001/data/(数据文件存放位置,我换成指定目录下存放)
appendonly yescluster-enabled yes(启动集群模式)
cluster-config-file nodes9001.conf(9001这个也要和之前的端口对应)
cluster-node-timeout 15000(超时时间)
完成以上修改,Esc退出编辑模式,输入:wq保存并退出。 类似同样的操作操作,在所有虚拟机运行。
启动所有redis程序 然后输入命令
redis-cli --cluster create 192.168.119.128:9001 192.168.119.128:9002 192.168.119.128:9003 192.168.119.128:9004 192.168.119.128:9005 192.168.119.128:9006 --cluster-replicas 1
然后测试即可。
1,故障转移机制详解
集群中的节点会向其它节点发送PING消息(该PING消息会带着当前集群和节点的信息),如果在规定时间内,没有收到对应的PONG消息,就把此节点标记为疑似下线。当被分配了slot槽位的主节点中有超过一半的节点都认为此节点疑似下线(就是其它节点以更高的频次,更频繁的与该节点PING-PONG),那么该节点就真的下线。其它节点收到某节点已经下线的广播后,把自己内部的集群维护信息也修改为该节点已事实下线。节点资格审查:然后对从节点进行资格审查,每个从节点检查最后与主节点的断线时间,如果该值超过配置文件的设置,那么取消该从节点的资格。准备选举时间:这里使用了延迟触发机制,主要是给那些延迟低的更高的优先级,延迟低的让它提前参与被选举,延迟高的让它靠后参与被选举。(延迟的高低是依据之前与主节点的最后断线时间确定的)选举投票:当从节点获取选举资格后,会向其他带有slot槽位的主节点发起选举请求,由它们进行投票,优先级越高的从节点就越有可能成为主节点,当从节点获取的票数到达一定数值时(如集群内有N个主节点,那么只要有一个从节点获得了N/2+1的选票即认为胜出),就会替换成为主节点。替换主节点:被选举出来的从节点会执行slaveof no one把自己的状态从slave变成master,然后执行clusterDelSlot操作撤销故障主节点负责的槽,并执行 clusterAddSlot把这些槽分配给自己,之后向集群广播自己的pong消息,通知集群内所有的节点,当前从节点已变为主节点。接管相关操作:新的主节点接管了之前故障的主节点的槽信息,接收和处理与自己槽位相关的命令请求。2,故障转移测试
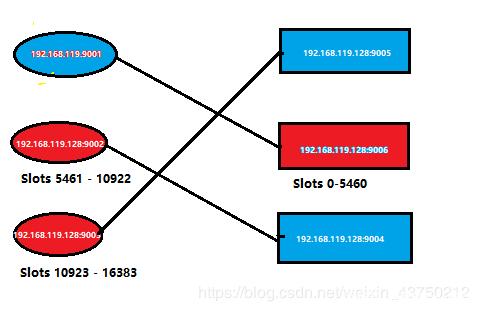
这是之前集群中具体节点的情况,我简化成如下,可以向上回看图片中的集群信息。
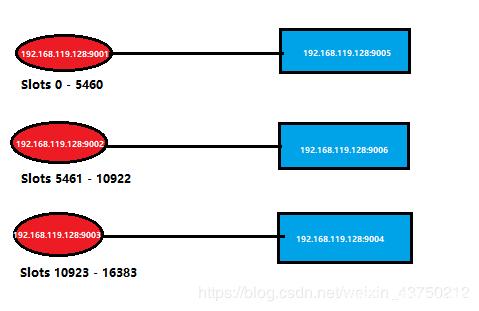
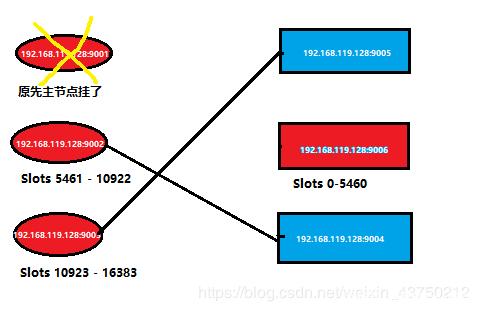
这里关闭该9001端口的进程,即模拟该主节点挂掉。
登录挂掉的redis节点,会被拒绝服务,通过还在正常运行的某个主节点进入,然后再次查看集群中的信息


简而言之,就是之前的集群信息变成了如下所示
现在,我重启刚才挂掉的主节点,重新查看集群内部的节点情况,具体情况如下图所示。
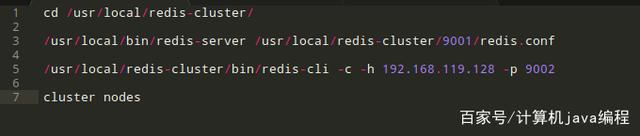
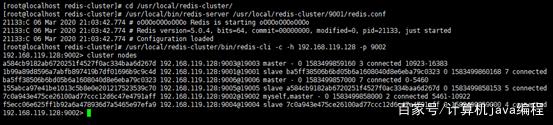
简而言之,现在集群内的节点情况如下















 1235
1235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









