






1.grep
全面搜索研究正则表达式并显示出来grep 命令是一
种强大的文本搜索工具 , 根据用户指定的“模式”对目
标文本进行匹配检查 , 打印匹配到的行由正则表达式
或者字符及基本文本字符所编写的过滤条件
grep 的格式
grep 匹配条件 处理文件
例如
grep root passwd
grep ^root passwd
grep root$ passwd
grep -i root passwd ##忽略大小写
grep -E “root|ROOT” passwd ##扩展,同时筛选root或ROOT
或是
egrep “root|ROOT” passwd ##扩展,同时筛选root或ROOT
grep -r root /etc ##递归查询/etc下的关于root的文件
grep -n root passwd ##显示匹配的行号
grep -B 数字 root passwd ##筛选并显示前n行
grep -A 数字 root passwd ##筛选并显示后n行
egrep “root|ROOT” passwd -v ##反选root或者ROOT
grep 中的正则表达式
^westos ##以westos开头的
westos$ ##以westos结尾的
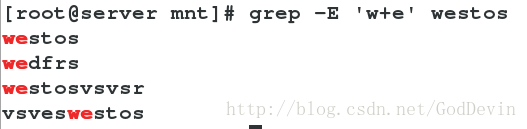
‘w….s’ ##w“中间四个任意”s
‘w…..’ ##w“后面五个任意”
‘…..s’ ##“前面五个任意”s
grep 中字符的匹配次数设定 要加-E
- 字符出现 [0- 任意次 ]
\? 字符出现 [0-1 次 ]
+ 字符出现 [1- 任意次 ]
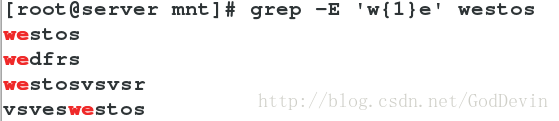
{n} 字符出现 [n 次 ]
|{m,n} 字符出现 [ 最少出现 m 次,最多出现 n 次 ]
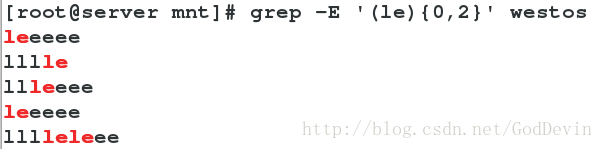
{0,n} 字符出现 [0-n 次 ]
{m,} 字符出现 [ 至少 m 次 ]
(xy){n}xy 关键字出现 [n 次 ]
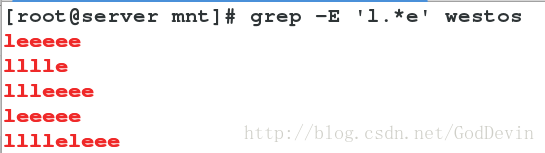
.* 关键字之间匹配任意字符




grep 中字符的匹配位置设定 要加-E
^ 关键字 ##以什么开头,最前头

关键字 $ ##以什么结尾,最终结尾

\< 关键字 ##以什么开头,前面仍可加
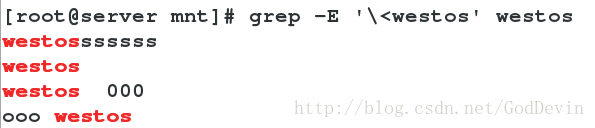
关键字 > ##以什么结尾,空格后仍可加

\< 关键字 > ##关键字,可添加东西

^关键字$ ##关键字,不能添加

grep 正则表达式与扩展正则表达式
正规的 grep 不支持扩展的正则表达式子 , 竖线是用于表示”
或”的扩展正则表达式元字符 , 正规的 grep 无法识别
加上反斜杠 , 这个字符就被翻译成扩展正则表达式 , 就像 egrep
和
grep -E 一样
2.sed行编辑器
stream editor
用来操作纯 ASCII 码的文本
处理时 , 把当 前处理的行存储在临时缓冲区中 , 称为“模式空
间” (pattern space) 可以指定仅仅处理哪些行
sed 符合模式条件的处理 不符合条件的不予处理
处理完成之后把缓冲区的内容送往屏幕
接着处理下一行 , 这样不断重复 , 直到文件末尾
Sed 命令格式
调用 sed 命令有两种形式:
sed [options] ‘command’ file(s)
sed [options] -f scriptfile file(s)
sed 对字符的处理
p 显示
d 删除
a 添加
c 替换
w 写入
i 插入
p 模式操作
sed -n ‘/:/p’ fstab ##抽出有:的行

sed -n ‘/UUID$/p’ fstab
sed -n ‘/^UUID/p’ fstab

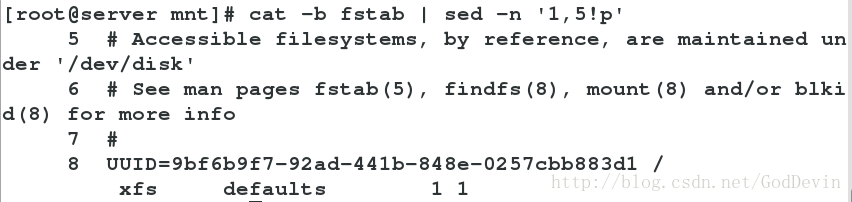
sed -n ‘2,6p’ fstab ##抽出2到6行显示

sed -n ‘2,6!p’ fstab ##抽出除了2到6行的显示
d 模式操作
sed ‘/^UUID/d’ /etc/fstab ##删除UUID开头的
sed ‘/^#/d’ /etc/fstab ##删除#开头的
sed ‘/^$/d’/etc/fstab ##删除空行
sed ‘1,4d’/etc/fstab ##删除1到4行
sed –n ‘/^UUID/!d’ /etc/fstab
a 模式操作
sed ‘/^UUID/a \hello sed /etc/fstab
sed ‘/^UUID/a \hello sed\nwestos /etc/fstab’
i 模式操作
sed ‘/^UUID/i\hello sed\nwestos /etc/fstab’
c 模式操作
sed ‘/^UUID/c\hello sed\nwestos /etc/fstab’
w 模式操作
sed ‘/^UUID/w /tmp/fstab.txt’ /etc/fstab
sed -n’/^UUID/w /tmp/fstab.txt’ /etc/fstab
sed ‘/^UUID/=’/etc/fstab
sed ‘6r /etc/issue’ /etc/fstab
sed 的其他用法
sed -n ‘/^UUID/=’ fstab
sed -n -e ‘/^UUID/p’ -e ‘/^UUID/=’ fstab
sed -e ‘s/brown/green/; s/dog/cat/’ data
sed -f rulesfile file
sed ‘s/^\//#/’/etc/fstab
sed ‘s@^/@#@g’/etc/fstab
sed ‘s/\//#/’/etc/fstab
sed ‘s/\//#/g/’/etc/fstab
sed ‘G’ data
sed ‘
!G′datased‘=′data|sed‘N;s/\n//′sed−n‘
!
G
′
d
a
t
a
s
e
d
‘
=
′
d
a
t
a
|
s
e
d
‘
N
;
s
/
\n
/
/
′
s
e
d
−
n
‘
p’ data
awk 报告生成器
awk 处理机制 :awk 会逐行处理文本 , 支持在处理第一行之前做一些
准备工作 , 以及在处理完最后一行做一些总结性质的工作 , 在命令格式
上分别体现如下 :
BEGIN{}: 读入第一行文本之前执行 , 一般用来初始化操作{}: 逐行处理 ,
逐行读入文本执行相应的处理 , 是最常见的编辑指令快
END{}: 处理完最后一行文本之后执行 , 一般用来输出处理结果
awk 基本用法
linux 上面默认使用 gawk
awk ‘{print FILENAME}’ passwd
awk ‘{print 第 “NR” 行 , 有 “NF” 列 }’
awk ‘BEGIN{print NAME}’
awk ‘END{print WESTOS}’
awk -F : ‘BEGIN{print NAME}{print 1}END{WESTOS}’
awk ‘/bash
1}END{WESTOS}’ awk ‘/bash
/’
awk -F : ‘/bash
/print$1′awk‘BEGINa=34;printa+12′awk−F:‘/ro/print′/etc/passwdawk−F:‘/[a−d]/print$1,$6′passwd.txtawk−F:‘/a|nologin
/
p
r
i
n
t
$
1
′
a
w
k
‘
B
E
G
I
N
a
=
34
;
p
r
i
n
t
a
+
12
′
a
w
k
−
F
:
‘
/
r
o
/
p
r
i
n
t
′
/
e
t
c
/
p
a
s
s
w
d
a
w
k
−
F
:
‘
/
[
a
−
d
]
/
p
r
i
n
t
$
1
,
$
6
′
p
a
s
s
w
d
.
t
x
t
a
w
k
−
F
:
‘
/
a
|
n
o
l
o
g
i
n
/{print
1,
1
,
7}’ passwd.txt
awk -F : ‘
6 /bin
6
/
b
i
n
/{print
1,
1
,
6}’
awk -F : ‘
7! /nologin
7
!
/
n
o
l
o
g
i
n
/{print
1,
1
,
7}’ passwd.txt














 7853
7853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









