







目录索引
1.背景知识
在我们谈论决策树的时候我们先来玩一个游戏好咯。
2016年是奥运年,我最喜欢的两个运动员,(内心戏:当然是女的咯。因为我也是妹子,哈哈哈。)一个当然是女王隆达罗西,还有一个就是伊辛巴耶娃咯。
好的,现在我们就来玩猜运动员的游戏。
我在心里想一个运动员的名字,比如说就是伊辛巴耶娃。然后你有20次的提问机会,但是我只能回答你是还是不是这两种可能。
我们可以这样对话:
你:男的?
我:不是
你:参加过往届奥运会?
我:是
你:参加过两次?
我:不是
你:参加过三次?
我:是
你:参加的是田赛
我:是
你:耶辛巴伊娃
我:恭喜你,答对了!
以上我们玩的这个过程就有一点点像决策树算法。
我们经常使用决策树处理分类问题,近年来,决策树也是经常使用的数据挖掘的算法。
决策树的概念是非常简单的,我们可以通过一个图形来快速的了解决策数。我用了《机器学习与实战》这本书的内容来讲解。如图1所示,下面的这个流程图就是一个决策树,正方形代表的是判断模块(decision block),椭圆形代表的是终止模块(terminating block),表示已经得出结论,可以终止运行,从判断模块引出的左右箭头称作分支(branch)
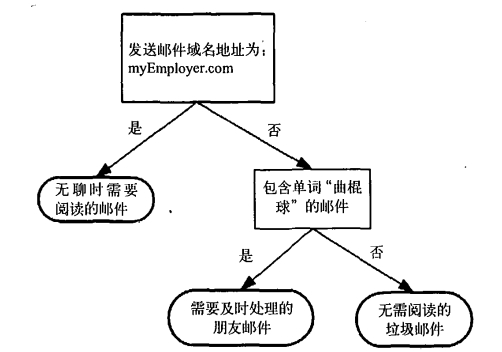
这是一个假想的邮件分类系统。首先这个系统会检测发送邮件的域名地址,如果地址为myEmployer.com 则将邮件归类到“无聊时需要阅读的邮件”如果没有这个域名我们就检查邮件中的内容是不是包含了“曲棍球”的邮件。如果包含则把这些邮件放置在“需要及时处理的朋友邮件”,否则就把这些邮件归类到“无需阅读的垃圾邮件”
2.构造决策树
根据上面的描述我们已经发现构造决策树做分类的时候首要目的就是每次分类的时候都能找到最容易区分一个集合和另一个集合的特征。在上面例子中,我们首先就是查找邮件的域名,在第一次分类的时候,邮件的域名就是我们最重要的分类特征。
为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征,完成测试之后,原始数据集就被划分为几个数据子集。根据我们挑选出的最佳特征,这些数据会被分成两类。我们分别检测这两类,如果类别相同则不需要再次划分,如果类别不同,我们要重复上面的步骤。就是在被划分出的子集当中在挑选其他的重要特征把这些数据在细分成其他的类别。
根据这个描述,我们可以很容易发现这个过程就是一个递归的过程,怎么找到这些最佳特征,我们要做的事情就需要了解一些数学概念。我们需要用到信息论的知识来划分数据集。
3.一些需要了解的数学概念
划分数据集的原则就是:将无序的数据变得更加有序。我们可以有多种方法来划分数据,在这里我们构建决策树算法使用的是信息论划分数据集,然后编写代码将理论应用到具体的数据集上,然后编写代码构建决策树。我们在组织杂乱无章的数据时使用信息论度量信息。
比如我给出一条信息:
我爱你1314.
这就是一条简单的信息,这个时候我们可以对这个信息做一些分类,比如说找出这句话中的动词,数字,以及代词,名词等。我们要知道的就是 信息处理就是将杂乱无章的信息用数理统计的方法表示出来。
在这里我们可以将这个信息分成 三类: 代词(名词),动词,以及数字,我们用X1表示代词,X2表示动词,X3表示数字,p(xi)表示的是这个分类在这个信息当中出现的概率。那么我们就可以将信息定义为:
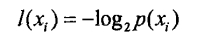
高中毕业的人都知道吧,概率p(Xi)是一个分数,然后对数函数以2为基底,它是比1大的,如果幂是分数,基底是大于1的那个这个值是个负数。为了方便处理,前面添加负号。
信息熵,简称熵是用来表示信息的期望值得。
3.1 信息熵
根据百科词条的定义,我们先来看一下信息论中的一下基本概念
信息论:
信息论是运用概率论与数理统计的方法研究信息、信息熵、通信系统、数据传输、密码学、数据压缩等问题的应用数学学科。信息系统就是广义的通信系统,泛指某种信息从一处传送到另一处所需的全部设备所构成的系统。
1948年,香农提出了“信息熵”的概念,解决了对信息的量化度量问题。信息熵这个词是C.E.香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述信源的不确定度。
我们可以用信息熵来度量信息量的多少。
在给出信息熵的计算公式的时候,我想先说几个基本的概念,以便于你理解信息熵的计算公式。
3.2随机变量
我们可以先看下面的一些问题。
某人射击一次,可能出现命中0环,命中1环…,命中10环等结果。即可能出现的结果可以由0,1,2,3,4,5,6,7,8,9,10这11个数来表示。
在某次的产品检验中,在可能含有次品的100件产品中任意抽取4件来检验,那么其中含有的次品可能的是0件,1件,2件,3件,4件,即可能出现的结果可以由0,1,2,3,4这5个数来表示。
我们把上面这些事件称为随机实验,随机实验想要得到的结果(例如射击一次命中的环数)可以用一个变量来表示的话,那么这样的变量就叫做随机变量(random variable)
随机变量的一些特征:
1. 可用数表示
2. 实验前可判断出所有可能取值
3. 实验前不能判断具体取哪个值
4. 所有可能值按照某种顺序列出
离散型随机变量
随机变量的取值是可以一一列出的比如上面所说的射击事件
连续型随机变量
那就是取值不能一一列出的咯,比如说一天内气温的变化量
推广:
一般地,如果X是随机变量,若有Y=f(X),则Y也是随机变量
3.3数学期望
在概率论中,数学期望简称期望,通俗的说就是平均值,它表示的是随机变量的取值的平均水平。
计算的公式
X1,X2,X3,……,Xn为这离散型随机变量,p(X1),p(X2),p(X3),……p(Xn)为这几个数据的概率函数。在随机出现的几个数据中p(X1),p(X2),p(X3),……p(Xn)概率函数就理解为数据X1,X2,X3,……,Xn出现的频率f(Xi).则:
E(X) = X1*p(X1) + X2*p(X2) + …… + Xn*p(Xn) = X1*f1(X1) + X2*f2(X2) + …… + Xn*fn(Xn)
上面的这个看着有点恶心,我们来温故一下当年高中数学课本中的东东,分分钟暴露了年龄的数学课本啊,但是还是很喜欢
(在这里我们主要考虑离散型随机变量)

总而言之,数学期望就是随机变量的取值乘以在随机实验中这个随机变量取到的概率。
推广一下
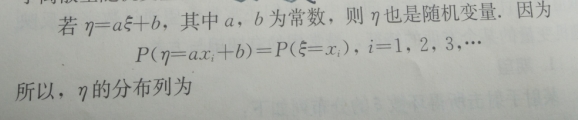

下面来举个例子

如果你已经理解了数学期望,随机变量这些概念那么我们就来说说信息熵的计算。
都说了熵是表示信息的期望值,信息的期望值,信息的期望值,如果您已经看懂了数学期望怎么算,那么你应该会很容易理解信息熵会怎么计算。
还是刚才那个例子,我们给出了一个信息:我爱你1314,然后把这个信息分为三类,然后我们要计算这个信息的熵。
那是不是就要计算这个信息所有类别的可能值得数学期望了。
那么熵的公式就是下面这个样子的:
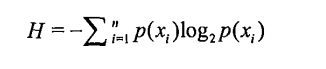
其中n表示的是这个信息被分为n类。
4.决策树构建的一般流程
- 收集数据:任何你能收集数据的方法
- 准备数据: 决策树的算法只适用于标称型数据(可理解为离散型的,不连续的),因此数值型的数据(连续的数据)必须离散化。
- 分析数据: 可以使用任何方法,构造树完成之后,我们要检查图形是否符合预期。
- 训练算法:构造决策树的数据结构。
- 测试算法: 使用经验树计算错误率。
- 使用算法: 此步骤可以适用于任何监督学习算法,而使用决策数可以更好的理解数据的内在含义 (why? 对比于其他算法,比如说k均值算法,就是把给定的数据按照相似度分为一类,每一类表示什么你可能就不知道了。就像我们上一章讲的那个例子,可以用决策树做邮件的分类系统,我们可以根据分类标签知道这个邮件是垃圾邮件还是需要立刻处理的邮件)
5. 数据的构建
我们使用的例子还是《机器学习与实战》那本书上的例子。我把写作的思路和流程改了一下,还有这本书里好多错误,我好想帮作者重写这本书,或许不是作者的错误,是翻译和排版的错误。
首先我们第一步还是收集数据:

在这张表中我们可以发现这里有5个数据,这里有两个特征(要不要浮出水面生存,和是否有脚蹼)来划分这5个生物是鱼类还是非鱼类。
现在我们要做的就是是要根据第一个特征还是第二个特征来划分数据,进行分类。
我们使用python来构建我们的代码。
我们创建一个名为trees.py的python文件,然后在下面输入以下的代码
#!/usr/bin/env python
# coding=utf-8
# author: chicho
# running: python trees.py
# filename : trees.py
def createDataSet():
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']] # 我们定义了一个list来表示我们的数据集,这里的数据对应的是上表中的数据
labels = ['no surfacing','flippers']
return dataSet, labels
其中第一列的1表示的是不需要浮出水面就可以生存的,0则表示相反。 第二列同样是1表示有脚蹼,0表示的是没有。
这个时候我们来测试以下我们的数据集。
我用的是linux系统,我们打开一个终端来测试以下我们的数据。
我们创建完这个文件之后,进入到这个文件的目录下。我把这个文件保存在~/code 这个路径下。

我们输入python,进入shell命令,如下图所示

代码如下:
>>> import trees
>>> reload(trees)
<module 'trees' from 'trees.pyc'>
>>> myDat,labels=trees.createDataSet()
>>> myDat
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
>>> labels
['no surfacing', 'flippers']
>>>
我们来说说这段代码:
import的作用:
导入/引入一个python标准模块,其中包括.py文件、带有init.py文件的目录。
例如:
import module_name[,module1,...]
from module_name import *|child[,child1,...] 注意:
多次重复使用import语句时,不会重新加载被指定的模块,只是把对该模块的内存地址给引用到本地变量环境。
也就是说使用import的时候引用的module只会被加载一次,只会被加载一次,系统会把这个模块的地址给引用它的代码或者是这个python文件。
我们来测试以下
构建两个文件 a.py 和 b.py
其中a.py的代码如下:
#!/usr/bin/env python
# coding=utf-8
import os
print 'in a.py file'
print 'The address of os is:', id(os)
print '***end***'
我们在b.py中写如下代码:
#!/usr/bin/env python
# coding=utf-8
#filename: b.py
import a
import os
print "*****************"
print 'in b file'
print 'The adress of b file is:',id(os)
import a
print 'The adress of a module is:',id(a)这个时候,我们来测试以下结果:
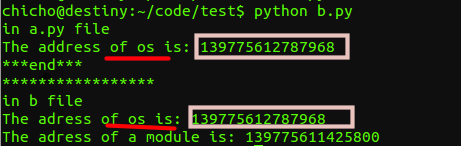
我们在a,b两个文件中都引入了os 模块但是我们发现它的地址都没有改变。
reload
reload 的目的是为了开发期的 “edit and debug”/即编即调
reload 的作用:
对已经加载的模块进行重新加载,一般用于原模块有变化等特殊情况,reload前该模块必须已经import过。
e.g:
import os
reload(os)说明:
reload会重新加载已加载的模块,但原来已经使用的实例还是会使用旧的模块,而新生产的实例会使用新的模块;reload后还是用原来的内存地址;不能支持from。。import。。格式的模块进行重新加载。
我们在举一个例子:
创建两个文件c.py, 以及文件 d.py
#!/usr/bin/env python
# coding=utf-8
# filename : c.py
import os
print 'in c.py file'
print 'The address of os is:', id(os)
print '***end***'这个时候我们用d.py这个文件去引用c这个模块
#!/usr/bin/env python
# coding=utf-8
#filename: d.py
import c
import os
print "*****************"
print 'in d file'
print 'The adress of os is:',id(os)
print 'The address of c file is:',id(c)
print '*****reload******'
reload(c)
print '****reload*****'
print 'The adress 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2210
2210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









