







Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,相应概念如下:
1、独立模式即本地运行模式(standalone或local mode)
无需运行任何守护进程(daemon),所有程序都在单个JVM上执行。由于在本机模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。
2、伪分布运行模式
伪分布:如果Hadoop对应的Java进程都运行在一个物理机器上,称为伪分布运行模式,如下图所示:
[root@hadoop20 dir2]# jps
8993 Jps
7409 SecondaryNameNode
7142 NameNode
7260 DataNode
8685 NodeManager
8590 ResourceManager3、集群模式
如果Hadoop对应的Java进程运行在多台物理机器上,称为集群模式.[集群就是有主有从] ,如下图所示:
[root@hadoop11 local]# jps
18046 NameNode
30927 Jps
18225 SecondaryNameNode[root@hadoop22 ~]# jps
9741 ResourceManager
16569 Jps[root@hadoop33 ~]# jps
12775 DataNode
20189 Jps
12653 NodeManager[root@hadoop44 ~]# jps
10111 DataNode
17519 Jps
9988 NodeManager[root@hadoop55 ~]# jps
11563 NodeManager
11686 DataNode
19078 Jps[root@hadoop66 ~]# jps
10682 DataNode
10560 NodeManager
18085 Jps注意:伪分布模式就是在一台服务器上面模拟集群环境,但仅仅是机器数量少,其通信机制与运行过程与真正的集群模式是一样的,hadoop的伪分布运行模式可以看做是集群运行模式的特殊情况。
为了方便文章的后续说明,先介绍一下hadoop的体系结构:
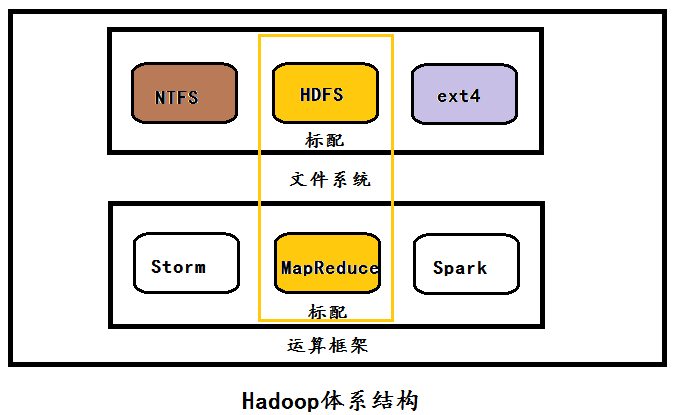
从Hadoop的体系结构可以看出,HDFS与MapReduce分别是Hadoop的标配文件系统与标配计算框架,但是呢?–我们完全可以选择别的文件系统(如Windows的NTFS,Linux的ext4)与别的计算框架(如spark、storm等)为Hadoop所服务,这恰恰说明了hadoop的松耦合性。在hadoop的配置文件中,我们是通过core-site.xml这个配置文件指定所用的文件系统的。
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop11:9000</value>
</property>下面将基于Linux与Windows两种开发环境详细说明hadoop的本地运行模式,其中核心知识点如下:
Hadoop的本地执行模式:
1、在windows的eclipse里面直接运行main方法,就会将job提交给本地执行器localjobrunner执行
—-输入输出数据可以放在本地路径下(c:/wc/srcdata/)
—-输入输出数据也可以放在hdfs中(hdfs://hadoop20:9000/dir)
2、在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行
—-输入输出数据可以放在本地路径下(/usr/local/)
—-输入输出数据也可以放在hdfs中(hdfs://hadoop20:9000/dir)
首先先基于Linux的开发环境进行介绍:
以WordCount程序为例,输入输出文件都放在本地路径下,代码如下:
package MapReduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class WordCount
{
public static String path1 = "file:///usr/local/word.txt"; //file:///代表本地文件系统中路径的意思
public static String path2 = "file:///usr/local/dir1";
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>
{
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
String[] splited = v1.toString().split("\t");
for (String string : splited)
{
context.write(new Text(string),new LongWritable(1L));
}
}
}
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>
{
protected void reduce(Text k2, Iterable<LongWritable> v2s,Context context)throws IOException, InterruptedException
{
long sum = 0L;
for (LongWritable v2 : v2s)
{
sum += v2.get();
}
context.write(k2,new LongWritable(sum));
}
}
}
在程序的运行过程中,相应的java进程如下:
[root@hadoop20 local]# jps
7621 //对应的是启动的eclipse
9833 Jps
9790 WordCount //对应的是WordCount程序下面我们在本地查看运行结果:
[root@hadoop20 dir]# pwd
/usr/local/dir1
[root@hadoop20 dir1]# more part-r-00000
hello 2
me 1
you 1接下来我们将输入路径选择HDFS文件系统中的路径,输出路径还是本地linux文件系统,首先我们在linux上面启动HDFS分布式文件系统。
[root@hadoop20 dir]# start-dfs.sh
Starting namenodes on [hadoop20]
hadoop20: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-hadoop20.out
hadoop20: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-hadoop20.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-hadoop20.out
[root@hadoop20 dir]# jps
10260 SecondaryNameNode
7621
10360 Jps
9995 NameNode
10110 DataNode还是以WordCount程序为例,代码如下:
package MapReduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class WordCount
{
public static String path1 = "hdfs://hadoop90:2000/word.txt";//读取HDFS中的测试集
public static String path2 = "file:///usr/local/dir2"; //输出数据输出到本地文件系统中
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);//默认获取的是本地文件系统的FileSystem实例(在这里就是linux文件系统的实例)
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>
{
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
String[] splited = v1.toString().split("\t");
for (String string : splited)
{
context.write(new Text(string),new LongWritable(1L));
}
}
}
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>
{
protected void reduce(Text k2, Iterable<LongWritable> v2s,Context context)throws IOException, InterruptedException
{
long sum = 0L;
for (LongWritable v2 : v2s)
{
sum += v2.get();
}
context.write(k2,new LongWritable(sum));
}
}
}
运行结果如下:
[root@hadoop20 dir2]# more part-r-00000
hello 2
me 1
you 1
[root@hadoop20 dir2]# pwd
/usr/local/dir2接下来我们将输入输出路径都换成HDFS中的路径:
代码如下:
package MapReduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class WordCount
{
public static String path1 = "hdfs://hadoop20:9000/word.txt";//读取HDFS中的测试集
public static String path2 = "hdfs://hadoop20:9000/dir3";
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>
{
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
String[] splited = v1.toString().split("\t");
for (String string : splited)
{
context.write(new Text(string),new LongWritable(1L));
}
}
}
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>
{
protected void reduce(Text k2, Iterable<LongWritable> v2s,Context context)throws IOException, InterruptedException
{
long sum = 0L;
for (LongWritable v2 : v2s)
{
sum += v2.get();
}
context.write(k2,new LongWritable(sum));
}
}
}程序抛出异常:

处理措施:
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop20:9000/");//加入此行代码,表示获取HDFS中的FileSystem实例,而不在是默认linux文件系统的FileSystem实例查看运行结果:
[root@hadoop20 hadoop]# hadoop fs -cat /dir3/part-r-00000
hello 2
me 1
you 1好了,从上面的3个例子可以看出,在Linux这种开发环境下,Hadoop的本地运行模式是很简单的,不用配置任何文件,但是在Windows开发环境下,我们却需要配置很多文件。
在这里先说明一下,因为我的电脑是64位,所以我在windows上面安装的jdk1.7、eclipse、hadoop2.4.1都是64位的,下载链接如下:
http://blog.csdn.net/a2011480169/article/details/51814212
在Windows开发环境中实现Hadoop的本地运行模式,详细步骤如下:
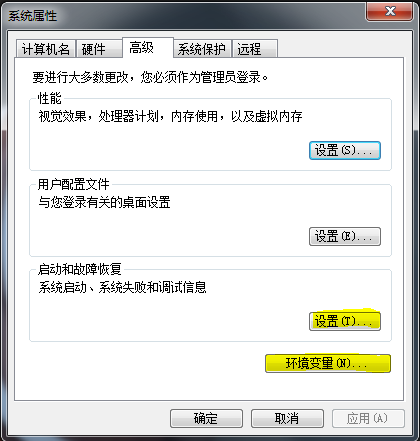
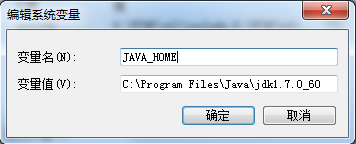
1、在本地安装好jdk、hadoop2.4.1,并配置好环境变量:JAVA_HOME、HADOOP_HOME、Path路径(配置好环境变量后最好重启电脑)。
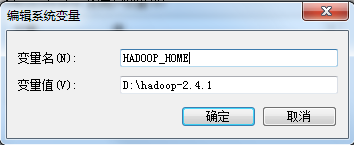
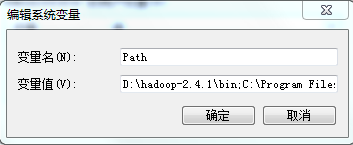
2、用hadoop-common-2.2.0-bin-master的bin目录替换本地hadoop2.4.1的bin目录,因为hadoop2.0版本中没有hadoop.dll和winutils.exe这两个文件。
hadoop-common-2.2.0-bin-master的下载链接如下:
http://blog.csdn.net/a2011480169/article/details/51814212
如果缺少hadoop.dll和winutils.exe话,程序将会抛出下面异常:
java.io.IOException: Could not locate executable D:\hadoop-2.4.1\bin\winutils.exe in the Hadoop binaries.java.lang.Exception: java.lang.NullPointerException所以用hadoop-common-2.2.0-bin-master的bin目录替换本地hadoop2.4.1的bin目录是必要的一个步骤。
注意:如果只是将hadoop-common-2.2.0-bin-master的bin目录中的hadoop.dll和winutils.exe这两个文件添加到hadoop2.4.1的bin目录中,也是可行的,但最好用用hadoop-common-2.2.0-bin-master的bin目录替换本地hadoop2.4.1的bin目录。
上面这两个步骤完成之后我们就可以跑程序了,从而实现Hadoop的本地运行模式:
首先输入输出路径都选择windows的文件系统:
代码如下:
package MapReduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class WordCount
{
public static String path1 = "file:///C:\\word.txt";//读取本地windows文件系统中的数据
public static String path2 = "file:///D:\\dir";
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>
{
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
String[] splited = v1.toString().split("\t");
for (String string : splited)
{
context.write(new Text(string),new LongWritable(1L));
}
}
}
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>
{
protected void reduce(Text k2, Iterable<LongWritable> v2s,Context context)throws IOException, InterruptedException
{
long sum = 0L;
for (LongWritable v2 : v2s)
{
sum += v2.get();
}
context.write(k2,new LongWritable(sum));
}
}
}
在dos下查看运行中的java进程:
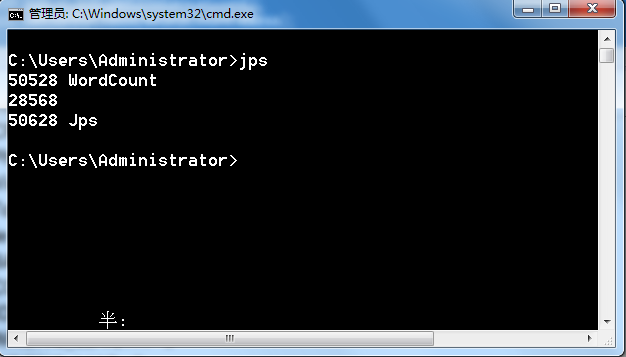
其中28568为windows中启动的eclipse进程。
接下来我们查看运行结果:

part-r-00000中的内容如下:
hello 2
me 1
you 1接下来输入路径选择windows本地,输出路径换成HDFS文件系统,代码如下:
package MapReduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class WordCount
{
public static String path1 = "file:///C:\\word.txt";//读取windows文件系统中的数据
public static String path2 = "hdfs://hadoop20:9000/dir";//输出到hdfs中
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>
{
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
String[] splited = v1.toString().split("\t");
for (String string : splited)
{
context.write(new Text(string),new LongWritable(1L));
}
}
}
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>
{
protected void reduce(Text k2, Iterable<LongWritable> v2s,Context context)throws IOException, InterruptedException
{
long sum = 0L;
for (LongWritable v2 : v2s)
{
sum += v2.get();
}
context.write(k2,new LongWritable(sum));
}
}
}程序抛出异常:
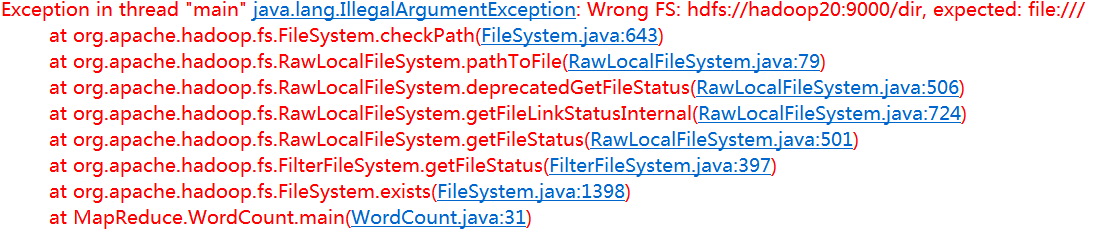
处理措施同上:
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop20:9000/");
FileSystem fileSystem = FileSystem.get(conf);//获取HDFS中的FileSystem实例查看运行结果:
[root@hadoop20 dir4]# hadoop fs -cat /dir/part-r-00000
hello 2
me 1
you 1好的,到这里hadoop的本地文件系统就讲述完了,注意一下几点:
1、file:\\ 代表本地文件系统,hdfs:// 代表hdfs分布式文件系统
2、linux下的hadoop本地运行模式很简单,但是windows下的hadoop本地运行模式需要配置相应文件。
3、MapReduce所用的文件放在哪里是没有关系的(可以放在Windows本地文件系统、可以放在Linux本地文件系统、也可以放在HDFS分布式文件系统中),最后是通过FileSystem这个实例来获取文件的。
如有问题,欢迎留言指正!
注意:如果用户用的是Hadoop1.0版本,并且是Windows环境下实现本地运行模式,则只需设置HADOOP_HOME与PATH路径,其余不用任何设置!















 6531
6531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









