







Mapreduce调试很蛋疼的,它不会覆盖上一次输出的结果,如果发现输出文件夹已经存在,比如我的调试输出文件夹是hdfs://192.168.230.129:9000/output,它会直接给你报如下错误:
- Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://192.168.230.129:9000/output already exists
- at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:123)
- at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:770)
- at org.apache.hadoop.mapreduce.Job.submit(Job.java:432)
- at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:447)
- at MyMapReduce.main(MyMapReduce.java:65)
如下图所示:

当然,错误很明了,就是输出文件夹已存在。
不过网上有写很坑爹的教程,表示解决这个错误,要自己手动删除输出文件夹。
这很蛋疼,无论你这次调试成功还是报错与否,都要先刷新HDFS,再删除,再运行程序:
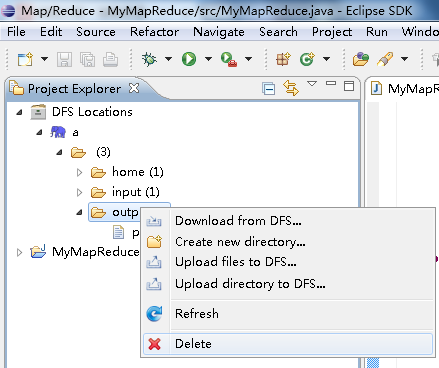
这是何其地蛋疼啊!其实可以在代码上利用hdfs的文件操作,解决这个问题。思想就是在代码运行之前,也就是提交作业之前,判断output文件夹是否存在,如果存在则删除。具体代码如下:
- import java.io.IOException;
- import java.util.StringTokenizer;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- public class MyMapReduce {
- public static class MyMapper extends
- Mapper<Object, Text, Text, IntWritable> {
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text();
- public void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- StringTokenizer itr = new StringTokenizer(value.toString());
- while (itr.hasMoreTokens()) {
- word.set(itr.nextToken());
- context.write(word, one);
- }
- }
- }
- public static class MyReducer extends
- Reducer<Text, IntWritable, Text, IntWritable> {
- private IntWritable result = new IntWritable();
- public void reduce(Text key, Iterable<IntWritable> values,
- Context context) throws IOException, InterruptedException {
- int sum = 0;
- for (IntWritable val : values) {
- sum += val.get();
- }
- result.set(sum);
- context.write(key, result);
- }
- }
- public static void main(String[] args) throws Exception {
- Configuration conf = new Configuration();
- String[] otherArgs = new GenericOptionsParser(conf, args)
- .getRemainingArgs();
- if (otherArgs.length != 2) {
- System.err.println("Usage: wordcount <in> <out>");
- System.exit(2);
- }
- Job job = new Job(conf);
- job.setMapperClass(MyMapper.class);
- job.setReducerClass(MyReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- // 判断output文件夹是否存在,如果存在则删除
- Path path = new Path(otherArgs[1]);// 取第1个表示输出目录参数(第0个参数是输入目录)
- FileSystem fileSystem = path.getFileSystem(conf);// 根据path找到这个文件
- if (fileSystem.exists(path)) {
- fileSystem.delete(path, true);// true的意思是,就算output有东西,也一带删除
- }
- FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
- FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
关键就是如下这4行:
- // 判断output文件夹是否存在,如果存在则删除
- Path path = new Path(otherArgs[1]);// 取第1个表示输出目录参数(第0个参数是输入目录)
- FileSystem fileSystem = path.getFileSystem(conf);// 根据path找到这个文件
- if (fileSystem.exists(path)) {
- fileSystem.delete(path, true);// true的意思是,就算output有东西,也一带删除
- }
教会Mapreduce这SB覆盖上一次运行结果,别只会在这报错!















 3771
3771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









