 Python网络爬虫从基础到实战案例
Python网络爬虫从基础到实战案例




目录
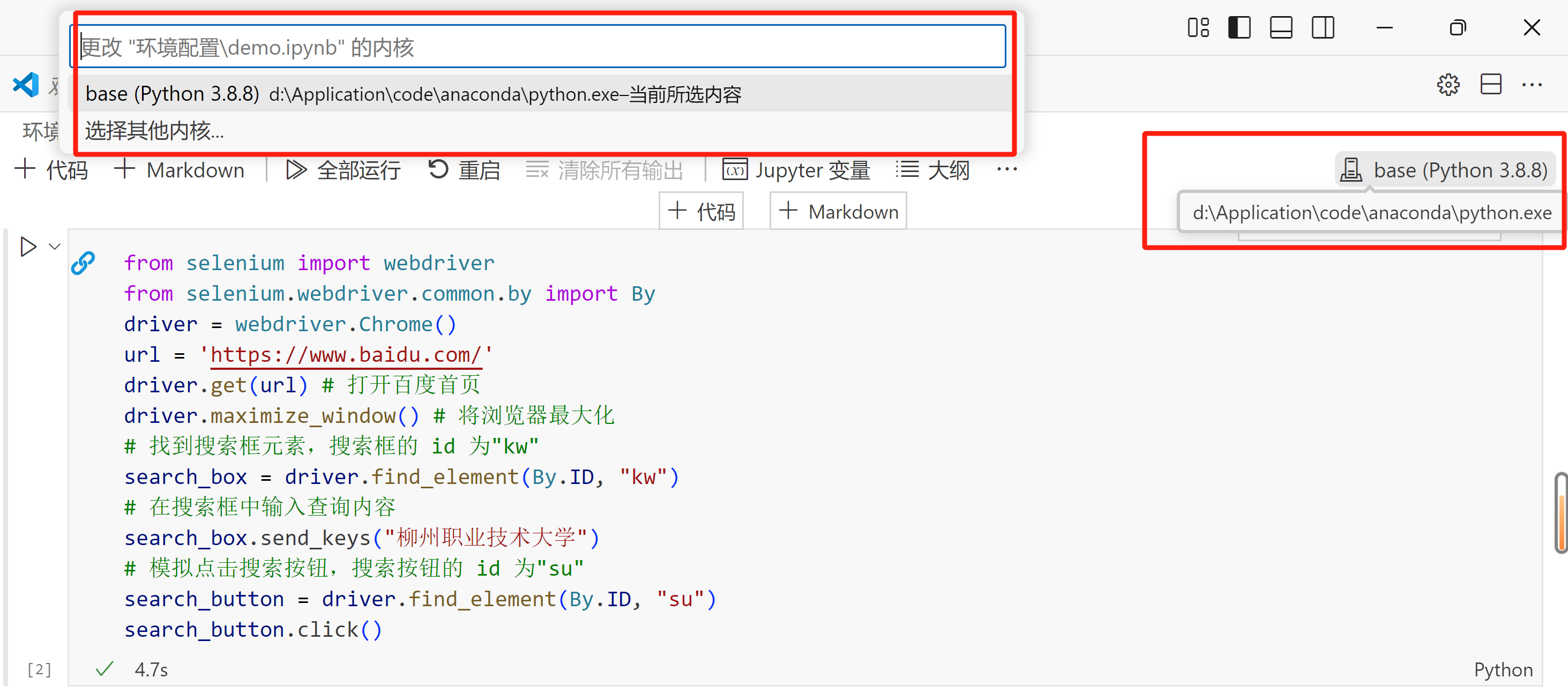
(3)在右上角选择ipynb文件的Python解释器后即可运行Python程序
这个爬虫脚本用于抓取新能源汽车销量数据,并将数据存储到 MySQL 数据库中。
引言
在大数据时代,网络爬虫作为信息获取的重要工具,正发挥着越来越重要的作用。本文将带你深入了解 Python 网络爬虫技术,从基础概念到实战案例,让你掌握这一强大的数据采集技能。
一、网络爬虫基础概念
网络爬虫,又称为网页蜘蛛、网络机器人,是一种按照一定的规则,自动抓取万维网信息的程序或脚本。其工作原理类似于用户浏览网页的过程,通过发送 HTTP 请求获取网页内容,然后对内容进行解析和提取有用信息。
在网络爬虫的世界里,有几个重要的概念需要理解:
-
URL:Uniform Resource Locator,统一资源定位符,是网页的地址,爬虫通过 URL 来访问网页。
-
HTTP 请求:爬虫与服务器进行通信的方式,常见的请求方法有 GET、POST 等。
-
响应:服务器接收到请求后返回的内容,通常是 HTML、JSON 等格式的数据。
-
解析:将获取到的响应内容进行处理,提取出我们需要的信息。
二、软件介绍
vscode是一个微软开发的优秀的代码编辑器。
可以从vscode的官网下载:Visual Studio Code - Code Editing. Redefined
vscode可以安装各种插件来拓展它的功能,安装jupyter相关的插件可以让我们在vscode中运行ipynb类型的文件。
我们通过以下几步来在vscode中运行一个ipynb文件:
(1)安装jupyter相关的插件。
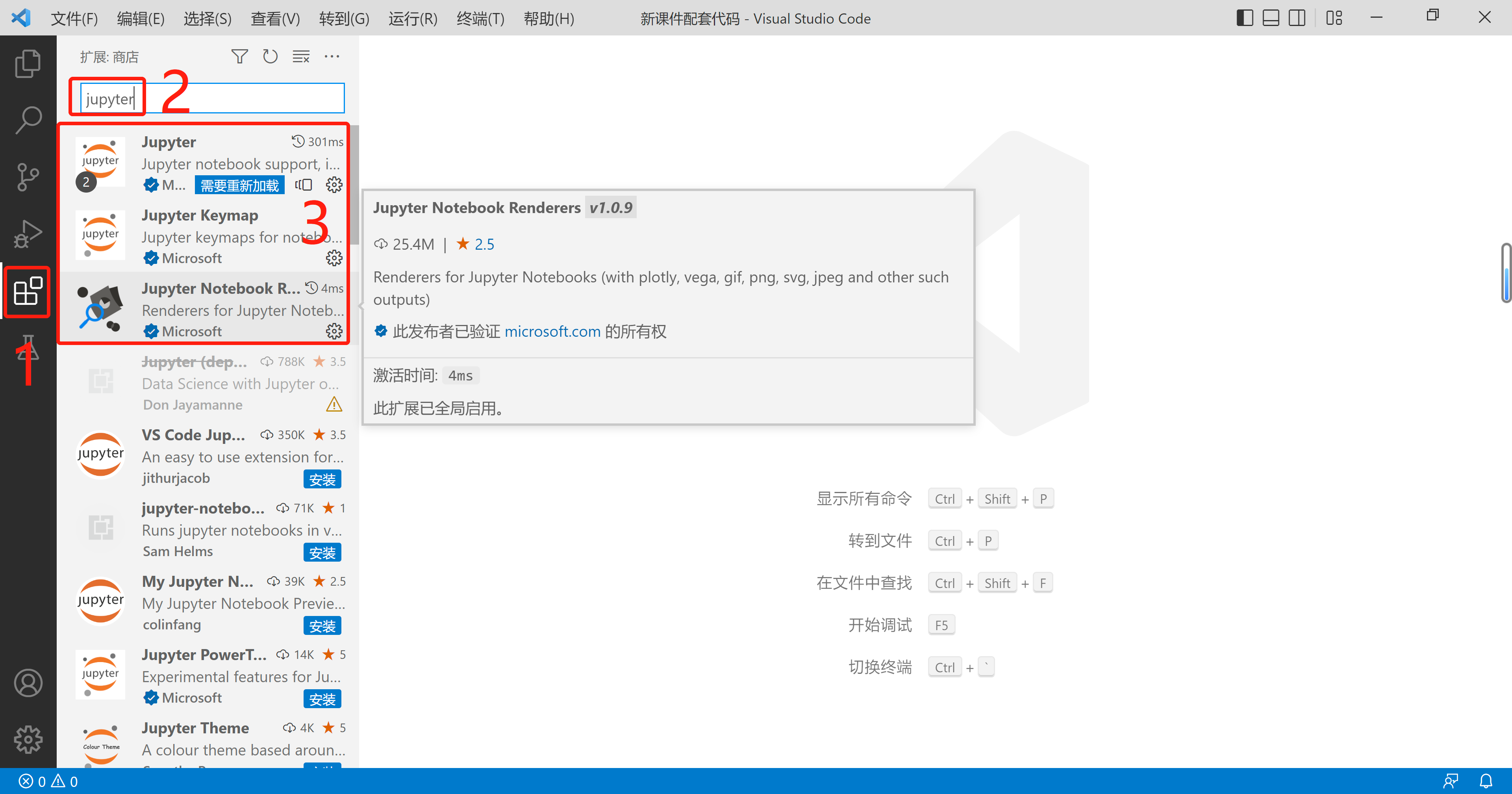
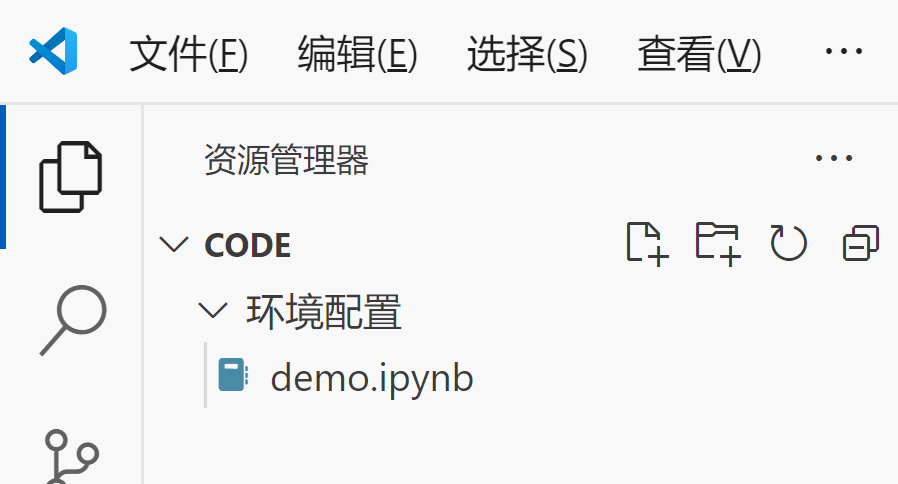
(2)打开你的ipynb文件所在的路径:
文件——打开文件夹——选择你的ipynb文件所在的路径:
(3)在右上角选择ipynb文件的Python解释器后即可运行Python程序
三、Python 网络爬虫常用库
Python 之所以成为爬虫领域的首选语言,得益于其丰富的库支持。以下是一些常用的爬虫库:
- requests:一个简单易用的 HTTP 库,用于发送 HTTP 请求。
- BeautifulSoup:用于解析 HTML 和 XML 文档,方便提取数据。
- lxml:另一个强大的解析库,解析速度快,支持 XPath 表达式。
- Scrapy:一个高性能的爬虫框架,用于构建复杂的爬虫程序。
- Selenium:用于模拟浏览器行为,处理动态网页。
四、简单爬虫实战:爬取豆瓣电影
4. 准备工作
4.1 安装依赖库
pip install requests beautifulsoup4 pandas4.2 简单爬虫实战:爬取豆瓣电影 Top250
下面我们通过一个实战案例来学习 Python 网络爬虫的基本实现。我们将爬取豆瓣电影 Top250 的信息,包括电影名称、评分、评价人数和简介等。
代码实现:
import requests
from bs4 import BeautifulSoup
import time
import random
# 定义请求头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 存储电影信息的列表
movies_info = []
def get_movies_info(url):
"""获取指定URL页面的电影信息"""
try:
# 发送GET请求
response = requests.get(url, headers=headers, timeout=10)
# 检查请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 找到所有电影条目
movie_items = soup.find('ol', class_='grid_view').find_all('li')
for item in movie_items:
# 提取电影信息
movie_info = {}
# 电影名称
movie_info['title'] = item.find('span', class_='title').text
# 评分
movie_info['rating'] = item.find('span', class_='rating_num').text
# 评价人数
movie_info['votes'] = item.find('div', class_='star').find_all('span')[-1].text.strip()
# 简介
intro = item.find('p', class_='quote')
movie_info['intro'] = intro.find('span', class_='inq').text if intro else '暂无简介'
movies_info.append(movie_info)
else:
print(f'请求失败,状态码:{response.status_code}')
except Exception as e:
print(f'爬取过程中出现错误:{e}')
def main():
"""主函数,控制爬取流程"""
# 豆瓣电影Top250的基础URL
base_url = 'https://movie.douban.com/top250'
# 循环爬取10页数据(每页25条)
for i in range(0, 250, 25):
# 构造分页URL
url = f'{base_url}?start={i}'
print(f'正在爬取页面:{url}')
# 调用函数获取电影信息
get_movies_info(url)
# 随机休眠1-3秒,避免请求过于频繁
time.sleep(random.uniform(1, 3))
# 打印爬取到的电影信息
print(f'共爬取到{len(movies_info)}部电影信息:')
for i, movie in enumerate(movies_info, 1):
print(f'\n第{i}部电影:')
print(f'电影名称:{movie["title"]}')
print(f'评分:{movie["rating"]}')
print(f'评价人数:{movie["votes"]}')
print(f'简介:{movie["intro"]}')
if __name__ == '__main__':
main()代码解析:
1. 库导入部分:
import requests
from bs4 import BeautifulSoup
import time
import random
- requests库用于发送 HTTP 请求,获取网页内容。
- BeautifulSoup用于解析 HTML 文档,提取我们需要的信息。
- time和random库用于控制爬取间隔,避免对服务器造成过大压力,同时降低被封 IP 的风险。
2. 请求头设置:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}设置User-Agent是为了模拟浏览器访问,让服务器认为是正常用户在浏览网页,而不是爬虫程序。不同的浏览器有不同的User-Agent字符串,这里使用的是 Chrome 浏览器的。
3. 获取电影信息函数 :
def get_movies_info(url):
"""获取指定URL页面的电影信息"""
try:
# 发送GET请求
response = requests.get(url, headers=headers, timeout=10)
# 检查请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 找到所有电影条目
movie_items = soup.find('ol', class_='grid_view').find_all('li')
for item in movie_items:
# 提取电影信息
movie_info = {}
# 电影名称
movie_info['title'] = item.find('span', class_='title').text
# 评分
movie_info['rating'] = item.find('span', class_='rating_num').text
# 评价人数
movie_info['votes'] = item.find('div', class_='star').find_all('span')[-1].text.strip()
# 简介
intro = item.find('p', class_='quote')
movie_info['intro'] = intro.find('span', class_='inq').text if intro else '暂无简介'
movies_info.append(movie_info)
else:
print(f'请求失败,状态码:{response.status_code}')
except Exception as e:
print(f'爬取过程中出现错误:{e}')
- 函数接收一个 URL 作为参数,用于指定要爬取的页面。
- 使用requests.get()发送 GET 请求,并设置请求头和超时时间。
- 通过检查响应的状态码(response.status_code)来判断请求是否成功,200 表示成功。
- 使用BeautifulSoup解析 HTML 内容,html.parser是解析器类型。
- 通过 HTML 标签和类名找到包含电影信息的元素,然后提取具体的信息,如电影名称、评分等。
- 这里使用了find()和find_all()方法来查找元素,find()返回第一个匹配的元素,find_all()返回所有匹配的元素。
- 对于简介部分,先检查是否存在简介元素,再进行提取,避免出现错误。
4. 主函数:
def main():
"""主函数,控制爬取流程"""
# 豆瓣电影Top250的基础URL
base_url = 'https://movie.douban.com/top250'
# 循环爬取10页数据(每页25条)
for i in range(0, 250, 25):
# 构造分页URL
url = f'{base_url}?start={i}'
print(f'正在爬取页面:{url}')
# 调用函数获取电影信息
get_movies_info(url)
# 随机休眠1-3秒,避免请求过于频繁
time.sleep(random.uniform(1, 3))
# 打印爬取到的电影信息
print(f'共爬取到{len(movies_info)}部电影信息:')
for i, movie in enumerate(movies_info, 1):
print(f'\n第{i}部电影:')
print(f'电影名称:{movie["title"]}')
print(f'评分:{movie["rating"]}')
print(f'评价人数:{movie["votes"]}')
print(f'简介:{movie["intro"]}')
- 主函数负责控制整个爬取流程。
- 豆瓣电影 Top250 使用分页显示,每页 25 条数据,通过改变start参数来获取不同的页面,如start=0是第一页,start=25是第二页,以此类推。
- 使用for循环生成所有分页的 URL,并调用get_movies_info()函数进行爬取。
- 在每次爬取后,使用time.sleep()和random.uniform()生成一个 1 到 3 秒的随机休眠时间,这样可以让爬取行为更像人类浏览,减少被反爬机制检测到的可能性。
- 最后,遍历存储电影信息的列表,打印出所有爬取到的电影信息。
五、beautifulsoup:爬取车主之家销量数据
这个爬虫脚本用于抓取新能源汽车销量数据,并将数据存储到 MySQL 数据库中。
完整代码部分:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from sqlalchemy import create_engine
import time
# 提取单页数据函数
def get_one_page(url,database,table):
'''
url:某电影的豆瓣短评首页url\n
database:数据保存的mysql数据库名\n
table:数据保存的mysql表名\n
'''
print(f"当前使用的数据库: {database}, 表名: {table}")
headers = {
'User - Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0'
}
res = requests.get(url, headers=headers)
html_str = res.text
soup = BeautifulSoup(html_str, 'html.parser')
list_date = [soup.select('input.xl-date-input')[0]['value']] * len(soup.select('.xl-td-t1'))
list1 = [td.string for td in soup.select('.xl-td-t2')][::2]
list2 = [td.string for td in soup.select('.xl-td-t2')][1::2]
list_rank = [td.string for td in soup.select('.xl-td-t1')]
list_sales = [td.string for td in soup.select('.xl-td-t3')]
df = pd.DataFrame({
'月份': list_date,
'排名': list_rank,
'车型': list1,
'品牌': list2,
'销量': list_sales
})
return df
# 存储数据到数据库函数
def save_data_to_sql(df, database, table):
engine = create_engine(f'mysql+pymysql://root:123456@localhost:3306/{database}')
df.to_sql(table, engine, index=False, if_exists='append')
# 翻页爬取函数
def get_more_page(url, database, table):
headers = {
'User - Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36'
}
res = requests.get(url=url, headers=headers)
html_str = res.text
soup = BeautifulSoup(html_str, 'lxml')
num = int(soup.select('.num')[-1].string)
# 爬取存储首页数据
df = get_one_page(url, database, table)
save_data_to_sql(df, database, table)
# 爬取第 2 到第 num 页的数据
for i in range(2, num + 1):
url_new = f'https://xl.16888.com/ev-{i}.html'
df = get_one_page(url_new, database, table)
save_data_to_sql(df, database, table)
time.sleep(2)
if __name__ == '__main__':
url = 'https://xl.16888.com/ev.html'
get_more_page(url, 'sz', 'chezhuzhijia')
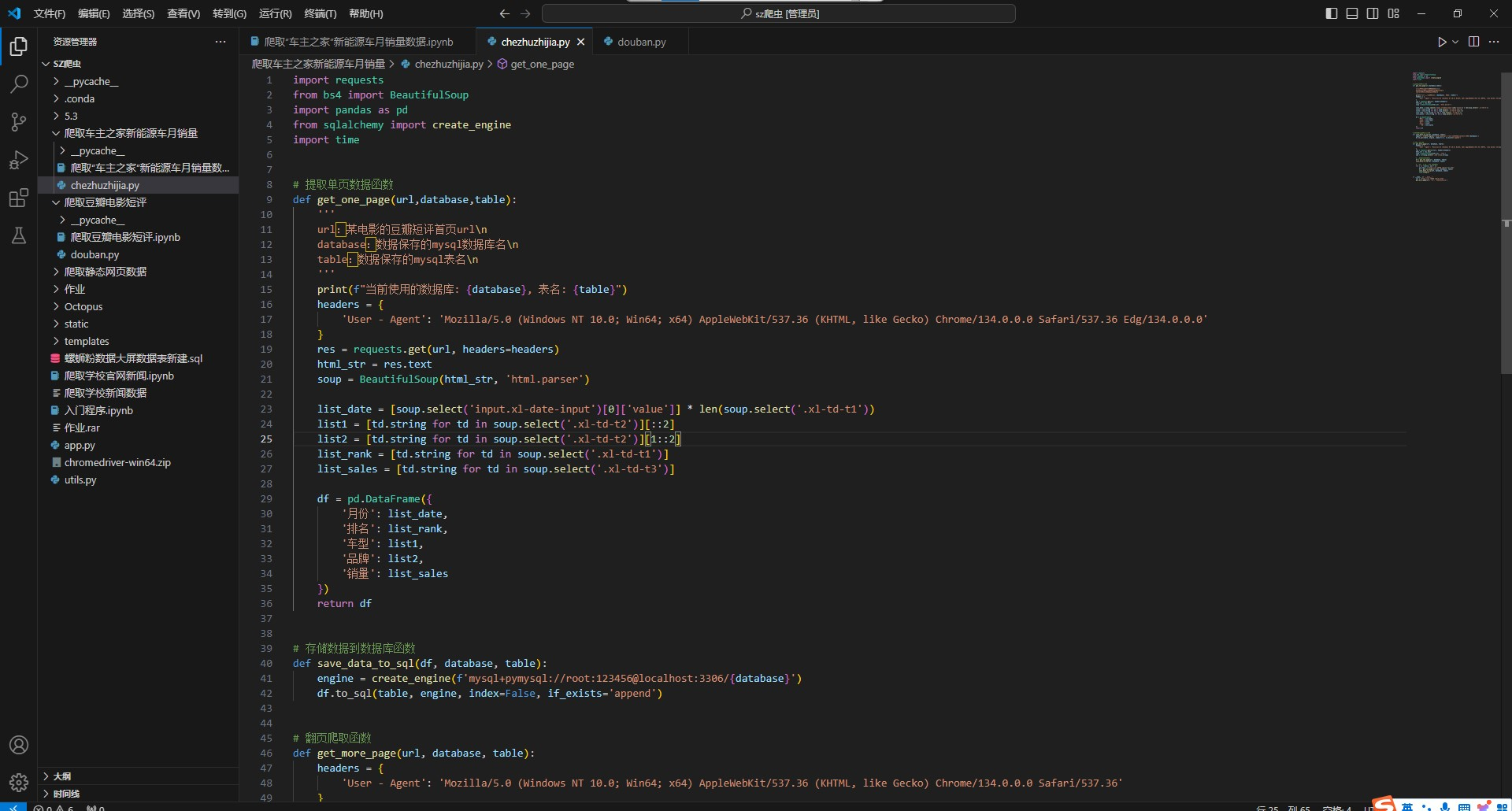
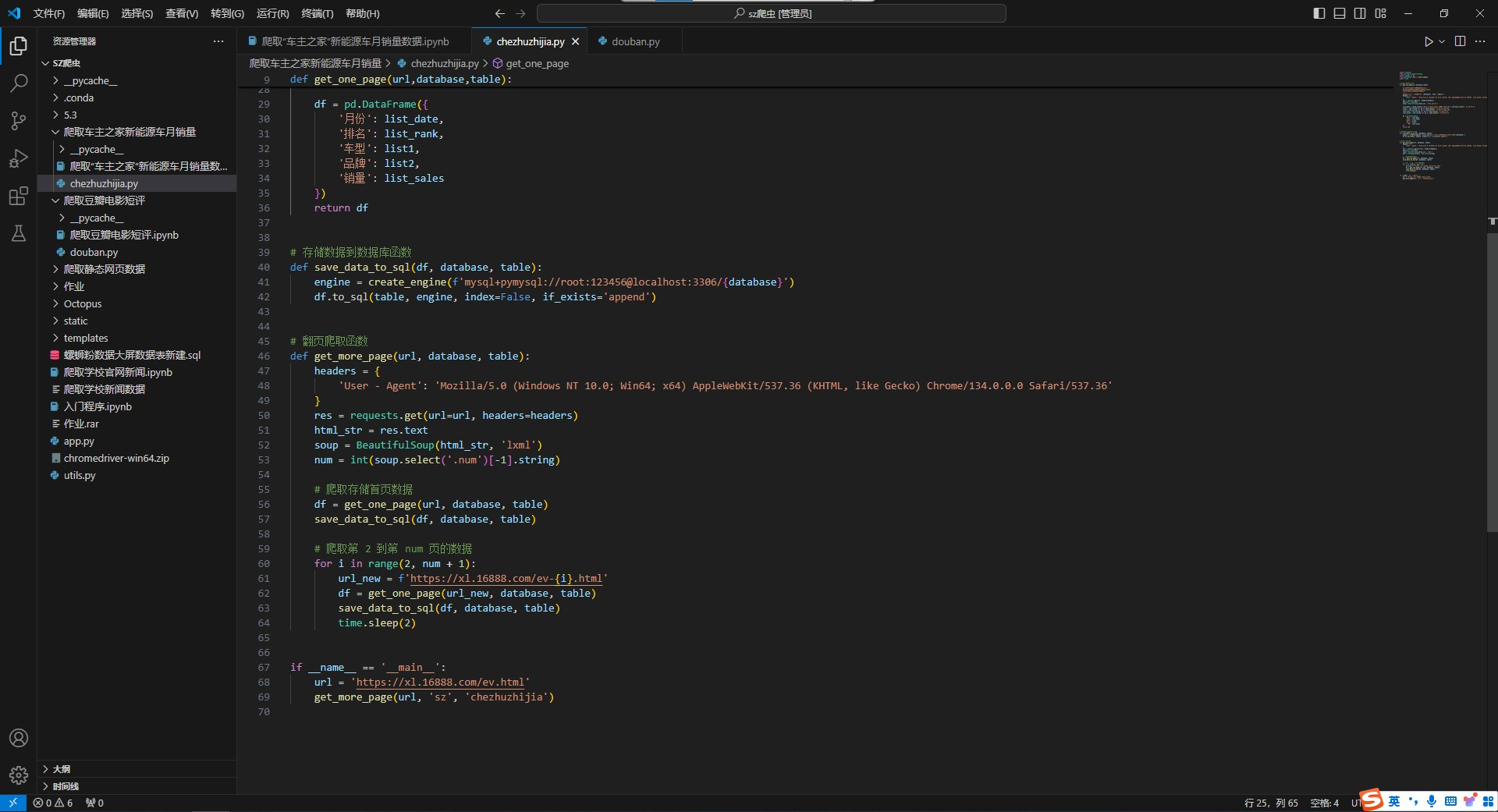
代码解析部分:
整体功能:
脚本分为三个主要函数:
get_one_page():抓取单页数据并返回 DataFramesave_data_to_sql():将 DataFrame 保存到 MySQL 数据库get_more_page():实现翻页功能,抓取多页数据
导入模块:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from sqlalchemy import create_engine
import time代码讲解:
代码导入了以下关键模块:
requests:发送 HTTP 请求获取网页内容BeautifulSoup:解析 HTML 内容pandas:数据处理和 DataFrame 操作sqlalchemy:连接 MySQL 数据库time:用于控制爬取间隔
单页数据抓取函数:
def get_one_page(url, database, table):
'''
url:某电影的豆瓣短评首页url\n
database:数据保存的mysql数据库名\n
table:数据保存的mysql表名\n
'''
print(f"当前使用的数据库: {database}, 表名: {table}")
headers = {
'User - Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0'
}
res = requests.get(url, headers=headers)
html_str = res.text
soup = BeautifulSoup(html_str, 'html.parser')
list_date = [soup.select('input.xl-date-input')[0]['value']] * len(soup.select('.xl-td-t1'))
list1 = [td.string for td in soup.select('.xl-td-t2')][::2]
list2 = [td.string for td in soup.select('.xl-td-t2')][1::2]
list_rank = [td.string for td in soup.select('.xl-td-t1')]
list_sales = [td.string for td in soup.select('.xl-td-t3')]
df = pd.DataFrame({
'月份': list_date,
'排名': list_rank,
'车型': list1,
'品牌': list2,
'销量': list_sales
})
return df代码讲解:
这个函数的主要功能是:
- 设置请求头模拟浏览器访问
- 使用 requests 获取网页内容
- 使用 BeautifulSoup 解析 HTML
- 通过 CSS 选择器提取数据:
- 从输入框获取日期信息
- 提取排名、车型、品牌和销量数据
- 将数据整理成 DataFrame 格式并返回
数据存储函数:
def save_data_to_sql(df, database, table):
engine = create_engine(f'mysql+pymysql://root:123456@localhost:3306/{database}')
df.to_sql(table, engine, index=False, if_exists='append')代码讲解:
这个函数的功能是:
- 创建 MySQL 数据库连接引擎
- 使用 pandas 的 to_sql 方法将 DataFrame 数据保存到指定的数据库表中
if_exists='append'参数表示如果表已存在则追加数据
翻页爬取函数:
def get_more_page(url, database, table):
headers = {
'User - Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36'
}
res = requests.get(url=url, headers=headers)
html_str = res.text
soup = BeautifulSoup(html_str, 'lxml')
num = int(soup.select('.num')[-1].string)
# 爬取存储首页数据
df = get_one_page(url, database, table)
save_data_to_sql(df, database, table)
# 爬取第 2 到第 num 页的数据
for i in range(2, num + 1):
url_new = f'https://xl.16888.com/ev-{i}.html'
df = get_one_page(url_new, database, table)
save_data_to_sql(df, database, table)
time.sleep(2)代码讲解:
这个函数的功能是:
- 首先获取首页内容,解析出总页数
- 调用
get_one_page函数爬取首页数据并保存- 循环构造分页 URL(格式为 ev - 页码.html)
- 依次爬取每页数据并保存
- 每次爬取后暂停 2 秒,避免请求过于频繁
主程序部分:
if __name__ == '__main__':
url = 'https://xl.16888.com/ev.html'
get_more_page(url, 'sz', 'chezhuzhijia')代码讲解:
这部分代码的功能是:
- 设置起始 URL 为车质网新能源汽车销量首页
- 调用
get_more_page函数开始爬取数据- 将数据保存到名为'sz' 的数据库中,表名为 'chezhuzhijia'
第二个代码部分:
import chezhuzhijia
url=('https://xl.16888.com/ev.html')
database='sz'
table_name='chezhuzhijia'
chezhuzhijia.get_one_page(url,database,table_name)运行结果:
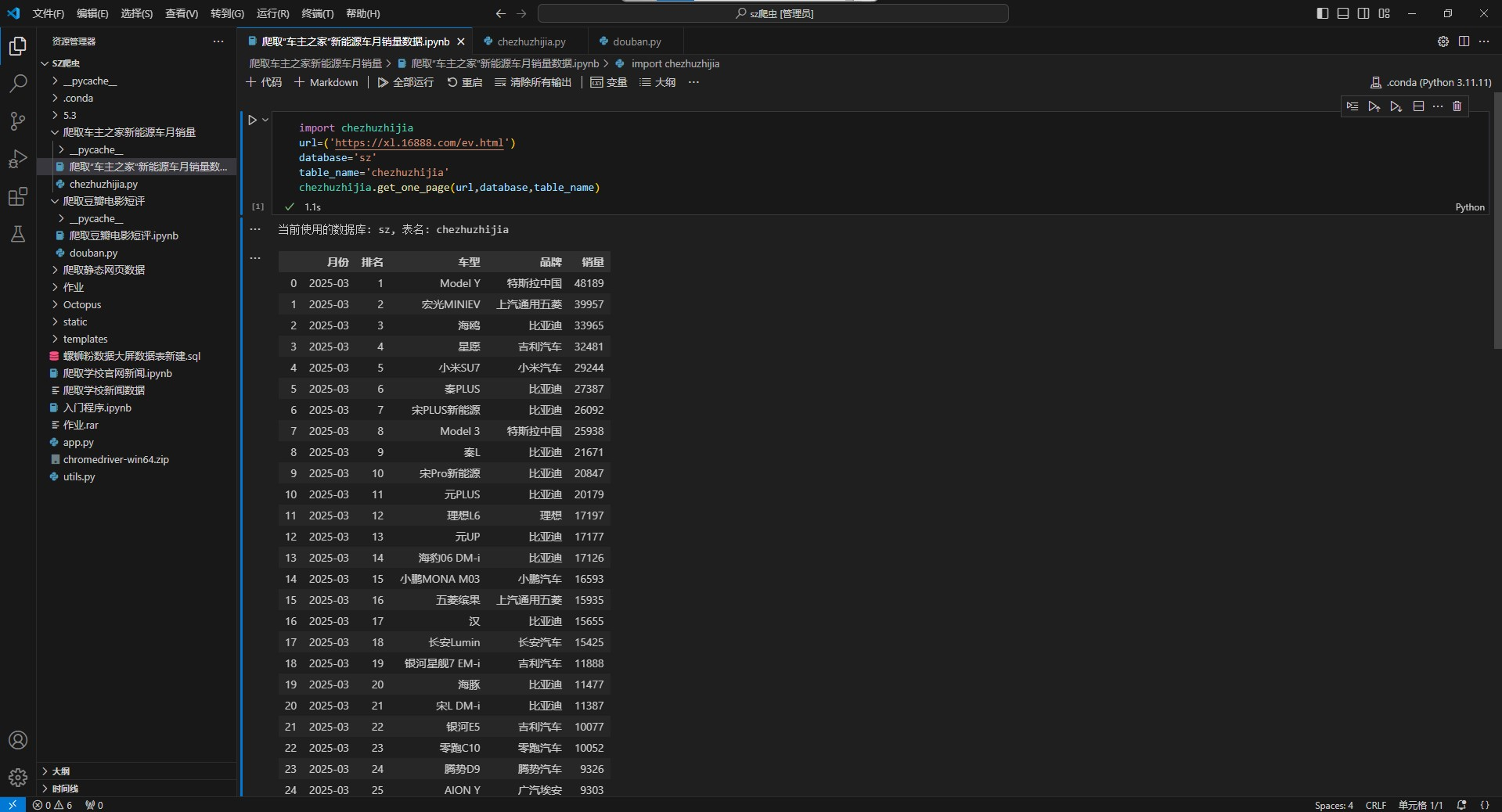
MySQL存储:
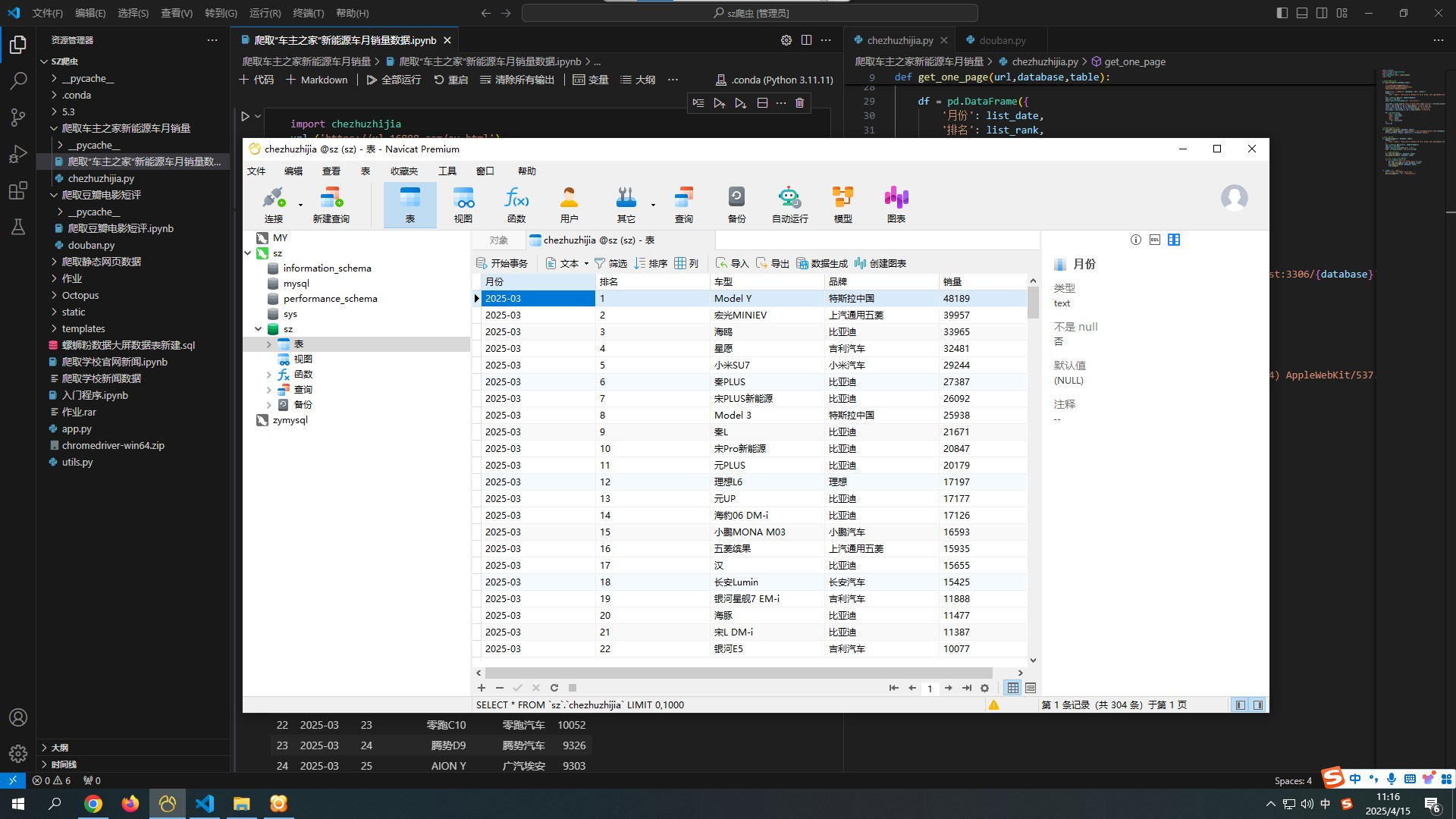
代码讲解:
这部分代码的功能是:
- 导入刚才定义的 chezhuzhijia 模块
- 设置 URL、数据库名和表名
- 调用
get_one_page函数只爬取首页数据- 注意这里只爬取首页且没有保存数据,只是返回了 DataFrame 对象
项目总结
这个爬虫脚本实现了对车质网新能源汽车销量数据的爬取和存储功能。主要使用了 requests 获取网页内容,BeautifulSoup 解析 HTML,pandas 处理数据,以及 sqlalchemy 连接 MySQL 数据库。
希望本篇文章对你有所帮助!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









