






kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力.
Apache kafka是消息中间件的一种。
一 、术语介绍
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker。
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)。每个topic都具有这两种模式:(队列:消费者组(consumer group)允许同名的消费者组成员瓜分处理;发布订阅:允许你广播消息给多个消费者组(不同名))。
Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition.
Producer
负责发布消息到Kafka broker,比如flume采集机就是Producer。
Consumer
消息消费者,向Kafka broker读取消息的客户端。比如Hadoop机器就是Consumer。
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
二、使用场景
1、Messaging
对于一些常规的消息系统,kafka是个不错的选择;partitons/replication和容错,可以使kafka具有良好的扩展性和性能优势.不过到目前为止,我们应该很清楚认识到,kafka并没有提供JMS中的”事务性”“消息传输担保(消息确认机制)”“消息分组”等企业级特性;kafka只能使用作为”常规”的消息系统,在一定程度上,尚未确保消息的发送与接收绝对可靠(比如,消息重发,消息发送丢失等)
2、Websit activity tracking
kafka可以作为”网站活性跟踪”的最佳工具;可以将网页/用户操作等信息发送到kafka中.并实时监控,或者离线统计分析等
3、Log Aggregation
kafka的特性决定它非常适合作为”日志收集中心”;application可以将操作日志”批量”“异步”的发送到kafka集群中,而不是保存在本地或者DB中;kafka可以批量提交消息/压缩消息等,这对producer端而言,几乎感觉不到性能的开支.此时consumer端可以使hadoop等其他系统化的存储和分析系统.
4、它应用于2大类应用
构建实时的流数据管道,可靠地获取系统和应用程序之间的数据。
构建实时流的应用程序,对数据流进行转换或反应。
三、分布式
Log的分区被分布到集群中的多个服务器上。每个服务器处理它分到的分区。 根据配置每个分区还可以复制到其它服务器作为备份容错。 每个分区有一个leader,零或多个follower。Leader处理此分区的所有的读写请求,而follower被动的复制数据。如果leader宕机,其它的一个follower会被推举为新的leader。 一台服务器可能同时是一个分区的leader,另一个分区的follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
四、消息处理顺序
Kafka保证消息的顺序不变。 在这一点上Kafka做的更好,尽管并没有完全解决上述问题。 Kafka采用了一种分而治之的策略:分区。 因为Topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。 所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。
五、安装
kafka安装和启动
六、Key和Value
Kafka是一个分布式消息系统,Producer生产消息并推送(Push)给Broker,然后Consumer再从Broker那里取走(Pull)消息。Producer生产的消息就是由Message来表示的,对用户来讲,它就是键-值对。
Message => Crc MagicByte Attributes Key Value
- 1

- 1
kafka会根据传进来的key计算其分区,但key可以不传,可以为null,空的话,producer会把这条消息随机的发送给一个partition。

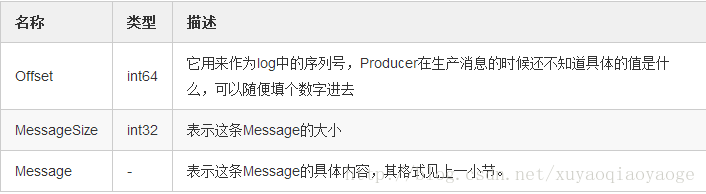
MessageSet用来组合多条Message,它在每条Message的基础上加上了Offset和MessageSize,其结构是:
MessageSet => [Offset MessageSize Message]
- 1
- 1
它的含义是MessageSet是个数组,数组的每个元素由三部分组成,分别是Offset,MessageSize和Message,它们的含义分别是:
七、小例子
1.启动ZooKeeper
进入kafka目录,加上daemon表示在后台启动,不占用当前的命令行窗口。
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
如果要关闭,下面这个
bin/zookeeper-server-stop.sh
ZooKeeper 的端口号是2181,输入jps查看进程号是QuorumPeerMain
2.启动kafka
在server.properties中加入,第一个是保证你删topic可以删掉,第二个不然的话就报topic找不到的错误:
delete.topic.enable=true
listeners=PLAINTEXT://localhost:9092
然后:
bin/kafka-server-start.sh -daemon config/server.properties
如果要关闭,下面这个
bin/kafka-server-stop.sh
Kafka的端口号是9092,输入jps查看进程号是Kafka
3.创建一个主题(topic)
创建一个名为“test”的Topic,只有一个分区和一个备份:
bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic test
创建好之后,可以通过运行以下命令,查看已创建了哪些topic:
bin/kafka-topics.sh –list –zookeeper localhost:2181
查看具体topic的信息:
bin/kafka-topics.sh –describe –zookeeper localhost:2181 –topic test
4.发送消息
启动kafka生产者:
bin/kafka-console-producer.sh –broker-list localhost:9092 –topic test
5.接收消息
新开一个命令行窗口,启动kafka消费者:
bin/kafka-console-consumer.sh –zookeeper localhost:2181 –topic test –from-beginning
6.最后
在producer窗口中输入消息,可以在consumer窗口中显示:


spark streaming
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
Spark Streaming的优势在于:
能运行在100+的结点上,并达到秒级延迟。
使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
能集成Spark的批处理和交互查询。
为实现复杂的算法提供和批处理类似的简单接口。
首先,Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块。Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据。每个块都会生成一个Spark Job处理,最终结果也返回多块。
在Spark Streaming中,则通过操作DStream(表示数据流的RDD序列)提供的接口,这些接口和RDD提供的接口类似。
正如Spark Streaming最初的目标一样,它通过丰富的API和基于内存的高速计算引擎让用户可以结合流式处理,批处理和交互查询等应用。因此Spark Streaming适合一些需要历史数据和实时数据结合分析的应用场合。当然,对于实时性要求不是特别高的应用也能完全胜任。另外通过RDD的数据重用机制可以得到更高效的容错处理。
当一个上下文(context)定义之后,你必须按照以下几步进行操作:
定义输入源;
准备好流计算指令;
利用streamingContext.start()方法接收和处理数据;
处理过程将一直持续,直到streamingContext.stop()方法被调用。
可以利用已经存在的SparkContext对象创建StreamingContext对象:
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))
- 1
- 2
- 1
- 2
窗口函数
对于spark streaming中的窗口函数,参见:
窗口函数解释
对非(K,V)形式的RDD 窗口化reduce:
1.reduceByWindow(reduceFunc, windowDuration, slideDuration)
2.reduceByWindow(reduceFunc, invReduceFunc, windowDuration, slideDuration)
对(K,V)形式RDD 按Key窗口化reduce:
1.reduceByKeyAndWindow(reduceFunc, windowDuration, slideDuration)
2.reduceByKeyAndWindow(reduceFunc, invReduceFunc, windowDuration, slideDuration, numPartitions, filterFunc)
从效率来说,应选择带有invReduceFunc的方法。
可以通过在多个RDD或者批数据间重用连接对象做更进一步的优化。开发者可以保有一个静态的连接对象池,重复使用池中的对象将多批次的RDD推送到外部系统,以进一步节省开支:
dstream.foreachRDD(rdd => {
rdd.foreachPartition(partitionOfRecords => {
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
})
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
spark执行时间是少了,但数据库压力比较大,会一直占资源。
小例子:
package SparkStreaming
import org.apache.spark._
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
object Spark_streaming_Test {
def main(args: Array[String]): Unit = {
//local[2]表示在本地建立2个working线程
//当运行在本地,如果你的master URL被设置成了“local”,这样就只有一个核运行任务。这对程序来说是不足的,因为作为receiver的输入DStream将会占用这个核,这样就没有剩余的核来处理数据了。
//所以至少得2个核,也就是local[2]
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//时间间隔是1秒
val ssc = new StreamingContext(conf, Seconds(1))
//有滑动窗口时,必须有checkpoint
ssc.checkpoint("F:\\checkpoint")
//DStream是一个基类
//ssc.socketTextStream() 将创建一个 SocketInputDStream;这个 InputDStream 的 SocketReceiver 将监听服务器 9999 端口
//ssc.socketTextStream()将 new 出来一个 DStream 具体子类 SocketInputDStream 的实例。
val lines = ssc.socketTextStream("192.168.1.66", 9999, StorageLevel.MEMORY_AND_DISK_SER)
// val lines = ssc.textFileStream("F:\\scv")
val words = lines.flatMap(_.split(" ")) // DStream transformation
val pairs = words.map(word => (word, 1)) // DStream transformation
// val wordCounts = pairs.reduceByKey(_ + _) // DStream transformation
//每隔3秒钟,计算过去5秒的词频,显然一次计算的内容与上次是有重复的。如果不想重复,把2个时间设为一样就行了。
// val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(5), Seconds(3))
val windowedWordCounts = pairs.reduceByKeyAndWindow(_ + _, _ - _, Seconds(5), Seconds(3))
windowedWordCounts.filter(x => x._2 != 0).print()
// wordCounts.print() // DStream output,打印每秒计算的词频
//需要注意的是,当以上这些代码被执行时,Spark Streaming仅仅准备好了它要执行的计算,实际上并没有真正开始执行。在这些转换操作准备好之后,要真正执行计算,需要调用如下的方法
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
//在StreamingContext上调用stop()方法,也会关闭SparkContext对象。如果只想仅关闭StreamingContext对象,设置stop()的可选参数为false
//一个SparkContext对象可以重复利用去创建多个StreamingContext对象,前提条件是前面的StreamingContext在后面StreamingContext创建之前关闭(不关闭SparkContext)
ssc.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
1.启动
start-dfs.sh
start-yarn.sh
2.终端输入:
nc -lk 9999
然后在IEDA中运行spark程序。由于9999端口中还没有写东西,所以运行是下图:

只有时间,没有打印出东西。然后在终端输入下面的东西,也可以从其他地方复制进来。
hello world
hello hadoop
hadoop love
love cat
cat love rabbit
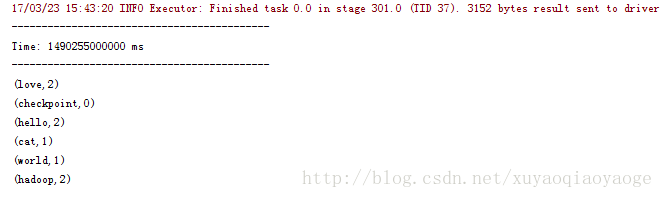
这时,IDEA的控制台就输出下面的东西。

3.下面运行带时间窗口的,注意如果加了时间窗口就必须有checkpoint
输入下面的,不要一次全输入,一次输个几行。
checkpoint
hello world
hello hadoop
hadoop love
love cat
cat love rabbit
ni hao a
hello world
hello hadoop
hadoop love
love cat
cat love rabbit
hello world
hello hadoop
hadoop love
love cat
cat love rabbit
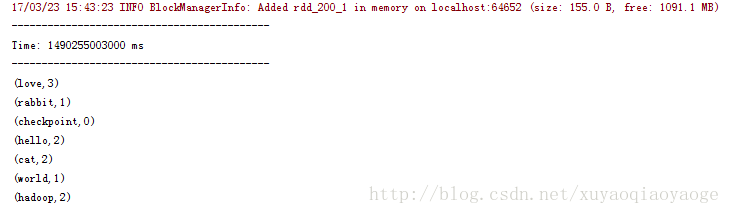
先是++–的那种:

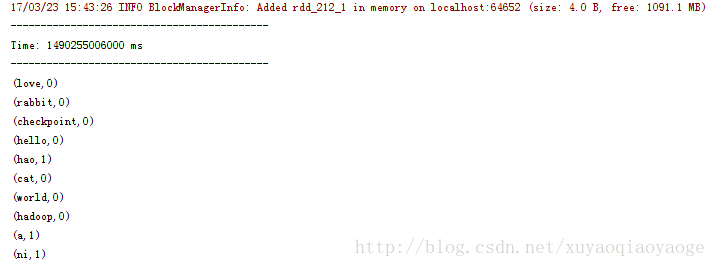
再然后是不++–的那种:
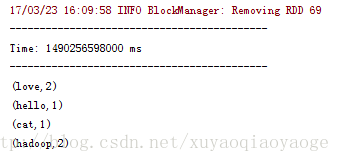

++–的那种是因为把过去的RDD也带进来计算了,所以出现了0这个情况,为了避免这种情况只能在打印前过滤掉0的再打印。而没有++–的那种情况是不需要这样做的。
Checkpointing
在容错、可靠的文件系统(HDFS、s3等)中设置一个目录用于保存checkpoint信息。就可以通过streamingContext.checkpoint(checkpointDirectory)方法来做。
默认的间隔时间是批间隔时间的倍数,最少10秒。它可以通过dstream.checkpoint来设置。需要注意的是,随着 streaming application 的持续运行,checkpoint 数据占用的存储空间会不断变大。因此,需要小心设置checkpoint 的时间间隔。设置得越小,checkpoint 次数会越多,占用空间会越大;如果设置越大,会导致恢复时丢失的数据和进度越多。一般推荐设置为 batch duration 的5~10倍。
package streaming
import java.io.File
import java.nio.charset.Charset
import com.google.common.io.Files
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by Administrator on 2017/3/12.
*/
object RecoverableNetworkWordCount {
def createContext(ip: String, port: Int, outputPath: String, checkpointDirectory: String): StreamingContext = {
println("Creating new context") //如果没有出现这句话,说明StreamingContext是从checkpoint里面加载的
val outputFile = new File(outputPath) //输出文件的目录
if (outputFile.exists()) outputFile.delete()
val sparkConf = new SparkConf().setAppName("RecoverableNetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1)) //时间间隔是1秒
ssc.checkpoint(checkpointDirectory) //设置一个目录用于保存checkpoint信息
val lines = ssc.socketTextStream(ip, port)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
val windowedWordCounts = wordCounts.reduceByKeyAndWindow(_ + _, _ - _, Seconds(30), Seconds(10))
windowedWordCounts.checkpoint(Seconds(10))//一般推荐设置为 batch duration 的5~10倍,即StreamingContext的第二个参数的5~10倍
windowedWordCounts.print()
Files.append(windowedWordCounts + "\n", outputFile, Charset.defaultCharset())
ssc
}
def main(args: Array[String]): Unit = {
if (args.length != 4) {
System.exit(1)
}
val ip = args(0)
val port = args(1).toInt
val checkpointDirectory = args(2)
val outputPath = args(3)
val ssc = StreamingContext.getOrCreate(checkpointDirectory, () => createContext(ip, port, outputPath, checkpointDirectory))
ssc.start()
ssc.awaitTermination()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
优化
1.数据接收的并行水平
创建多个输入DStream并配置它们可以从源中接收不同分区的数据流,从而实现多数据流接收。因此允许数据并行接收,提高整体的吞吐量。
val numStreams = 5
val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }
val unifiedStream = streamingContext.union(kafkaStreams)
unifiedStream.print()
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
多输入流或者多receiver的可选的方法是明确地重新分配输入数据流(利用inputStream.repartition()),在进一步操作之前,通过集群的机器数分配接收的批数据。
2.任务序列化
运行kyro序列化任何可以减小任务的大小,从而减小任务发送到slave的时间。
val conf = new SparkConf().setAppName("analyse_domain_day").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
- 1
- 2
- 1
- 2
3.设置合适的批间隔时间(即批数据的容量)
批处理时间应该小于批间隔时间。如果时间间隔是1秒,但处理需要2秒,则处理赶不上接收,待处理的数据会越来越多,最后就嘣了。
找出正确的批容量的一个好的办法是用一个保守的批间隔时间(5-10,秒)和低数据速率来测试你的应用程序。为了验证你的系统是否能满足数据处理速率,你可以通过检查端到端的延迟值来判断(可以在Spark驱动程序的log4j日志中查看”Total delay”或者利用StreamingListener接口)。如果延迟维持稳定,那么系统是稳定的。如果延迟持续增长,那么系统无法跟上数据处理速率,是不稳定的。你能够尝试着增加数据处理速率或者减少批容量来作进一步的测试。
DEMO
spark流操作kafka有两种方式:
一种是利用接收器(receiver)和kafaka的高层API实现。
一种是不利用接收器,直接用kafka底层的API来实现(spark1.3以后引入)。
相比基于Receiver方式有几个优点:
1、不需要创建多个kafka输入流,然后Union他们,而使用DirectStream,spark Streaming将会创建和kafka分区一样的RDD的分区数,而且会从kafka并行读取数据,Spark的分区数和Kafka的分区数是一一对应的关系。
2、第一种实现数据的零丢失是将数据预先保存在WAL中,会复制一遍数据,会导致数据被拷贝两次:一次是被Kafka复制;另一次是写入到WAL中。
Direct的方式是会直接操作kafka底层的元数据信息,这样如果计算失败了,可以把数据重新读一下,重新处理。即数据一定会被处理。拉数据,是RDD在执行的时候直接去拉数据。
3、Receiver方式读取kafka,使用的是高层API将偏移量写入ZK中,虽然这种方法可以通过数据保存在WAL中保证数据的不对,但是可能会因为sparkStreaming和ZK中保存的偏移量不一致而导致数据被消费了多次。
第二种方式不采用ZK保存偏移量,消除了两者的不一致,保证每个记录只被Spark Streaming操作一次,即使是在处理失败的情况下。如果想更新ZK中的偏移量数据,需要自己写代码来实现。
由于直接操作的是kafka,kafka就相当于你底层的文件系统。这个时候能保证严格的事务一致性,即一定会被处理,而且只会被处理一次。
首先去maven的官网上下载jar包
spark-streaming_2.10-1.6.2.jar
spark-streaming-kafka_2.10-1.6.2.jar
我的Scala是2.10的,spark是1.6.0的,下载的spark.streaming和kafka版本要与之对应,spark-streaming_2.10-1.6.2.jar中2.10是scala版本号,1.6.2是spark版本号。当然下载1.6.1也行。
需要添加 kafka-clients-0.8.2.1.jar以及kafka_2.10-0.8.2.1.jar
这里的2.10是Scala版本号,0.8.2.1是kafka的版本号。就下这个版本,别的版本不对应,会出错。
在kafka的配置文件里面:
delete.topic.enable=true
host.name=192.168.1.66
zookeeper.connect=192.168.1.66:2181
我这里写主机名的话,各种报错,所以干脆就写IP地址了。
启动kafka以及ZK的步骤和kafka 1-2是一样的。
进入/kafka_2.10-0.8.2.1 新建一个主题:
bin/kafka-topics.sh –create –zookeeper 192.168.1.66:2181 –replication-factor 1 –partitions 1 –topic test
启动一个生产者:
bin/kafka-console-producer.sh –broker-list 192.168.1.66:9092 –topic test
在自己的电脑上运行spark程序后,在命令行输入:
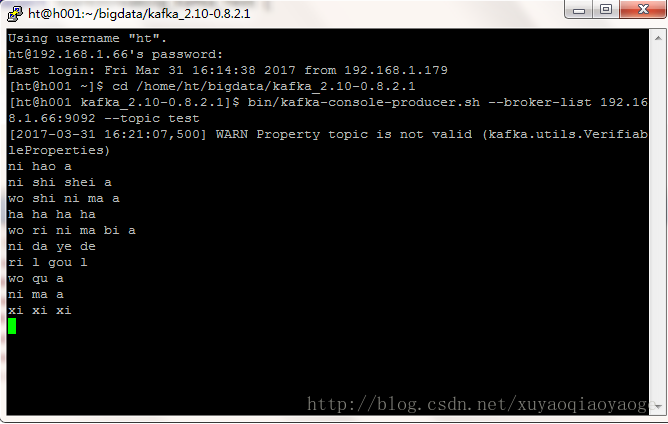
在控制台会显示:

package SparkStreaming
//TopicAndPartition是对 topic和partition的id的封装的一个样例类
import kafka.common.TopicAndPartition
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import kafka.serializer.StringDecoder
object SparkStreaming_Kafka_Test {
val kafkaParams = Map(
//kafka broker的IP加端口号,这个是必须的
"metadata.broker.list" -> "192.168.1.66:9092",
// "group.id" -> "group1",
/*此配置参数表示当此groupId下的消费者,
在ZK中没有offset值时(比如新的groupId,或者是zk数据被清空),
consumer应该从哪个offset开始消费.largest表示接受接收最大的offset(即最新消息),
smallest表示最小offset,即从topic的开始位置消费所有消息.*/
"auto.offset.reset" -> "smallest"
)
val topicsSet = Set("test")
// val zkClient = new ZkClient("xxx:2181,xxx:2181,xxx:2181",Integer.MAX_VALUE,100000,ZKStringSerializer)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("SparkStreaming_Kafka_Test")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(2))
ssc.checkpoint("F:\\checkpoint")
/*
KafkaUtils.createDirectStream[
[key的数据类型], [value的数据类型], [key解码的类], [value解码的类] ](
streamingContext, [Kafka配置的参数,是一个map], [topics的集合,是一个set])
*/
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
val lines = messages.map(_._2) //取value
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
偏移量仅仅被ssc保存在checkpoint中,消除了zk和ssc偏移量不一致的问题。所以说checkpoint就已经可以保证容错性了。
如果需要把偏移量写入ZK,首先在工程中新建一个包:org.apache.spark.streaming.kafka,然后建一个KafkaCluster类:
package org.apache.spark.streaming.kafka
import kafka.api.OffsetCommitRequest
import kafka.common.{ErrorMapping, OffsetAndMetadata, TopicAndPartition}
import kafka.consumer.SimpleConsumer
import org.apache.spark.SparkException
import org.apache.spark.streaming.kafka.KafkaCluster.SimpleConsumerConfig
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
import scala.util.control.NonFatal
class KafkaCluster(val kafkaParams: Map[String, String]) extends Serializable {
type Err = ArrayBuffer[Throwable]
@transient private var _config: SimpleConsumerConfig = null
def config: SimpleConsumerConfig = this.synchronized {
if (_config == null) {
_config = SimpleConsumerConfig(kafkaParams)
}
_config
}
def setConsumerOffsets(groupId: String, offsets: Map[TopicAndPartition, Long], consumerApiVersion: Short): Either[Err, Map[TopicAndPartition, Short]] = {
val meta = offsets.map {
kv => kv._1 -> OffsetAndMetadata(kv._2)
}
setConsumerOffsetMetadata(groupId, meta, consumerApiVersion)
}
def setConsumerOffsetMetadata(groupId: String, metadata: Map[TopicAndPartition, OffsetAndMetadata], consumerApiVersion: Short): Either[Err, Map[TopicAndPartition, Short]] = {
var result = Map[TopicAndPartition, Short]()
val req = OffsetCommitRequest(groupId, metadata, consumerApiVersion)
val errs = new Err
val topicAndPartitions = metadata.keySet
withBrokers(Random.shuffle(config.seedBrokers), errs) { consumer =>
val resp = consumer.commitOffsets(req)
val respMap = resp.commitStatus
val needed = topicAndPartitions.diff(result.keySet)
needed.foreach { tp: TopicAndPartition =>
respMap.get(tp).foreach { err: Short =>
if (err == ErrorMapping.NoError) {
result += tp -> err
} else {
errs.append(ErrorMapping.exceptionFor(err))
}
}
}
if (result.keys.size == topicAndPartitions.size) {
return Right(result)
}
}
val missing = topicAndPartitions.diff(result.keySet)
errs.append(new SparkException(s"Couldn't set offsets for ${missing}"))
Left(errs)
}
private def withBrokers(brokers: Iterable[(String, Int)], errs: Err)(fn: SimpleConsumer => Any): Unit = {
brokers.foreach { hp =>
var consumer: SimpleConsumer = null
try {
consumer = connect(hp._1, hp._2)
fn(consumer)
} catch {
case NonFatal(e) =>
errs.append(e)
} finally {
if (consumer != null) {
consumer.close()
}
}
}
}
def connect(host: String, port: Int): SimpleConsumer =
new SimpleConsumer(host, port, config.socketTimeoutMs,
config.socketReceiveBufferBytes, config.clientId)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
然后在主函数中:
// 手动更新ZK偏移量,使得基于ZK偏移量的kafka监控工具可以使用
messages.foreachRDD(rdd => {
// 先处理消息
val lines = rdd.map(_._2) //取value
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.foreach(println)
// 再更新offsets
//spark内部维护kafka偏移量信息是存储在HasOffsetRanges类的offsetRanges中
//OffsetRange 包含信息有:topic名字,分区Id,开始偏移,结束偏移。
val offsetsList = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //得到该 rdd 对应 kafka 的消息的 offset
val kc = new KafkaCluster(kafkaParams)
for (offsets <- offsetsList) {
val topicAndPartition = TopicAndPartition("test", offsets.partition)
val o = kc.setConsumerOffsets("group1", Map((topicAndPartition, offsets.untilOffset)),8)
if (o.isLeft) {
println(s"Error updating the offset to Kafka cluster: ${o.left.get}")
}
}
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
下面是用kafka的API自己写一个程序读取文件,作为kafka的生产者,需要将Scala和kafka的所有的jar包都导入,lib文件夹下面的都导入进去。
如果没有2台电脑,可以开2个开发环境,IDEA作为消费者,eclipse作为生产者。
生产者代码如下:
package spark_streaming_kafka_test;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class MakeRealtimeDate extends Thread {
private Producer<Integer, String> producer;
public MakeRealtimeDate() {
Properties props = new Properties();
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("zk.connect", "192.168.1.66:2181");
props.put("metadata.broker.list", "192.168.1.66:9092");
ProducerConfig pc = new ProducerConfig(props);
producer = new Producer<Integer, String>(pc);
}
public void run() {
while (true) {
File file = new File("C:\\Users\\Administrator\\Desktop\\wordcount.txt");
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
} catch (FileNotFoundException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
String lineTxt = null;
try {
while ((lineTxt = reader.readLine()) != null) {
System.out.println(lineTxt);
producer.send(new KeyedMessage<Integer, String>("test", lineTxt));
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new MakeRealtimeDate().start();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
先启动之前写的sparkstreaming消费者统计单词个数的程序,然后再启动我们现在写的这个生产者程序,最后就会在IDEA的控制台中看到实时结果。














 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









