









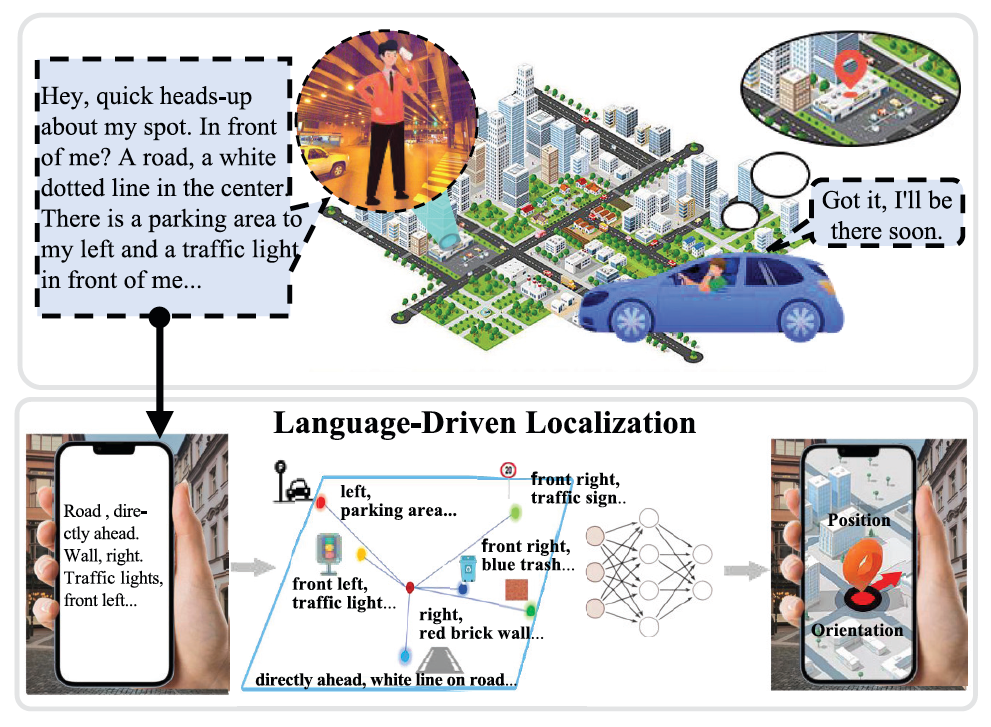
在ChatGPT、DeepSeek等大语言模型(LLM)不断重塑人机交互方式的今天,我们能否让AI像人一样,通过语言描述来理解空间场景,并实现精准用户定位?
定位能力对智能设备至关重要。无论是机器人、自动驾驶汽车,还是智能穿戴设备,都离不开对位置和姿态的准确感知。然而,传统的全球导航卫星系统(GNSS)在地下空间、密集城市区域或隧道等环境中,信号容易衰减或被遮挡。视觉定位技术虽然有助于弥补这一短板,但在光照变化剧烈、场景动态频繁或隐私敏感区域中,依然容易失效。相比之下,人类擅长通过语言来描述和理解空间场景。即使在高楼林立、信号微弱的城市街区,我们也能用一句简单的话准确传达自己的位置,比如:“我在地铁出口旁的便利店附近。”这一自然的语言定位能力,启发了新的研究方向——让智能设备也能通过语言进行定位。
近期,陈昶昊教授和合作者在国际高质量学术期刊IEEE Transactions on Image Processing上发表题为LangLoc: Language-Driven Localization via Formatted Spatial Description Generation的研究论文,开创性地提出了“语言驱动定位”(Language-driven Localization)的新范式。
论文链接(或点击“阅读原文”跳转):
https://ieeexplore.ieee.org/abstract/document/10923622

一、重新思考基于语言的空间理解
语言能够为场景提供抽象且稳定的语义线索,为定位问题的解决打开了全新的想象空间。然而,目前基于语言的空间理解与定位研究仍处于相对较少的状态。随着大语言模型(LLMs)的快速发展,AI在理解自然语言复杂性与多样性方面取得了诸多进展,也展现出在空间描述与定位任务中的巨大潜力。但自然语言固有的模糊性与随机性,叠加环境的动态变化,使得基于语言的空间定位依旧面临挑战。

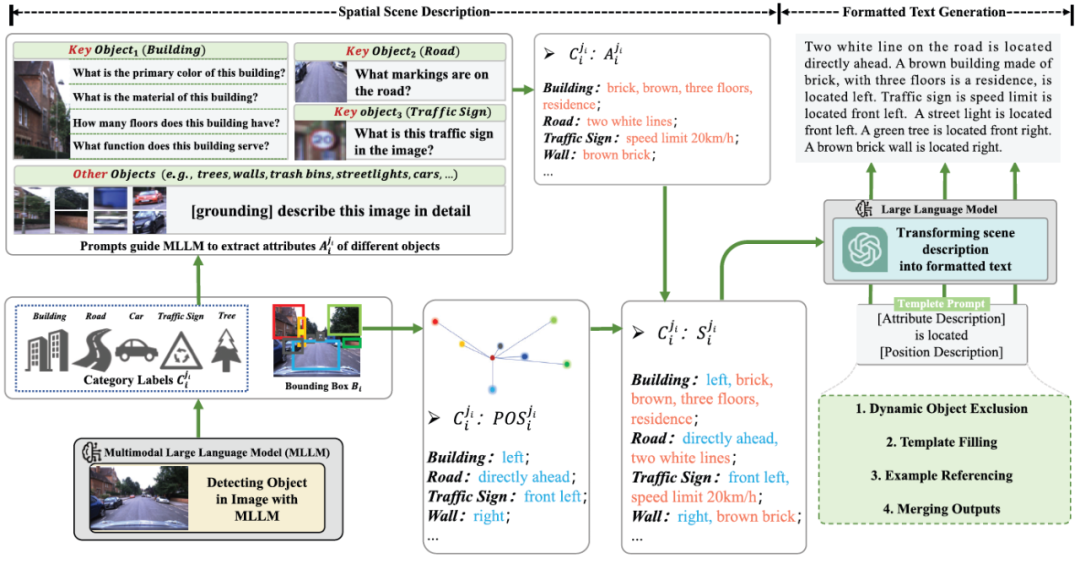
针对这些难题,本研究构建了空间描述生成器(Spatial Description Generator, SDG)。该生成器由两大核心模块组成:一是空间场景描述模块(SSD),负责提取场景中关键物体的位置坐标与属性信息,生成细致入微的空间描述;二是格式化文本生成模块(FTG),通过引导大语言模型(如GPT-3)筛除动态对象,将描述内容规范化,从而精准呈现场景的空间布局与物体间关系。
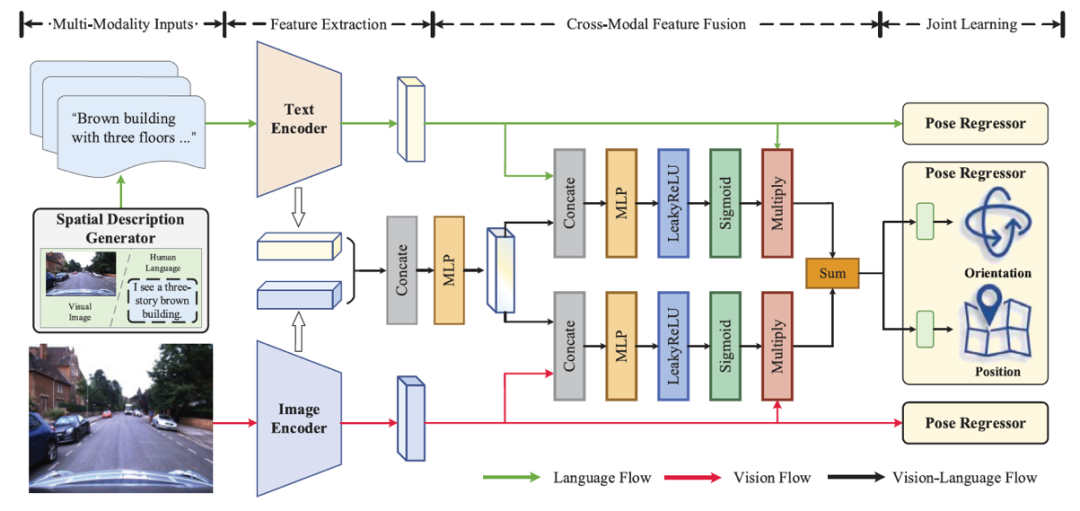
借助这样的设计,语言驱动定位的学习框架(LangLoc)有效消除了语言描述中的歧义,为空间感知奠定了坚实可靠的基础。基于这些标准化描述,LangLoc仅需搭配简单的文本编码器和位姿回归器,就能实现纯语言定位。并且,在具备视觉数据的情况下,LangLoc还能通过双模态编码器、跨模态融合模块以及多模态联合学习策略,自适应地融合语言语义与视觉空间特征,进一步提升定位的准确性与鲁棒性。

二、语言驱动定位(LangLoc)技术框架
(1)空间描述生成器(SDG):由空间场景描述模块(SSD)和格式化文本生成模块(FTG)构成。SSD承担着提取场景中物体位置坐标与关键属性的任务,生成精细的空间场景描述。在3D场景中精准定位用户,关键在于从与定位任务相关的场景对象中提取核心空间信息。为此,研究团队首先借助多模态大语言模型(Multimodal Large-Language Model, MLLM,如MiniGPT-v2)获取图像中对象的类别标签与边界框位置。为进一步提取不同对象的关键属性,通过类别关联的提示词,引导多模态大语言模型聚焦特定属性抽取,并将场景对象划分为关键对象与其他对象。对于建筑物、交通标志、街道等关键物体,定制了一系列针对性的问题提示词:涉及材质的「该建筑的主要材质是什么?」;关于颜色的「该建筑的主色调是什么?」;询问楼层数量的「该建筑有多少层?」;以及探究功能的「该建筑的用途是什么?」等。SSD系统系统性地提取这些空间信息,形成全面的空间场景描述,并将其输入FTG,为精准定位提供有力支撑。
(2)格式化文本生成:为保证跨场景语言描述的格式统一,便于下游位姿估计高效提取关键语义特征,研究引入了格式化文本生成模块(Formatted Text Generation, FTG)。该模块将SSD生成的空间场景描述转化为规范的格式化文本,通过引导大语言模型排除动态对象,并将描述组织成统一格式,大幅减少歧义,精准传递空间布局与物体关系。其中,Template作为包含多项操作指令的模板提示,引导大语言模型(如 GPT-3.5)完成动态对象排除、模板填充、示例参考和输出合并等一系列操作。

(3)纯语言定位:基于SDG生成的格式化文本描述,对LangLoc框架进行端到端训练,即可实现纯语言定位,将文本描述精准映射到位姿信息。这一成果意义非凡,即便在没有直接视觉输入的情况下,LangLoc也能凭借自然语言准确推断定位信息,成为首个实现纯自然语言定位的研究成果。
(4)视觉/语言定位:此模式将输入拓展为语言与视觉融合形式。首先利用两个模态专用编码器分别处理文本和图像输入,捕获不同模态特征;接着通过跨模态融合技术整合这些特征,形成全面的潜在表征;最后借助多模态联合学习策略,优化对位姿的学习效果,实现更加精准、稳定的定位。

三、实验验证
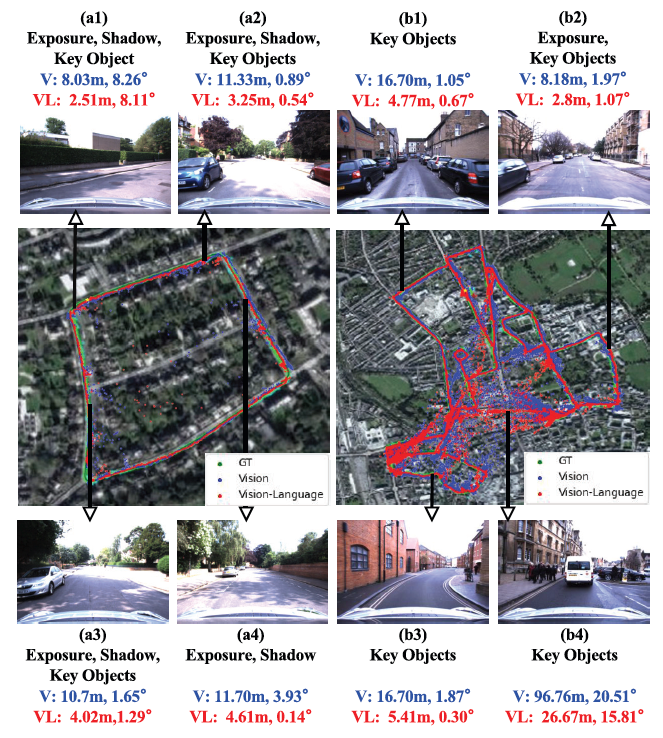
在车载数据集上的实验显示,LangLoc仅用语言定位时,定位误差中位数分别为29.48 米和6.79°,达到城市定位中误差小于50米即有效的公认基准,且对人类自然语言输入也能有效定位。

整合图像和文本输入后,在Oxford RobotCar、4-Seasons和Virtual Gallery数据集上性能显著提升,视觉-语言定位模式可适应室内外场景,在图像退化和模态缺失时也表现出更强的鲁棒性。
这项研究为智能设备的空间理解开辟了新的思路——未来的机器人、智能穿戴设备,甚至手机,也许只需一句话描述周围环境,就能精准了解自己身处何处。

教授专栏
由香港科技大学主理出品的【教授专栏】,汇集来自不同领域教授的学术成果、前沿论断及知识科普,用最新鲜的视角解读社会动态,以最前沿的角度解释科技奥秘。期待通过香港科技大学的平台,聚合更多新锐观点,打造出一期又一期生动又深刻的【教授专栏】!
教授简介

陈昶昊教授(Dr. Changhao Chen),香港科技大学(广州)系统枢纽智能交通学域和信息枢纽人工智能学域联聘助理教授(副研究员),博士生导师。获英国牛津大学计算机科学博士学位,并在英国工程和自然科学研究委员会(EPSRC)资助下从事博士后研究。先后入选全球前2%顶尖科学家榜单(2024)、中国科协青年人才托举工程(2022)和国际机器人科学与系统大会(Robotics Science and Systems)先锋者(2020)。
研究聚焦具身智能和无人系统前沿探索,致力于构建开放环境交互的具身智能体,服务低空经济、智能交通和智慧城市。主持国家自然科学基金等纵向项目5项,三次获/提名权威学术会议论文奖(2016, 2019, 2022)。在人工智能、机器人和智能交通领域已发表高水平论文50余篇,包括TNNLS、TITS、TMC、TIP、TIV等领域权威期刊以及AAAI、CVPR、ICCV、ECCV、ICRA、IROS、WWW、MobiCom、MobiSys、SenSys等国际顶级会议,谷歌学术引用超过3100次。长期担任超过30个国际顶会、期刊的程序委员会委员/元审稿人/审稿人,中国科协会刊《科技导报》首届青年编委,国际机器人与自动化会议(ICRA)副主编和分会场主席。已授权国家发明专利、国际PCT专利、美国、欧洲、澳大利亚专利共14项,包含1项在英国成功成果转化。
往期回顾
教授专栏169 | 孙建伟,林振阳:破解化学界难题!全球首创手性分子高效合成新方法
教授专栏168 | 周穆之:老年主播与听障交友:数字平台上的"看见"与"看不见"
主编 | 袁冶
责编 | 周姗
核校 | 柳松、许珺、吴倩
来源 | 转载自香港科技大学广州|系统枢纽 公众平台



















 18
18

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









