







目录
一、基本原理
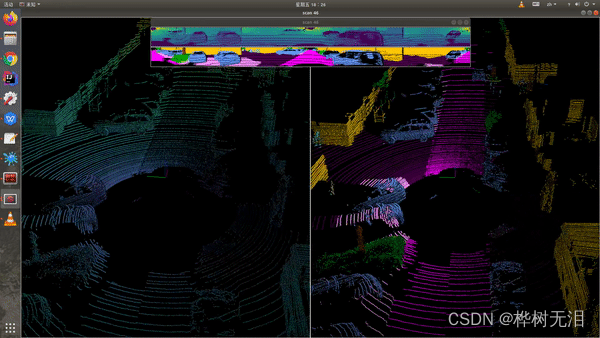
1.1 极坐标划分
点云有越远越稀疏的特性,相对于传统的BEV视角,点云分割更加的均匀。
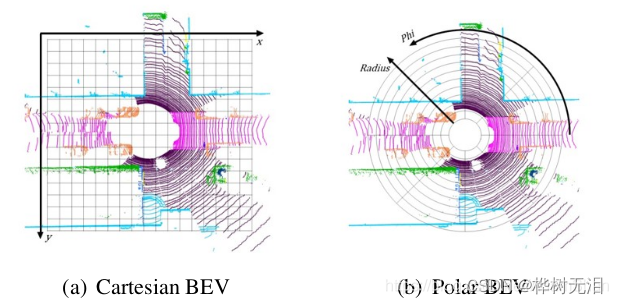
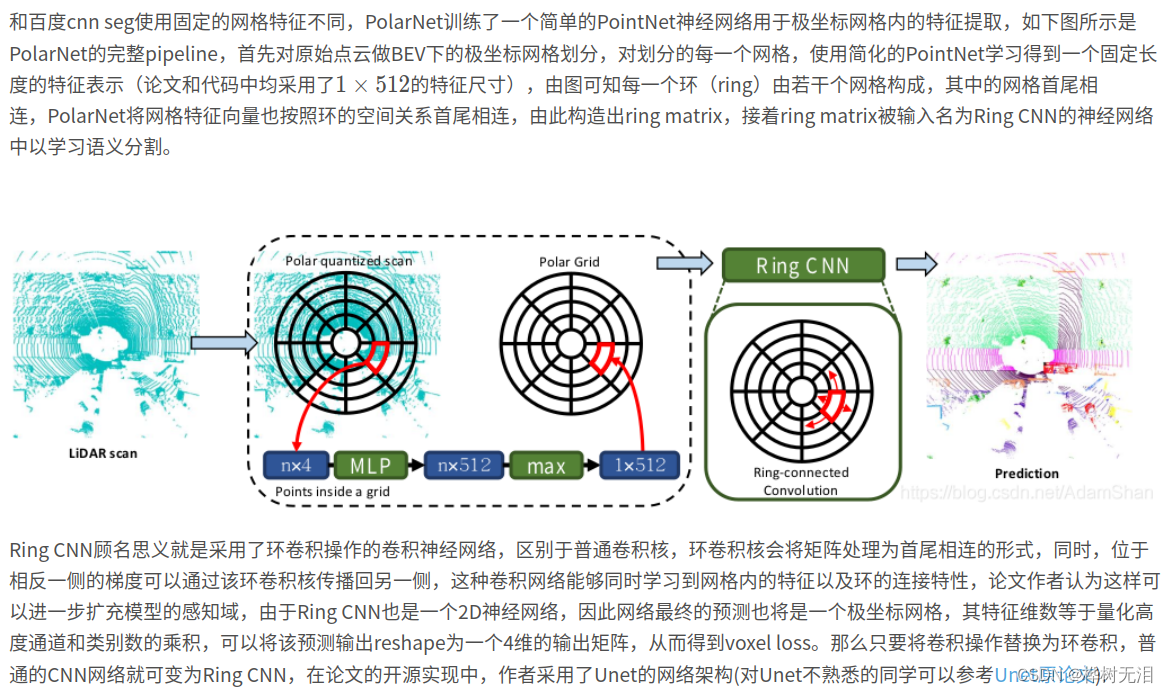
1.2 网络特征提取
二、工程目录
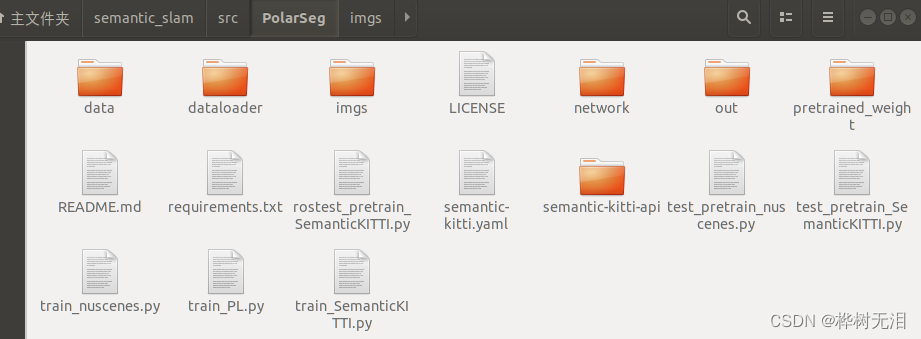
data:数据集
dataloader:数据集下载
imgs:论文配图
network:主网络和相关代码
out:模型结果
pretrained_weight: 模型预训练权重
semantic-kitti-api:semantic-kitti数据集工具包
其他文件为使用文件
三、环境配置
git clone https://github.com/AbangLZU/PolarSeg.git
#1 激活环境
conda activate polarnet
#2 安装pytorch
conda install pytorch torchvision cudatoolkit=11.3 -c pytorch
#3 pytorch >= 1.8.0 安装pytorch-scatter
conda install pytorch-scatter -c pyg
#4 安装其他工具包 将文件中的pytorch相关删除
pip install -r requirement.txt
pip install vispy
pip install matplotlib四、semantic-kitti数据集介绍
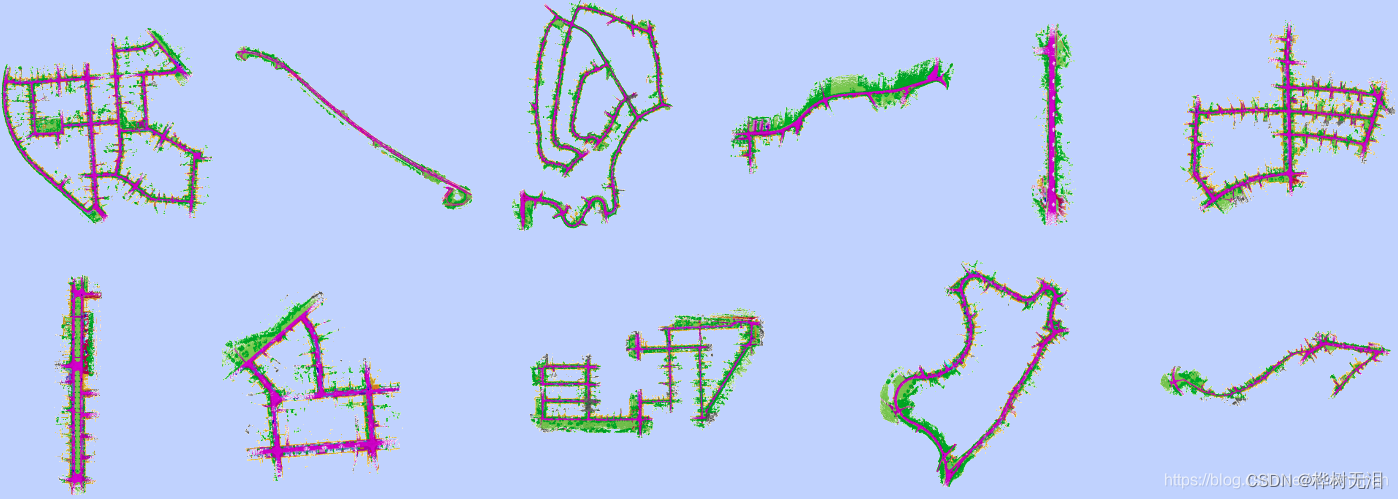
4.1 文件目录
sequences下包含了一系列的数据集

velodyne为64线激光雷达的数据
labels 为点云的标注文件
poses.txt 为里程计的信息
4.2 yaml文件
split: # sequence numbers
train:
- 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 9
- 10
valid:
- 8
test:
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21将数据集的序号分成train val test,以及语义分割的类别和对应的点云颜色

4.3 semantic-kitti-api官方工具包
Semantic-kitti 本身开源了一个工具包以供可视化
git clone https://github.com/AbangLZU/semantic-kitti-api.git
cd semantic-kitti-api
pip install -r requirements.txt
# 可视化
python visualize.py --dataset /path/to/your/kitti/dataset --sequence 00

四、代码运行
4.1 训练
python train_SemanticKITTI.py --data ./data/kitti/dataset训练时需要等一段时间,统计完所有的训练数据集,不要急。统计完之后开始训练。
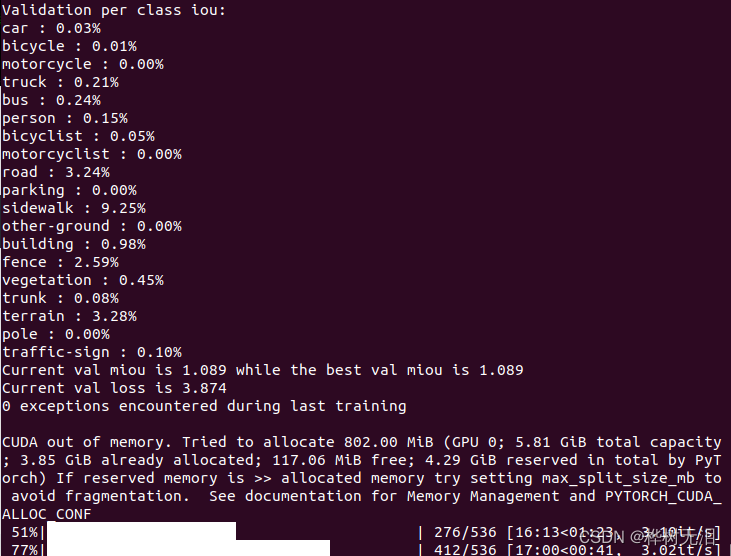
训练完成后,权重保存在与train.py同目录下的SemKITTI_PolarSeg.pt中
4.2 验证
python test_pretrain_SemanticKITTI.py -d ./data/kitti/dataset/ -p ./pretrained_weight/SemKITTI_PolarSeg.pt
通过yaml文件可以知道,11到21为测试集,代码也直接生成这些数据集的预测文件
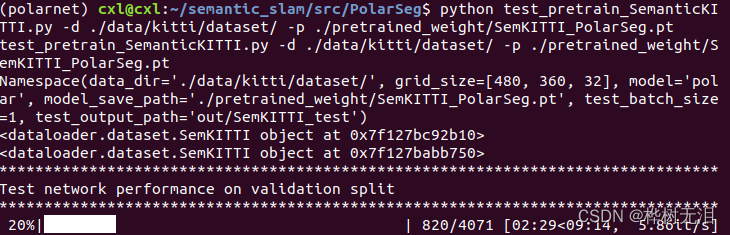
会生成out文件夹,里面存放的预测出来的label文件,将这个文件代替原本数据集的labels,即可进行可视化。
python visualize.py --dataset ./data/kitti/dataset --sequence 13















 1366
1366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











