CSDN爬虫(二)——博客列表分页爬虫+数据库设计
说明
- 开发环境:jdk1.7+myeclipse10.7+win74bit+mysql5.5+webmagic0.5.2+jsoup1.7.2
- 爬虫框架:webMagic
- 建议:建议首先阅读webMagic的文档,再查看此系列文章,便于理解,快速学习:http://webmagic.io/
- 开发所需jar下载(不包括数据库操作相关jar包):点我下载
- 该系列文章会省略webMagic文档已经讲解过的相关知识。
博客列表爬虫核心代码预览
package com.wgyscsf.spider;
import java.util.List;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.selector.Html;
import us.codecraft.webmagic.selector.Selectable;
import com.wgyscsf.utils.MyStringUtils;
/**
* @author wgyscsf</n> 编写日期 2016-9-24下午7:25:36</n> 邮箱 wgyscsf@163.com</n> 博客
* http://blog.csdn.net/wgyscsf</n> TODO</n>
*/
public class CsdnBlogListSpider extends BaseSpider {
private Site site = Site
.me()
.setDomain("blog.csdn.net")
.setSleepTime(300)
.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override
public void process(Page page) {
// 列表页: 这里进行匹配,匹配出列表页进行相关处理。在列表页我们获取必要信息。对于全文、评论、顶、踩在文章详情中。
if ((page.getUrl()).regex(
"^http://blog.csdn.net/\\w+/article/list/[0-9]*[1-9][0-9]*$")
.match()) {
// 遍历出页码:遍历出div[@class=\"pagelist\"]节点下的所有超链接,该链接下是页码链接。将其加入到爬虫队列。【核心代码】
page.addTargetRequests(page
.getHtml()
.xpath("//div[@class=\"list_item_new\"]//div[@class=\"pagelist\"]")
.links().all());
// 作者
Selectable links = page.getHtml()
.xpath("//div[@class=\"header\"]//div[@id=\"blog_title\"]")
.links();
String blogUrl = links.get();
String id_author = MyStringUtils.getLastSlantContent(blogUrl);
id_author = id_author != null ? id_author : "获取作者id失败";
// System.out.println(TAG + author);
// 获取列表最外层节点的所有子节点。经过分析可以知道子节点有3个,“置顶文章”列表和“普通文章列表”和分页div。
List<String> out_div = page.getHtml()
.xpath("//div[@class=\"list_item_new\"]/div").all();
// 判断是否存在置顶文章:如何div的个数为3说明存在置顶文章,否则不存在置顶文章。
if (out_div.size() == 3) {
// 存在
processTopArticle(out_div.get(0), id_author);
processCommArticle(out_div.get(1), id_author);
} else if (out_div.size() == 2) {
// 不存在
processCommArticle(out_div.get(0), id_author);
} else {
System.err.println(TAG + ":逻辑出错");
}
} else if (page.getUrl()
.regex("http://blog.csdn.net/\\w+/article/details/\\w+")
.match()) {
// 这里的逻辑还没处理,主要是为了获取全文、标签、顶、踩、评论等在列表页获取不到的数据
}
}
/**
* 处理普通文章列表
*/
private void processCommArticle(String str, String id_author) {
// 从列表页获取列表信息
List<String> all;
all = new Html(str).xpath("//div[@id=\"article_list\"]/div").all();
if (!all.isEmpty())
for (String string : all) {
// 这里开始获取具体内容
// 单项第一部分:article_title
// 文章地址
String detailsUrl = new Html(string)
.xpath("//div[@class='article_title']//span[@class='link_title']//a/@href")
.toString();
// 文章id
String id_blog = MyStringUtils.getLastSlantContent(detailsUrl);
// 文章标头
String title = new Html(string)
.xpath("//div[@class='article_title']//span[@class='link_title']//a/text()")
.toString();
// 文章类型
String type = getArticleType(string);
// 单项第二部分:article_description
String summary = new Html(string).xpath(
"//div[@class='article_description']//text()")
.toString();
// 单项第三部分:article_manage
String publishDateTime = new Html(string)
.xpath("//div[@class='article_manage']//span[@class='link_postdate']//text()")
.toString();
// 阅读量
String viewNums = new Html(string)
.xpath("//div[@class='article_manage']//span[@class='link_view']//text()")
.toString();
viewNums = MyStringUtils.getStringPureNumber(viewNums);
// 评论数
String commentNums = new Html(string)
.xpath("//div[@class='article_manage']//span[@class='link_comments']//text()")
.toString();
commentNums = MyStringUtils.getStringPureNumber(commentNums);
// 开始组织数据
System.out.println(TAG + ":,文章id:" + id_blog + ",文章标头:" + title
+ ",文章类型('0':原创;'1':转载;'2':翻译):" + type + ",发表日期:"
+ publishDateTime + ",阅读量:" + viewNums + ",评论数:"
+ commentNums + ",文章地址:" + detailsUrl + ",文章摘要:"
+ summary + "");
}
}
/**
* 处理置顶文章列表
*/
private void processTopArticle(String topListDiv, String id_author) {
// 从列表页获取列表信息
List<String> all;
all = new Html(topListDiv).xpath("//div[@id=\"article_toplist\"]/div")
.all();
if (!all.isEmpty())
for (String string : all) {
// 单项第一部分:article_title
// 文章地址
String detailsUrl = new Html(string)
.xpath("//div[@class='article_title']//span[@class='link_title']//a/@href")
.toString();
// 文章id
String id_blog = MyStringUtils.getLastSlantContent(detailsUrl);
// 文章标头
String title = new Html(string)
.xpath("//div[@class='article_title']//span[@class='link_title']//a/text()")
.toString();
// 文章类型
String type = getArticleType(string);
// 单项第二部分:article_description
String summary = new Html(string).xpath(
"//div[@class='article_description']//text()")
.toString();
// 单项第三部分:article_manage
String publishDateTime = new Html(string)
.xpath("//div[@class='article_manage']//span[@class='link_postdate']//text()")
.toString();
// 阅读量
String viewNums = new Html(string)
.xpath("//div[@class='article_manage']//span[@class='link_view']//text()")
.toString();
viewNums = MyStringUtils.getStringPureNumber(viewNums);
// 评论数
String commentNums = new Html(string)
.xpath("//div[@class='article_manage']//span[@class='link_comments']//text()")
.toString();
commentNums = MyStringUtils.getStringPureNumber(commentNums);
// 开始组织数据
System.out.println(TAG + ":,文章id:" + id_blog + ",文章标头:" + title
+ ",文章类型('0':原创;'1':转载;'2':翻译):" + type + ",发表日期:"
+ publishDateTime + ",阅读量:" + viewNums + ",评论数:"
+ commentNums + ",文章地址:" + detailsUrl + ",文章摘要:"
+ summary + "");
}
}
/**
* 获取文章类型
*/
private String getArticleType(String string) {
String type;
type = new Html(string)
.xpath("//div[@class='article_title']//span[@class='ico ico_type_Original']//text()")
.get();// 原创类型
if (type != null)
return 0 + "";
type = new Html(string)
.xpath("//div[@class='article_title']//span[@class='ico ico_type_Repost']//text()")
.get();// 原创类型
if (type != null)
return 1 + "";
type = new Html(string)
.xpath("//div[@class='article_title']//span[@class='ico ico_type_Translated']//text()")
.get();// 原创类型
if (type != null)
return 2 + "";
return 3 + "";
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new CsdnBlogListSpider())
.addPipeline(null)
.addUrl("http://blog.csdn.net/" + "wgyscsf" + "/"
+ "article/list/1").run();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
关键代码解释
page.getUrl()).regex("^http://blog.csdn.net/\\w+/article/list/[0-9]*[1-9][0-9]*$").match() ,每次正则表达式都是一个难点。这句话的意思是:http://blog.csdn.net/用户id/article/list/页码,这个网址包含两个可变字符串:用户id和页码,这个正则主要是为了匹配这个规则。如果是爬取单个用户就不用这个麻烦。但是,后期如果我们有很多用户id,这样写才能更加方便的去爬取任意用户。-
page.addTargetRequests(page.getHtml().xpath("//div[@class=\"list_item_new\"]//div[@class=\"pagelist\"]").links().all())这句话是整个博客列表爬取的核心。它负责找到个页面下所有有效的列表链接,加入到爬虫队列,到爬虫队列,还会走上面所提到的正则进行匹配,加入到列表页的解析,是一个迭代的过程。当然,如果想要更加严谨,也可以做一个正则的匹配,比如我只抓取div[@class=\"pagelist\"]下符合页表页规则的链接。当然,这里是进行了分析,里面只包含有效链接,就没有再进行判断。页码所在的div如下:
<!--显示分页-->
<div id="papelist" class="pagelist">
<span> 49条 共4页</span>
<a href="/wgyscsf/article/list/1">首页</a>
<a href="/wgyscsf/article/list/1">上一页</a>
<a href="/wgyscsf/article/list/1">1</a>
<strong>2</strong>
<a href="/wgyscsf/article/list/3">3</a>
<a href="/wgyscsf/article/list/4">4</a>
<a href="/wgyscsf/article/list/3">下一页</a>
<a href="/wgyscsf/article/list/4">尾页</a>
</div>
-
page.getHtml().xpath("//div[@class=\"list_item_new\"]/div").all();这里需要注意的是,需要判断返回List的个数,进而判断是否存在“置顶文章”。如果存在先处理“置顶文章”逻辑,再处理普通文章逻辑。经过分析可以知道子节点有3个,“置顶文章”列表div和“普通文章”列表div和分页div。
-
getArticleType(String string)特别注意这个方法里面关于文章类型的处理,如何判断是何种类型的文章,可以尝试获取对应文章所处的div,如果返回不为null,即说明存在,否则不存在。大致如下:
String type;
type = new Html(string).xpath("//div[@class='article_title']//span[@class='ico ico_type_Original']//text()").get();// 原创类型
if (type != null)
return 0 + "";// 说明是原创
数据库设计
设计原则
- 全部字段允许为空,包括相关所属唯一id。另外新建一个id,随机生成UUID,作为主键。原因:因为爬虫可能会出现爬不到的数据,或者“脏数据”,所以尽可能使数据库不那么“严谨”,保证程序能够正常走下去。在表中新建一个id作为主键,这个可以保证在获取相应表id失败的情况下,仍然可以正常运行。
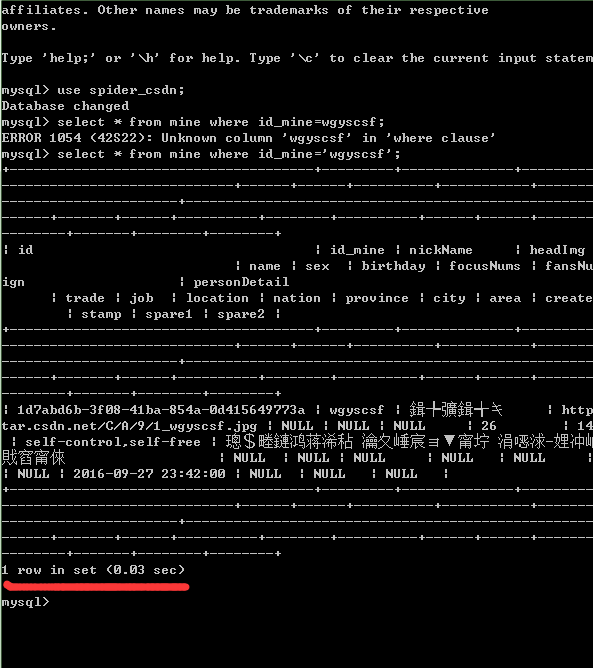
- 每个表的所属id(不是新建的),比如作者id、文章id、个人id等可以标示一行数据的字段,全部加上【索引】。原因:后期需要保存大量用户以及文章数据,保存之前我们需要拿获取到表的id去查询数据库中是否存在,需要有一个查询的过程。查询是一个遍历的过程,加与不加【索引】对程序影响巨大。简单测试如下(不带索引与带索引的查询时间,数据量:80W):

- 尽可能加上所有直接相关的所有字段,不管现有爬虫技术是否能实现。并且,再加上必要的备用字段。原因:数据表修改麻烦,尽可能后期不要修改。不能直接过去的数据,可能会在其它模块获取,比如“博客详情”与“博客列表”之间的关系。
- 不使用外键,原因:同第一条。
- 主键不用自增的,而是采用手动生成。
表结构

建表语句
操作代码
点我下载























 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









