







https://blog.csdn.net/lewky_liu/article/details/78166080
Java高并发秒杀API(四)之高并发优化
1. 高并发优化分析
关于并发
并发性上不去是因为当多个线程同时访问一行数据时,产生了事务,因此产生写锁,每当一个获取了事务的线程把锁释放,另一个排队线程才能拿到写锁,QPS(Query Per Second每秒查询率)和事务执行的时间有密切关系,事务执行时间越短,并发性越高,这也是要将费时的I/O操作移出事务的原因。
在本项目中高并发发生在哪?
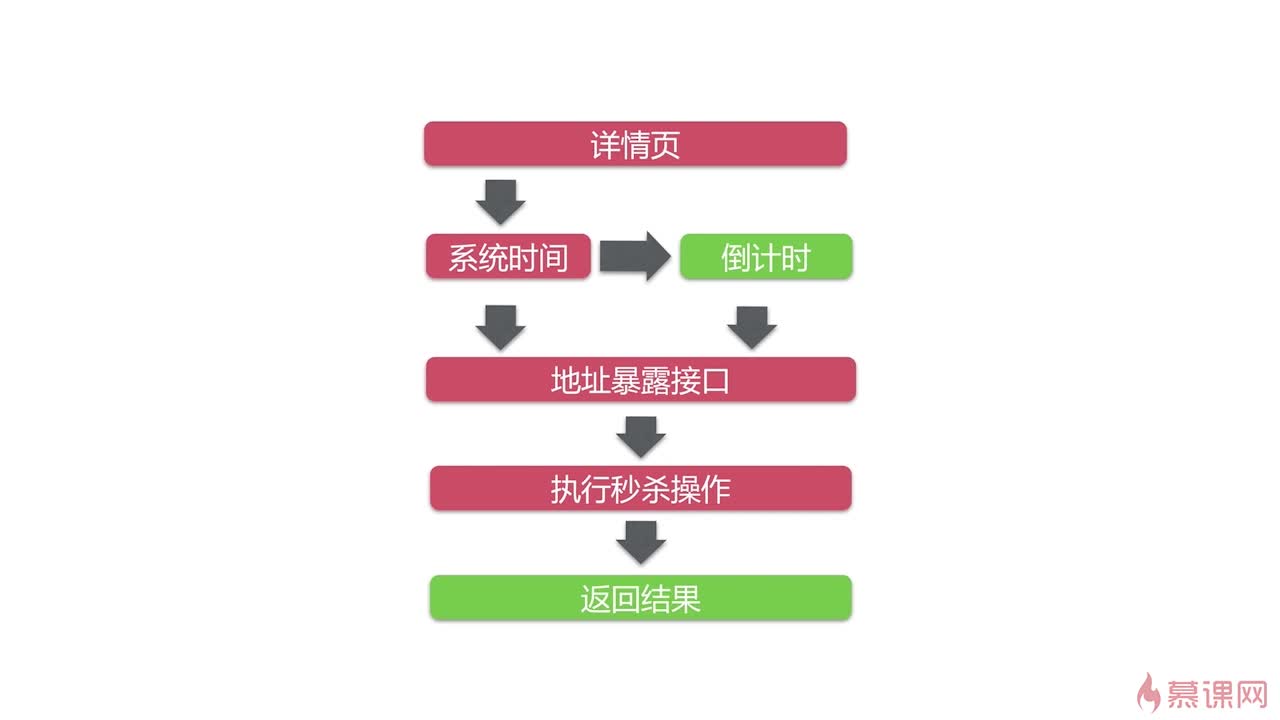
在上图中,红色的部分就表示会发生高并发的地方,绿色部分表示对于高并发没有影响。
为什么需要单独获取系统时间?
这是为了我们的秒杀系统的优化做铺垫。比如在秒杀还未开始的时候,用户大量刷新秒杀商品详情页面是很正常的情况,这时候秒杀还未开始,大量的请求发送到服务器会造成不必要的负担。
我们将这个详情页放置到CDN中,这样用户在访问该页面时就不需要访问我们的服务器了,起到了降低服务器压力的作用。而CDN中存储的是静态化的详情页和一些静态资源(css,js等),这样我们就拿不到系统的时间来进行秒杀时段的控制,所以我们需要单独设计一个请求来获取我们服务器的系统时间。
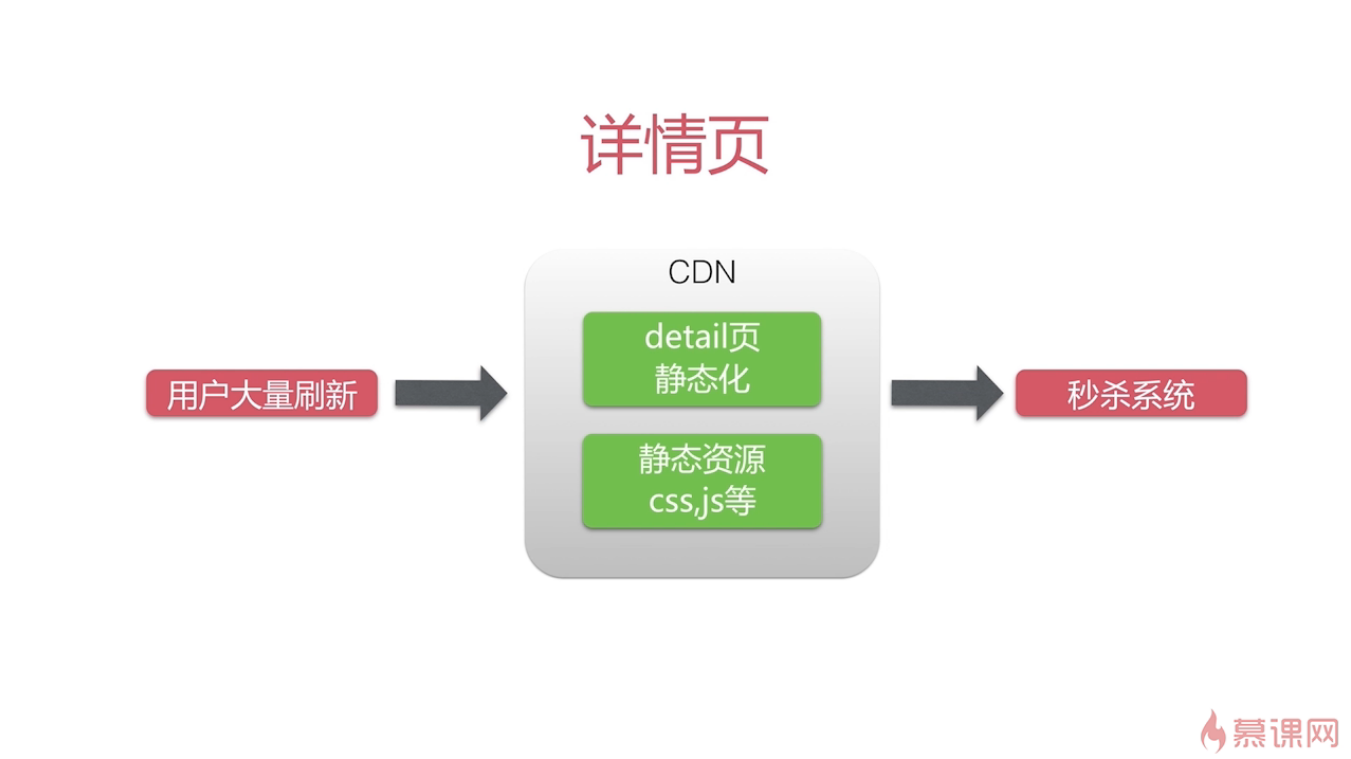
CDN(Content Delivery Network)的理解

获取系统时间不需要优化
因为Java访问一次内存(Cacheline)大约10ns,1s=10亿ns,也就是如果不考虑GC,这个操作1s可以做1亿次。
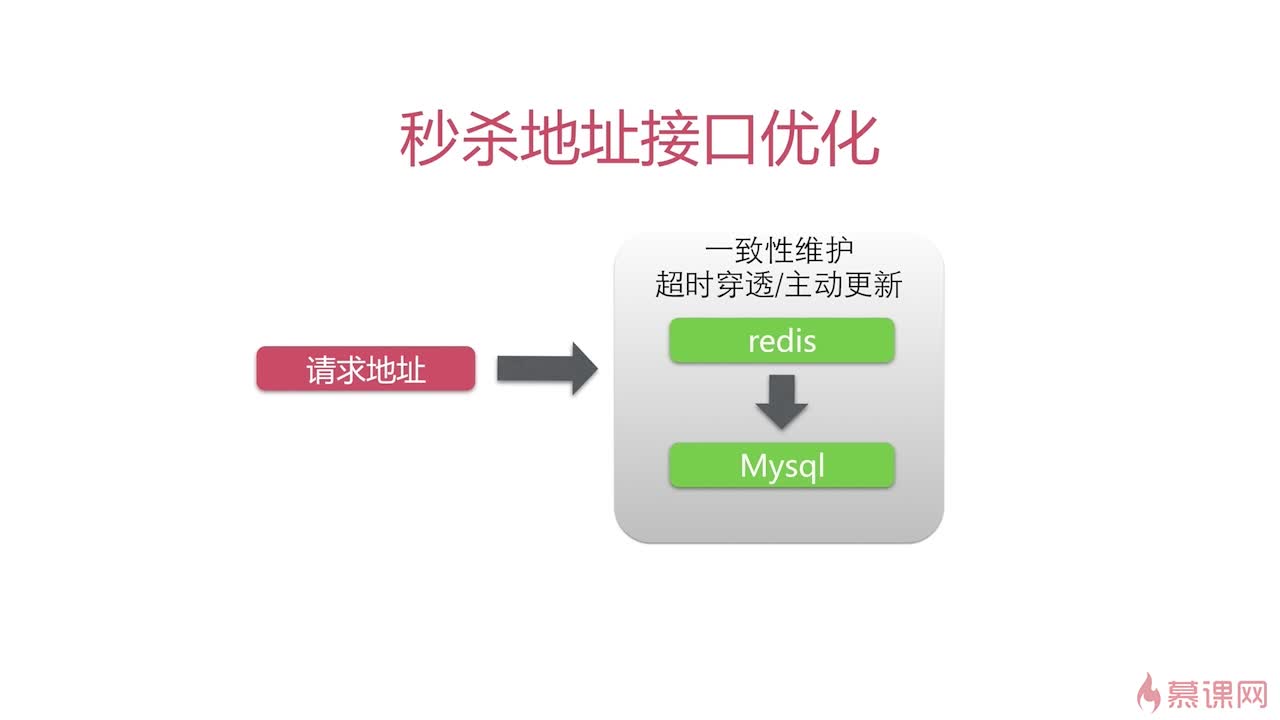
秒杀地址接口分析
- 无法使用CDN缓存,因为CDN适合请求对应的资源不变化的,比如静态资源、JavaScript;秒杀地址返回的数据是变化的,不适合放在CDN缓存;
- 适合服务端缓存:Redis等,1秒钟可以承受10万qps。多个Redis组成集群,可以到100w个qps. 所以后端缓存可以用业务系统控制。
秒杀地址接口优化
秒杀操作优化分析
- 无法使用cdn缓存
- 后端缓存困难: 库存问题
- 一行数据竞争:热点商品
大部分写的操作和核心操作无法使用CDN,也不可能在缓存中减库存。你在Redis中减库存,那么用户也可能通过缓存来减库存,这样库存会不一致,所以要通过mysql的事务来保证一致性。
比如一个热点商品所有人都在抢,那么会在同一时间对数据表中的一行数据进行大量的update set操作。
行级锁在commit之后才释放,所以优化方向是减少行级锁的持有时间。
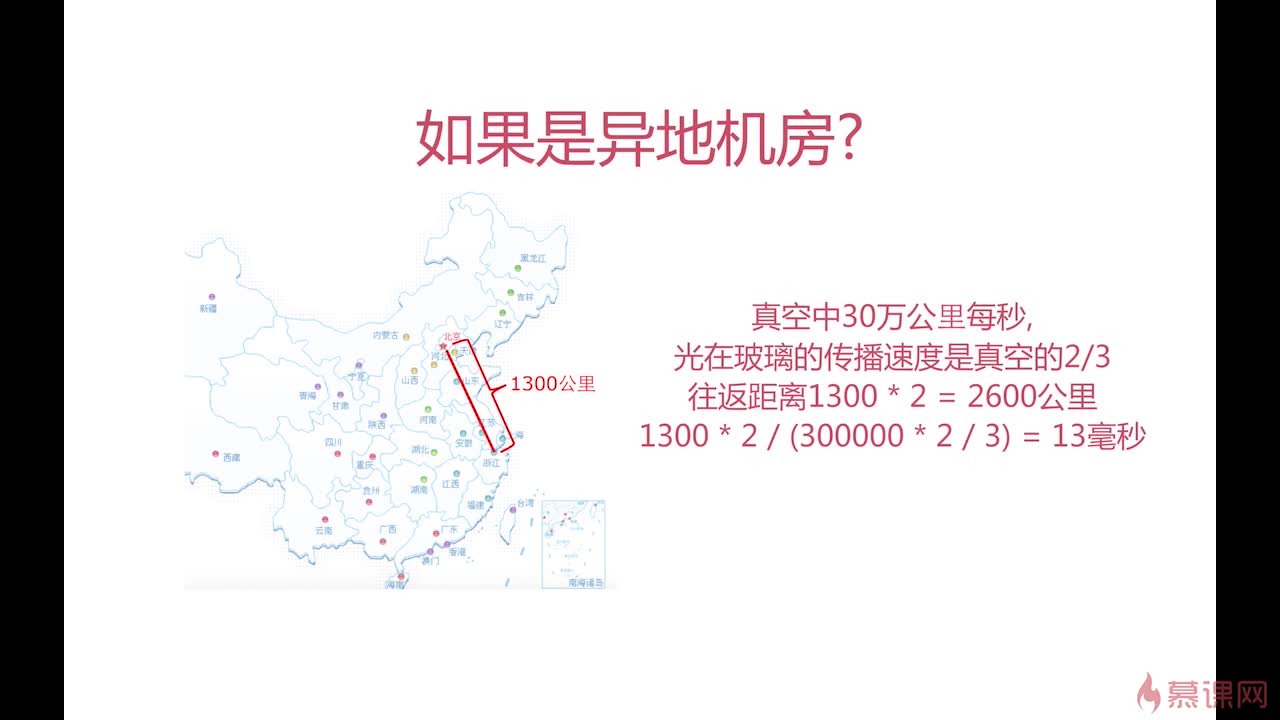
延迟问题很关键
- 同城机房网络(0.5ms~2ms),最高并发性是1000qps。
- Update后JVM -GC(垃圾回收机制)大约50ms,最高并发性是20qps。并发性越高,GC就越可能发生,虽然不一定每次都会发生,但一定会发生。
-
异地机房,比如北京到上海之间的网络延迟,进过计算大概13~20ms。
如何判断update更新库存成功?
有两个条件:
- update自身没报错;
- 客户端确认update影响记录数
优化思路:
- 把客户端逻辑放到MySQL服务端,避免网络延迟和GC影响
如何把客户端逻辑放到MySQL服务端
有两种方案:
- 定制SQL方案,在每次update后都会自动提交,但需要修改MySQL源码,成本很高,不是大公司(BAT等)一般不会使用这种方法。
- 使用存储过程:整个事务在MySQL端完成,用存储过程写业务逻辑,服务端负责调用。
接下来先分析第一种方案
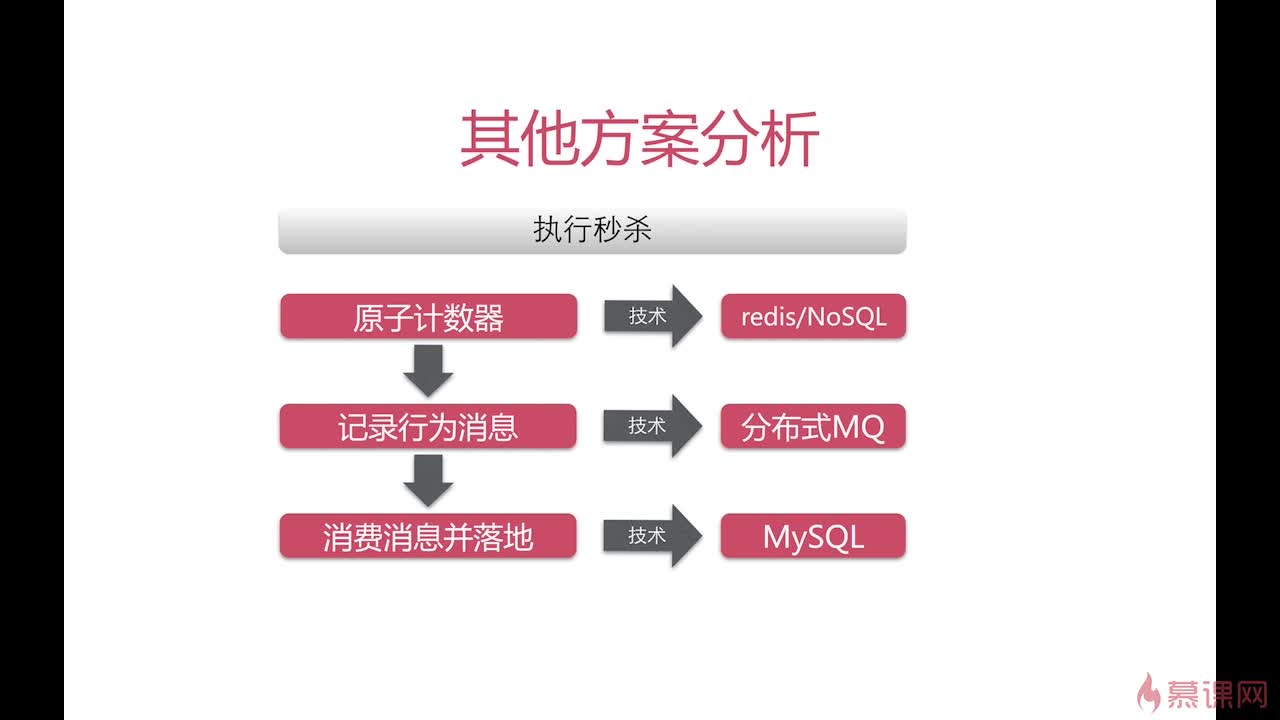

根据上图的成本分析,我们的秒杀系统采用第二种方案,即使用存储过程。
优化总结
- 前端控制
暴露接口,按钮防重复(点击一次按钮后就变成灰色,禁止重复点击按钮)
- 动静态数据分离
CDN缓存,后端缓存
- 事务竞争优化
减少事务行级锁的持有时间
2. Redis后端缓存优化编码
关于CDN的说明
由于不同公司提供的CDN的接口暴露不同,不同的公司租用的机房调用的API也不相同,所以慕课网的视频中并没有对CDN的使用过程进行讲解。
2.1 下载安装Redis
前往官网下载安装Stable版本的Redis,安装后可以将安装目录添加到系统变量Path里以方便使用,我使用的是Windows系统的Redis,懒得去官网下载的可以点这里下载。
安装后,运行redis-server.exe启动服务器成功,接着运行redis-cli.exe启动客户端连接服务器成功,说明Redis已经安装成功了。
为什么使用Redis
Redis属于NoSQL,即非关系型数据库,它是key-value型数据库,是直接在内存中进行存取数据的,所以有着很高的性能。
利用Redis可以减轻MySQL服务器的压力,减少了跟数据库服务器的通信次数。秒杀的瓶颈就在于跟数据库服务器的通信速度(MySQL本身的主键查询非常快)
2.2 在pom.xml中配置Redis客户端
<!--添加Redis依赖 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.3</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Jedis
Redis有很多客户端,我们的项目是用Java语言写的,自然选择对应Java语言的客户端,而官网最推荐我们的Java客户端是Jedis,在pom.xml里配置了Jedis依赖就可以使用它了,记得要先开启Redis的服务器,Jedis才能连接到服务器。
由于Jedis并没有实现内部序列化操作,而Java内置的序列化机制性能又不高,我们是一个秒杀系统,需要考虑高并发优化,在这里我们采用开源社区提供的更高性能的自定义序列化工具protostuff。
2.3 在pom.xml中配置protostuff依赖
<!--prostuff序列化依赖 -->
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.0.8</version>
</dependency>
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.0.8</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
关于序列化和反序列化
序列化是处理对象流的机制,就是将对象的内容进行流化,可以对流化后的对象进行读写操作,也可以将流化后的对象在网络间传输。反序列化就是将流化后的对象重新转化成原来的对象。
在Java中内置了序列化机制,通过implements Serializable来标识一个对象实现了序列化接口,不过其性能并不高。
2.4 使用Redis优化地址暴露接口
原本查询秒杀商品时是通过主键直接去数据库查询的,选择将数据缓存在Redis,在查询秒杀商品时先去Redis缓存中查询,以此降低数据库的压力。如果在缓存中查询不到数据再去数据库中查询,再将查询到的数据放入Redis缓存中,这样下次就可以直接去缓存中直接查询到。
以上属于数据访问层的逻辑(DAO层),所以我们需要在dao包下新建一个cache目录,在该目录下新建RedisDao.java,用来存取缓存。
RedisDao
public class RedisDao {
private final JedisPool jedisPool;
public RedisDao(String ip, int port) {
jedisPool = new JedisPool(ip, port);
}
private RuntimeSchema<Seckill> schema = RuntimeSchema.createFrom(Seckill.class);
public Seckill getSeckill(long seckillId) {
// redis操作逻辑
try {
Jedis jedis = jedisPool.getResource();
try {
String key = "seckill:" + seckillId;
// 并没有实现哪部序列化操作
// 采用自定义序列化
// protostuff: pojo.
byte[] bytes = jedis.get(key.getBytes());
// 缓存重获取到
if (bytes != null) {
Seckill seckill = schema.newMessage();
ProtostuffIOUtil.mergeFrom(bytes, seckill, schema);
// seckill被反序列化
return seckill;
}
} finally {
jedis.close();
}
} catch (Exception e) {
}
return null;
}
public String putSeckill(Seckill seckill) {
try {
Jedis jedis = jedisPool.getResource();
try {
String key = "seckill:" + seckill.getSeckillId();
byte[] bytes = ProtostuffIOUtil.toByteArray(seckill, schema,
LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE));
// 超时缓存
int timeout = 60 * 60;// 1小时
String result = jedis.setex(key.getBytes(), timeout, bytes);
return result;
} finally {
jedis.close();
}
} catch (Exception e) {
}
return null;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
注意
使用protostuff序列化工具时,被序列化的对象必须是pojo对象(具备setter/getter)
在spring-dao.xml中手动注入RedisDao
由于RedisDao和MyBatis的DAO没有关系,MyBatis不会帮我们自动实现该接口,所以我们需要在spring-dao.xml中手动注入RedisDao。由于我们在RedisDao是通过构造方法来注入ip和port两个参数的,所以需要配置,如果不配置这个标签,我们需要为ip和port提供各自的setter和getter(注入时可以没有getter)。
在这里我们直接把value的值写死在标签里边了,实际开发中需要把ip和port参数的值写到配置文件里,通过读取配置文件的方式读取它们的值。
<!--redisDao -->
<bean id="redisDao" class="com.lewis.dao.cache.RedisDao">
<constructor-arg index="0" value="localhost" />
<constructor-arg index="1" value="6379" />
</bean>
- 1
- 2
- 3
- 4
- 5
- 6
修改SeckillServiceImpl
使用注解注入RedisDao属性
@Autowired
private RedisDao redisDao;
- 1
- 2
- 3
修改exportSeckillURI()
public Exposer exportSeckillUrl(long seckillId) {
// 优化点:缓存优化:超时的基础上维护一致性
// 1.访问redis
Seckill seckill = redisDao.getSeckill(seckillId);
if (seckill == null) {
// 2.访问数据库
seckill = seckillDao.queryById(seckillId);
if (seckill == null) {// 说明查不到这个秒杀产品的记录
return new Exposer(false, seckillId);
} else {
// 3.放入redis
redisDao.putSeckill(seckill);
}
}
// 若是秒杀未开启
Date startTime = seckill.getStartTime();
Date endTime = seckill.getEndTime();
// 系统当前时间
Date nowTime = new Date();
if (startTime.getTime() > nowTime.getTime() || endTime.getTime() < nowTime.getTime()) {
return new Exposer(false, seckillId, nowTime.getTime(), startTime.getTime(), endTime.getTime());
}
// 秒杀开启,返回秒杀商品的id、用给接口加密的md5
String md5 = getMD5(seckillId);
return new Exposer(true, md5, seckillId);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2.5 测试类RedisDaoTest
通过IDE工具快速生成测试类RedisDaoTest,新写一个testSeckill(),对getSeckill和putSeckill方法进行全局测试。
@RunWith(SpringJUnit4ClassRunner.class)
// 告诉junit spring的配置文件
@ContextConfiguration({ "classpath:spring/spring-dao.xml" })
public class RedisDaoTest {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
private long id = 1001;
@Autowired
private RedisDao redisDao;
@Autowired
private SeckillDao seckillDao;
@Test
public void testSeckill() {
Seckill seckill = redisDao.getSeckill(id);
if (seckill == null) {
seckill = seckillDao.queryById(id);
if (seckill != null) {
String result = redisDao.putSeckill(seckill);
logger.info("result={}", result);
seckill = redisDao.getSeckill(id);
logger.info("seckill={}", seckill);
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
如果测试通过了,会输出result={}OK以及id为1001的商品信息,如果输出的都是null,那说明你没有开启Redis服务器,所以在内存中没有存取到缓存。
为什么不用Redis的hash来存储对象?
第一:通过Jedis储存对象的方式有大概三种
- 本项目采用的方式:将对象序列化成byte字节,最终存byte字节;
- 对象转hashmap,也就是你想表达的hash的形式,最终存map;
- 对象转json,最终存json,其实也就是字符串
第二:其实如果你是平常的项目,并发不高,三个选择都可以,这种情况下以hash的形式更加灵活,可以对象的单个属性,但是问题来了,在秒杀的场景下,三者的效率差别很大。
第三:结果如下
| 10w数据 | 时间 | 内存占用 |
|---|---|---|
| 存json | 10s | 14M |
| 存byte | 6s | 6M |
| 存jsonMap | 10s | 20M |
| 存byteMap | 4s | 4M |
| 取json | 7s | |
| 取byte | 4s | |
| 取jsonmap | 7s | |
| 取bytemap | 4s |
第四:你该说了,bytemap最快啊,为啥不用啊,因为项目用了超级强悍的序列化工具啊,以上测试是基于java的序列化,如果改了序列化工具,你可以测试下。
以上问答源自慕课网的一道问答
教学视频中张老师对于Redis暴露接口地址的补充
- redis事务与RDBMS事务有本质区别,详情见http://redis.io/topics/transactions
- 关于spring整合redis。原生Jedis API已经足够清晰。笔者所在的团队不使用任何spring-data整合API,而是直接对接原生Client并做二次开发调优,如Jedis,Hbase等。
- 这里使用redis缓存方法用于暴露秒杀地址场景,该方法存在瞬时压力,为了降低DB的primary key QPS,且没有使用库存字段所以不做一致性维护。
- 跨数据源的严格一致性需要2PC支持,性能不尽如人意。线上产品一般使用最终一致性去解决,这块相关知识较多,所以没有讲。
- 本课程的重点其实不是SSM,只是一个快速开发的方式。重点根据业务场景分析通信成本,瓶颈点的过程和优化思路。
- 初学者不要纠结于事务。事务可以降低一致性维护难度,但扩展性灵活性存在不足。技术是死的,人是活的。比如京东抢购使用Redis+LUA+MQ方案,就是一种技术反思。
3. 秒杀操作——并发优化
3.1 简单优化
回顾事务执行

sql语句的简单优化
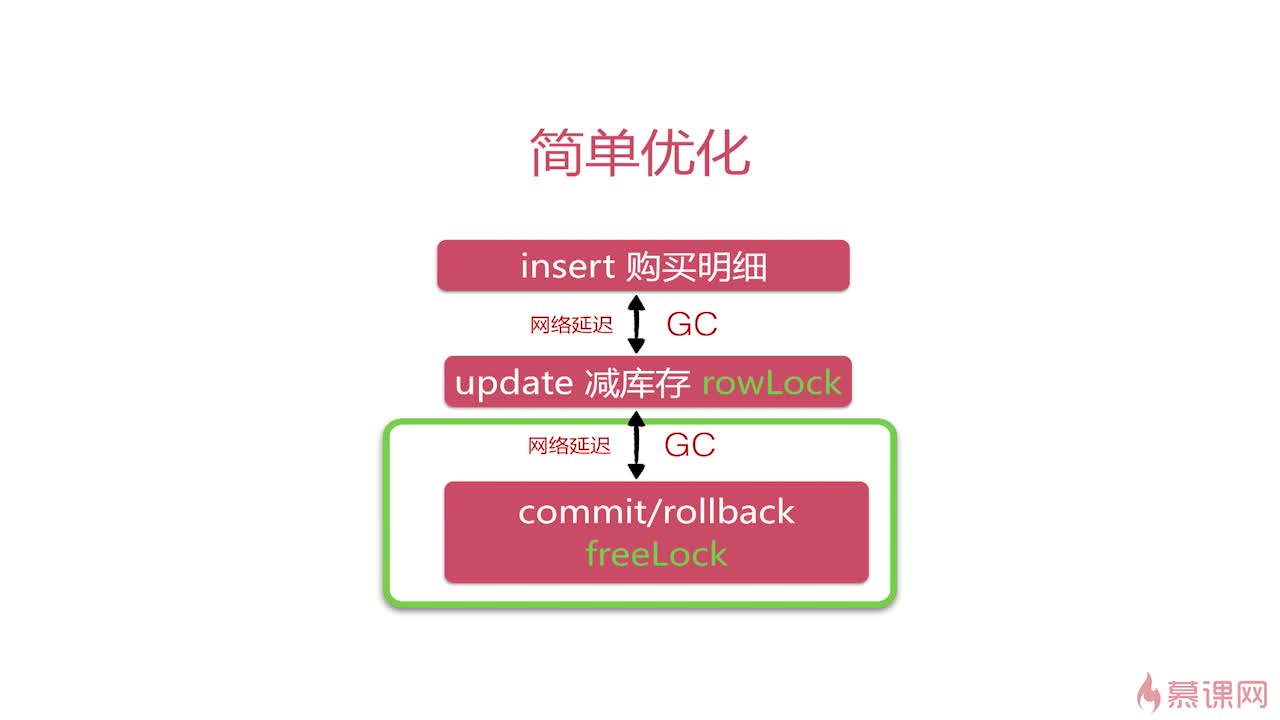
优化SeckillServiceImpl的
executeSeckill()
用户的秒杀操作分为两步:减库存、插入购买明细,我们在这里进行简单的优化,就是将原本先update(减库存)再进行insert(插入购买明细)的步骤改成:先insert再update。
public SeckillExecution executeSeckill(long seckillId, long userPhone, String md5) throws SeckillException,
RepeatKillException, SeckillCloseException {
if (md5 == null || !md5.equals(getMD5(seckillId))) {
throw new SeckillException("seckill data rewrite");// 秒杀数据被重写了
}
// 执行秒杀逻辑:减库存+增加购买明细
Date nowTime = new Date();
try {
// 否则更新了库存,秒杀成功,增加明细
int insertCount = successKilledDao.insertSuccessKilled(seckillId, userPhone);
// 看是否该明细被重复插入,即用户是否重复秒杀
if (insertCount <= 0) {
throw new RepeatKillException("seckill repeated");
} else {
// 减库存,热点商品竞争
int updateCount = seckillDao.reduceNumber(seckillId, nowTime);
if (updateCount <= 0) {
// 没有更新库存记录,说明秒杀结束 rollback
throw new SeckillCloseException("seckill is closed");
} else {
// 秒杀成功,得到成功插入的明细记录,并返回成功秒杀的信息 commit
SuccessKilled successKilled = successKilledDao.queryByIdWithSeckill(seckillId, userPhone);
return new SeckillExecution(seckillId, SeckillStatEnum.SUCCESS, successKilled);
}
}
} catch (SeckillCloseException e1) {
throw e1;
} catch (RepeatKillException e2) {
throw e2;
} catch (Exception e) {
logger.error(e.getMessage(), e);
// 将编译期异常转化为运行期异常
throw new SeckillException("seckill inner error :" + e.getMessage());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
为什么要先insert再update
首先是在更新操作的时候给行加锁,插入并不会加锁,如果更新操作在前,那么就需要执行完更新和插入以后事务提交或回滚才释放锁。而如果插入在前,更新在后,那么只有在更新时才会加行锁,之后在更新完以后事务提交或回滚释放锁。
在这里,插入是可以并行的,而更新由于会加行级锁是串行的。
也就是说是更新在前加锁和释放锁之间两次的网络延迟和GC,如果插入在前则加锁和释放锁之间只有一次的网络延迟和GC,也就是减少的持有锁的时间。
这里先insert并不是忽略了库存不足的情况,而是因为insert和update是在同一个事务里,光是insert并不一定会提交,只有在update成功才会提交,所以并不会造成过量插入秒杀成功记录。
3.2 深度优化
前边通过调整insert和update的执行顺序来实现简单优化,但依然存在着Java客户端和服务器通信时的网络延迟和GC影响,我们可以将执行秒杀操作时的insert和update放到MySQL服务端的存储过程里,而Java客户端直接调用这个存储过程,这样就可以避免网络延迟和可能发生的GC影响。另外,由于我们使用了存储过程,也就使用不到Spring的事务管理了,因为在存储过程里我们会直接启用一个事务。
3.2.1 写一个存储过程procedure,然后在MySQL控制台里执行它
-- 秒杀执行储存过程
DELIMITER $$ -- 将定界符从;转换为$$
-- 定义储存过程
-- 参数: in输入参数 out输出参数
-- row_count() 返回上一条修改类型sql(delete,insert,update)的影响行数
-- row_count:0:未修改数据 ; >0:表示修改的行数; <0:sql错误
CREATE PROCEDURE `seckill`.`execute_seckill`
(IN v_seckill_id BIGINT, IN v_phone BIGINT,
IN v_kill_time TIMESTAMP, OUT r_result INT)
BEGIN
DECLARE insert_count INT DEFAULT 0;
START TRANSACTION;
INSERT IGNORE INTO success_killed
(seckill_id, user_phone, state)
VALUES (v_seckill_id, v_phone, 0);
SELECT row_count() INTO insert_count;
IF (insert_count = 0) THEN
ROLLBACK;
SET r_result = -1;
ELSEIF (insert_count < 0) THEN
ROLLBACK;
SET r_result = -2;
ELSE
UPDATE seckill
SET number = number - 1
WHERE seckill_id = v_seckill_id
AND end_time > v_kill_time
AND start_time < v_kill_time
AND number > 0;
SELECT row_count() INTO insert_count;
IF (insert_count = 0) THEN
ROLLBACK;
SET r_result = 0;
ELSEIF (insert_count < 0) THEN
ROLLBACK;
SET r_result = -2;
ELSE
COMMIT;
SET r_result = 1;
END IF;
END IF;
END;
$$
-- 储存过程定义结束
-- 将定界符重新改为;
DELIMITER ;
-- 定义一个用户变量r_result
SET @r_result = -3;
-- 执行储存过程
CALL execute_seckill(1003, 13502178891, now(), @r_result);
-- 获取结果
SELECT @r_result;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
注意点
CREATE PROCEDURE `seckill`.`execute_seckill`
- 1
- 2
上边这句语句的意思是为一个名为seckill的数据库定义一个名为execute_seckill的存储过程,如果你在连接数据库后使用了这个数据库(即use seckill;),那么这里的定义句子就不能这样写了,会报错(因为存储过程是依赖于数据库的),改成下边这样:
CREATE PROCEDURE `execute_seckill`
- 1
- 2
row_count()
存储过程中,row_count()函数用来返回上一条sql(delete,insert,update)影响的行数。
根据row_count()返回值,可以进行接下来的流程判断:
0:未修改数据;
>0: 表示修改的行数;
<0: 表示SQL错误或未执行修改SQL
3.2.2 修改源码以调用存储过程
在
SeckillDao里添加调用存储过程的方法声明
/**
* 使用储存过程执行秒杀
* @param paramMap
*/
void killByProcedure(Map<String,Object> paramMap);
- 1
- 2
- 3
- 4
- 5
- 6
接着在
SeckillDao.xml里添加该方法对应的sql语句
<!--调用储存过程 -->
<select id="killByProcedure" statementType="CALLABLE">
CALL execute_seckill(
#{seckillId,jdbcType=BIGINT,mode=IN},
#{phone,jdbcType=BIGINT,mode=IN},
#{killTime,jdbcType=TIMESTAMP,mode=IN},
#{result,jdbcType=INTEGER,mode=OUT}
)
</select>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在
SeckillService接口里添加一个方法声明
/**
* 调用存储过程来执行秒杀操作,不需要抛出异常
*
* @param seckillId 秒杀的商品ID
* @param userPhone 手机号码
* @param md5 md5加密值
* @return 根据不同的结果返回不同的实体信息
*/
SeckillExecution executeSeckillProcedure(long seckillId,long userPhone,String md5);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
为什么这个方法不需要抛出异常?
原本没有调用存储过程的执行秒杀操作之所以要抛出RuntimException,是为了让Spring事务管理器能够在秒杀不成功的时候进行回滚操作。而现在我们使用了存储过程,有关事务的提交或回滚已经在procedure里完成了,前面也解释了不需要再使用到Spring的事务了,既然如此,我们也就不需要在这个方法里抛出异常来让Spring帮我们回滚了。
在
SeckillServiceImpl里实现这个方法
我们需要使用到第三方工具类,所以在pom.xml里导入commons-collections工具类
<!--导入apache工具类-->
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.2</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在接口的实现类里对executeSeckillProcedure进行实现
@Override
public SeckillExecution executeSeckillProcedure(long seckillId, long userPhone, String md5) {
if (md5 == null || !md5.equals(getMD5(seckillId))) {
return new SeckillExecution(seckillId, SeckillStatEnum.DATE_REWRITE);
}
Date killTime = new Date();
Map<String, Object> map = new HashMap<>();
map.put("seckillId", seckillId);
map.put("phone", userPhone);
map.put("killTime", killTime);
map.put("result", null);
// 执行储存过程,result被复制
seckillDao.killByProcedure(map);
// 获取result
int result = MapUtils.getInteger(map, "result", -2);
if (result == 1) {
SuccessKilled successKilled = successKilledDao.queryByIdWithSeckill(seckillId, userPhone);
return new SeckillExecution(seckillId, SeckillStatEnum.SUCCESS, successKilled);
} else {
return new SeckillExecution(seckillId, SeckillStatEnum.stateOf(result));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
接着对该方法进行测试,在原本的SeckillServiceTest测试类里添加测试方法
@Test
public void executeSeckillProcedure(){
long seckillId = 1001;
long phone = 13680115101L;
Exposer exposer = seckillService.exportSeckillUrl(seckillId);
if (exposer.isExposed()) {
String md5 = exposer.getMd5();
SeckillExecution execution = seckillService.executeSeckillProcedure(seckillId, phone, md5);
logger.info("execution={}", execution);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
经过测试,发现没有问题,测试通过。然后我们需要把Controller里的执行秒杀操作改成调用存储过程的方法。
@RequestMapping(value = "/{seckillId}/{md5}/execution",
method = RequestMethod.POST,
produces = {"application/json;charset=UTF-8"})
@ResponseBody
public SeckillResult<SeckillExecution> execute(@PathVariable("seckillId") Long seckillId,
@PathVariable("md5") String md5,
@CookieValue(value = "userPhone",required = false) Long userPhone)
{
if (userPhone==null)
{
return new SeckillResult<SeckillExecution>(false,"未注册");
}
try {
//这里改为调用存储过程
// SeckillExecution execution = seckillService.executeSeckill(seckillId, userPhone, md5);
SeckillExecution execution = seckillService.executeSeckillProcedure(seckillId, userPhone, md5);
return new SeckillResult<SeckillExecution>(true, execution);
}catch (RepeatKillException e1)
{
SeckillExecution execution=new SeckillExecution(seckillId, SeckillStatEnum.REPEAT_KILL);
return new SeckillResult<SeckillExecution>(true,execution);
}catch (SeckillCloseException e2)
{
SeckillExecution execution=new SeckillExecution(seckillId, SeckillStatEnum.END);
return new SeckillResult<SeckillExecution>(true,execution);
}
catch (Exception e)
{
SeckillExecution execution=new SeckillExecution(seckillId, SeckillStatEnum.INNER_ERROR);
return new SeckillResult<SeckillExecution>(true,execution);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
存储过程优化总结
- 存储过程优化:事务行级锁持有的时间
- 不要过度依赖存储过程
- 简单的逻辑依赖存储过程
- QPS:一个秒杀单6000/qps
经过简单优化和深度优化之后,本项目大概能达到一个秒杀单6000qps(慕课网视频中张老师说的),这个数据对于一个秒杀商品来说其实已经挺ok了,注意这里是指同一个秒杀商品6000qps,如果是不同商品不存在行级锁竞争的问题。
3.3 系统部署架构

CDN:放置一些静态化资源,或者可以将动态数据分离。一些js依赖直接用公网的CDN,自己开发的一些页面也做静态化处理推送到CDN。用户在CDN获取到的数据不需要再访问我们的服务器,动静态分离可以降低服务器请求量。比如秒杀详情页,做成HTML放在cdn上,动态数据可以通过ajax请求后台获取。
Nginx:作为http服务器,响应客户请求,为后端的servlet容器做反向代理,以达到负载均衡的效果。
Redis:用来做服务器端的缓存,通过Jedis提供的API来达到热点数据的一个快速存取的过程,减少数据库的请求量。
MySQL:保证秒杀过程的数据一致性与完整性。
智能DNS解析+智能CDN加速+Nginx并发+Redis缓存+MySQL分库分表
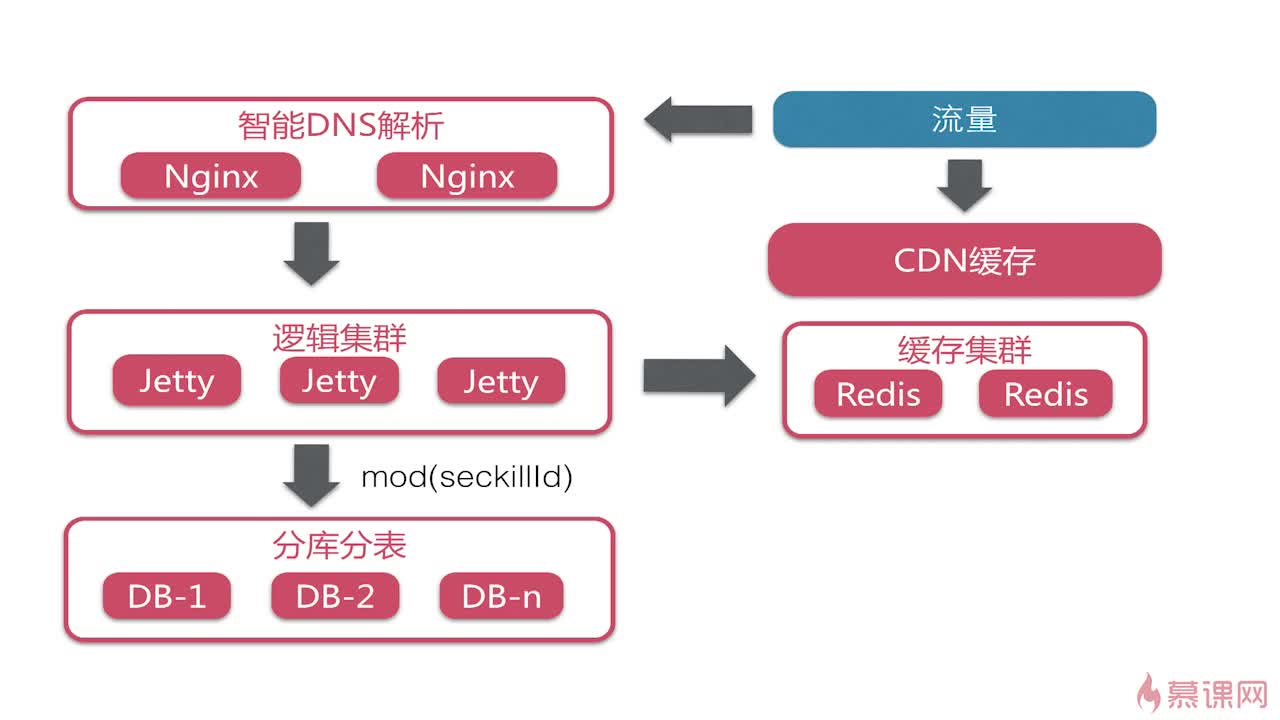
大型系统部署架构,逻辑集群就是开发的部分。
- Nginx做负载均衡
- 分库分表:在秒杀系统中,一般通过关键的秒杀商品id取模进行分库分表,以512为一张表,1024为一张表。分库分表一般采用开源架构,如阿里巴巴的tddl分库分表框架。
- 统计分析:一般使用hadoop等架构进行分析
在这样一个架构中,可能参与的角色如下:

本节结语
至此,关于该SSM实战项目——Java高并发秒杀API已经全部完成,感谢观看本文。
项目笔记相关链接
项目源码
项目视频教程链接
这是慕课网上的一个免费项目教学视频,名为Java高并发秒杀API,一共有如下四节课程,附带视频传送门(在视频中老师是用IDEA,本文用的是Eclipse)
高并发的相关推荐















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









