







一、优化前:
shuffle写的比例为输入数据的1.5倍:

二、优化后:

三、RDD压缩
spark.shuffle.compress
序列化后,shuffle write仍然较大,考虑压缩
sparkConf.set("spark.rdd.compress", "true")
四、序列化优化
4-1、kyro注册
sparkConf.registerKryoClasses(Array(classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],classOf[org.apache.hadoop.hbase.client.Put],classOf[org.apache.hadoop.hbase.client.Result]))
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
import java.io.*;
public class HelloKryo {
static public void main (String[] args) throws Exception {
Kryo kryo = new Kryo();
kryo.register(SomeClass.class);
SomeClass object = new SomeClass();
object.value = "Hello Kryo!";
Output output = new Output(new FileOutputStream("file.bin"));
kryo.writeObject(output, object);
output.close();
Input input = new Input(new FileInputStream("file.bin"));
SomeClass object2 = kryo.readObject(input, SomeClass.class);
input.close();
}
static public class SomeClass {
String value;
}
}
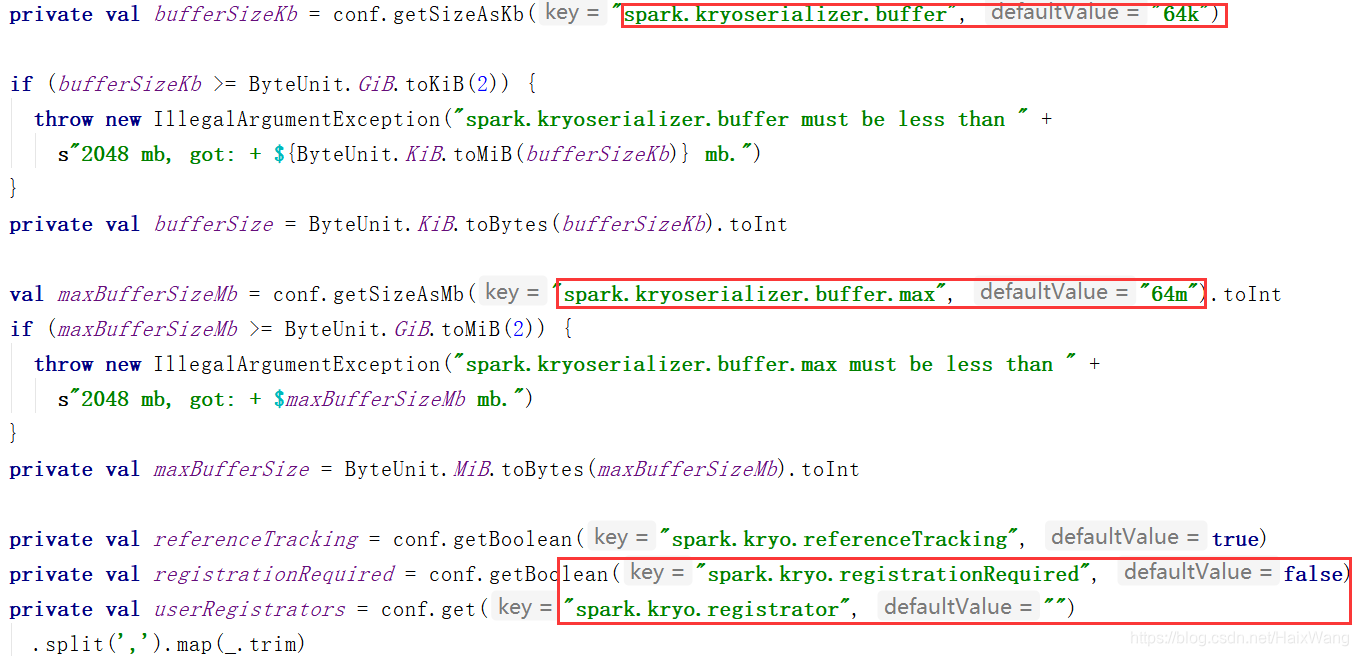
4-2、序列化缓存
源码如下:














 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









