







在深度网络中,卷积计算应用非常广泛。在图像处理中,卷积计算也就是图像像素矩阵与卷积核之间的点对点相乘在累加的运算,但是在不同的深度学习框架或者平台中,卷积实现的方式有一定的差异,所以我参考一些博客并根据个人的理解整理了Caffe,Tensorflow及Matlab中的卷积实现。
首先,三者对于图像卷积的基本原理是相同的,不同的只是在矩阵变换的实现上,先回顾下卷积前后图像矩阵大小的变化。
以二维图像矩阵为例,假设有:
height简称h,width简称w- 输入图像矩阵
input_feature: (inputh,inputw) ( i n p u t h , i n p u t w ) - 输出图像矩阵
output_feature: (outputh,outputw) ( o u t p u t h , o u t p u t w ) - 卷积核
filter: (filterh,filterw) ( f i l t e r h , f i l t e r w ) - 滑动步长
strides: (sh,sw) ( s h , s w ) padding的长度: (ph,pw) ( p h , p w )
则一般情况下,卷积后的图像矩阵output_feature大小为:
Caffe的卷积实现
由于之前整理过,可直接跳转至博客caffe学习:卷积计算
这篇侧重在原理的解释上,源码解析没贴,后面会更新。
Tensorflow的卷积实现
tf.nn.conv2d是TensorFlow里面实现卷积的函数,函数用法:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
# 结果返回一个Tensor,这个输出就是我们常说的feature map参数Input:卷积的输入图像,要求是一个4维的Tensor,其大小[batch, in_height, in_width, in_channel],分别代表输入图片的数量,图片的高度,图片的宽度,图片的通道数,这个Tensor的类型是float32或者float64
参数filter:相当于CNN中的卷积核,它要求是一个4维的Tensor,其大小[filter_height, filter_width, in_channels, out_channels],分别代表[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
参数strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
参数padding:string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同的卷积方式(后面会介绍)
参数name:用以指定该操作的name,即该操作的别称
那么TensorFlow的卷积具体是怎样实现的呢,用一些例子去解释它:
1.考虑一种最简单的情况,现在有一张3×3单通道的图像(对应的shape:[1,3,3,1]),用一个1×1的卷积核(对应的shape:[1,1,1,1])去做卷积,最后会得到一张3×3的feature map
2.增加图片的通道数,使用一张3×3五通道的图像(对应的shape:[1,3,3,5]),用一个1×1的卷积核(对应的shape:[1,1,5,1])去做卷积,仍然是一张3×3的feature map,这就相当于每一个像素点,卷积核都与该像素点的每一个通道做点积
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([1,1,5,1]))
op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')3.把卷积核扩大,现在用3×3的卷积核做卷积,最后的输出是一个值,相当于情况2的feature map所有像素点的值求和
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')4.使用更大的图片将情况2的图片扩大到5×5,仍然是3×3的卷积核,令步长为1,输出3×3的feature map
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')注意我们可以把这种情况看成情况2和情况3的中间状态,在左侧图中卷积核在中间9格中从左往右,从上往下以步长1滑动遍历,在这些停留的位置上,每停留一个,输出feature map的一个像素
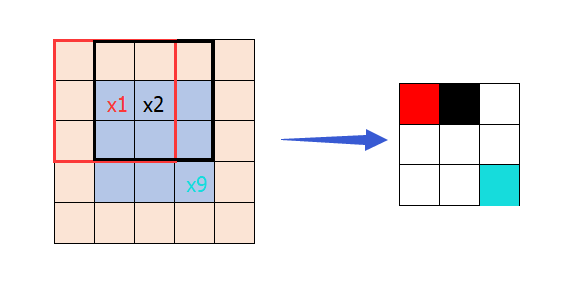
5.以上参数padding的值为‘VALID’,当其为‘SAME’时,表示卷积核可以停留在图像边缘,如下,输出5×5的feature map
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')
此种方式里,中间蓝色部分是图像本身,外围灰色是padding的部分,至于会填充多少要根据strides,卷积核尺寸及图像尺寸共同决定,最后满足的要求是输出的feature map大小与输入图像大小一致。
我们希望了解卷积中是如何实现两种padding方式,因此详细说明一下:
假设有, h代表height,w代表width
输入Input大小:
(inputh,inputw)
(
i
n
p
u
t
h
,
i
n
p
u
t
w
)
卷积核filter大小:
(Fh,Fw)
(
F
h
,
F
w
)
滑动步长strides:
(Sh,Sw)
(
S
h
,
S
w
)
输出output大小:
(opth,optw)
(
o
p
t
h
,
o
p
t
w
)
padding大小:
(Ph,Pw)
(
P
h
,
P
w
)
padding='VALID'时
卷积核不会超过图像边缘,也就是说不会在原有输入的基础上添加新的元素,输出矩阵的大小:
这个计算方式与上面提到的公式一致,其中 ⌈x⌉ ⌈ x ⌉ 表示对 x x 向上取整。
padding='SAME'时
此时的output feafure大小只与输入和步长有关:
在卷积的内部操作中,首先要根据strides,filter,input和output尺寸计算出padding的大小:
高度height上需要pad的总数目是
那么,在图像矩阵上方添加的pad数 Ptoph P t o p h 由height上的总数 Ph P h 求得
在图像矩阵下方添加的pad数 Pbuttomh P b u t t o m h 由height上的总数 Ph P h 和 Ptoph P t o p h 求得
其中 [x] [ x ] 表示一个小于或等于 x x 的最大整数
同理,宽度上需要pad的总数目是
然后,在图像矩阵左边添加的pad数
在图像右边添加的pad数
其中 [x] [ x ] 表示一个小于或等于 x x 的最大整数
以上即是padding的内部计算。我们继续分析更加复杂的情况
6.如果卷积核有多个
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')
#此时输出7张5×5的feature map7.步长不为1的情况,文档里说了对于图片,因为只有两维,通常strides取[1,stride,stride,1]
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME')
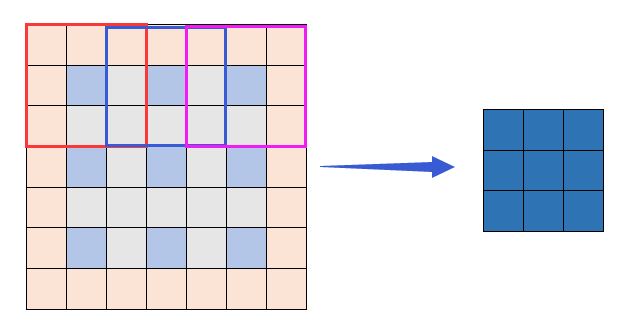
#此时,输出7张3×3的feature map此时,由上节公式计算出需要在图像矩阵的上下左右个填充一行或一列,如下图
8.如果batch值不为1,同时输入10张图
input = tf.Variable(tf.random_normal([10,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME')
#每张图,都有7张3×3的feature map,输出的shape就是[10,3,3,7]以上程序
#!/usr/bin/env python
# coding=utf-8
import tensorflow as tf
#case 2
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([1,1,5,1]))
op2 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')
#case 3
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op3 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')
#case 4
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op4 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')
#case 5
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op5 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')
#case 6
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op6 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')
#case 7
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op7 = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME')
#case 8
input = tf.Variable(tf.random_normal([10,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op8 = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME')
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
print("case 2")
print(sess.run(op2)).shape
print("case 3")
print(sess.run(op3)).shape
print("case 4")
print(sess.run(op4)).shape
print("case 5")
print(sess.run(op5)).shape
print("case 6")
print(sess.run(op6)).shape
print("case 7")
print(sess.run(op7)).shape
print("case 8")
print(sess.run(op8)).shape
#输出各种情况下的shape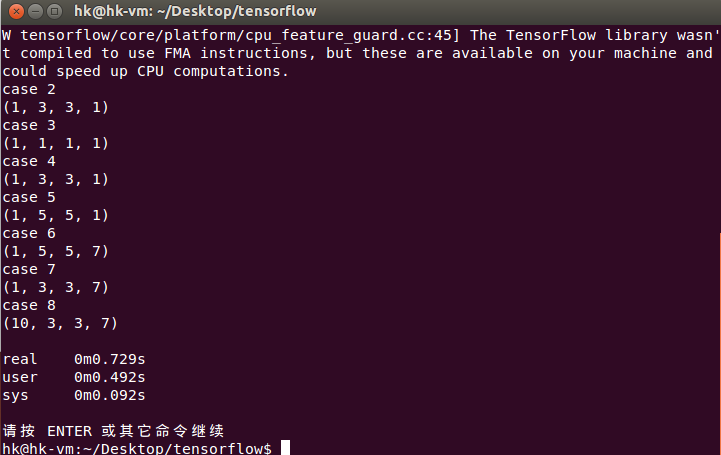
Matlab中的卷积
matlab中与卷积相关的函数有conv2函数,filter2函数,imfilter函数,以下分别来看
conv2函数
用法
C=conv2(A,B,shape); %卷积滤波A:输入图像,B:卷积核。假设输入图像A大小为ma x na,卷积核B大小为mb x nb,则
当shape=full时,返回全部二维卷积结果,即返回C的大小为(ma+mb-1)x(na+nb-1)
当shape=same时,返回与A同样大小的卷积中心部分
当shape=valid时,不考虑边界补零,即只要有边界补出的零参与运算的都舍去,返回C的大小为(ma-mb+1)x(na-nb+1)
实现步骤
假设输入图像A大小为ma x na,卷积核大小为mb x nb,则MATLAB的conv2函数实现流程如下:
a、对输入图像补零,第一行之前和最后一行之后都补mb-1行,第一列之前和最后一列之后都补nb-1列(注意conv2不支持其他的边界补充选项,函数内部对输入总是补零)。
b、关于卷积核的中心,旋转卷积核180度。
c、滑动卷积核,将卷积核的中心位于图像矩阵的每一个元素。
d、将旋转后的卷积核乘以对应的矩阵元素再求和。
实现过程展示
假设有图像
卷积核
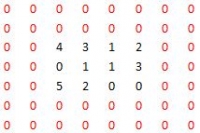
a、首先是按照上面的步骤进行补零,如下图外圈红色的为补出的零
b、将卷积核旋转180度

c、将旋转后的核在A上进行滑动,然后对应位置相乘,最后相加,下面分别是shape=full, same, valid时取输出图像大小的情况,位置1表示输出图像的值从当前核的计算值开始(对应输出图像左上角),位置2表示到该位置结束(对应输出图像右下)
滑动位置演示:
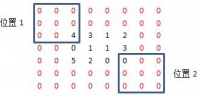
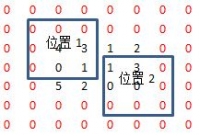
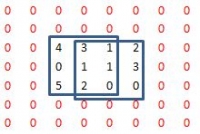
运行结果:
filter2函数
用法
B = filter2(h,A,shape) ; %相关(correlation)滤波A:输入图像,h:相关核。假设输入图像A大小为ma x na,相关核h大小为mb x nb,则
当shape=full时,返回全部二维卷积结果,即返回B的大小为(ma+mb-1)x(na+nb-1)
当shape=same时,返回与A同样大小的卷积中心部分
当shape=valid时,不考虑边界补零,即只要有边界补出的零参与运算的都舍去,返回B的大小为(ma-mb+1)x(na-nb+1)
实现步骤
假设输入图像A大小为ma x na,相关核h大小为mb x nb,MATLAB的filter2的实现流程如下:
a、对输入图像补零,第一行之前和最后一行之后都补mb-1行,第一列之前和最后一列之后都补nb-1列(注意filter2不支持其他的边界补充选项,函数内部对输入总是补零)。
b、滑动相关核,将相关核的中心位于图像矩阵的每一个元素。
c、将相关核乘以对应的矩阵元素再求和
注意filter2不对核进行180°旋转,直接对应相乘再相加,这一点与conv2不同,下面有两者计算结果对比可看出这一点。
conv2(卷积滤波)和filter2(相关滤波)的结果比较
卷积核


imfilter函数
用法
B=imfilter(A,h,option1,option2,option3);A:输入图像,h:滤波核
option1:边界选项,可选的有:补充固定的值X(默认都补零),symmetric,replicate,circular
option2:输出图像大小选项,可选的有same(默认),full
option3:决定采用与filter2相同的相关滤波'corr'还是与conv2相同的卷积滤波'conv'


从图中可看出,当options1=0,options2='full',options3='conv'/'corr'时,所得结果与filter2和conv2取得的结果相同。
三种matlab函数的小结
1、filter2、conv2将输入转换为double类型,输出也是double的,输入总是补零(zero padded), 不支持其他的边界补充选项。
2、imfilter:不将输入转换为double,输出只与输入同类型,有灵活的边界补充选项
以上整理所得,有错误的话望指正。















 1685
1685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









