







局部最优的问题(The problem of local optima)
在深度学习研究早期,人们总是担心优化算法会困在极差的局部最优,不过随着深度学习理论不断发展,我们对局部最优的理解也发生了改变。我向你展示一下现在我们怎么看待局部最优以及深度学习中的优化问题。
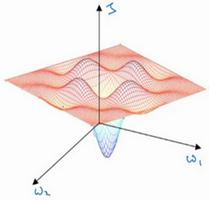
这是曾经人们在想到局部最优时脑海里会出现的图,也许你想优化一些参数,我们把它们称之为W_1和W_2,平面的高度就是损失函数。
在图中似乎各处都分布着局部最优。梯度下降法或者某个算法可能困在一个局部最优中,而不会抵达全局最优。如果你要作图计算一个数字,比如说这两个维度,就容易出现有多个不同局部最优的图,而这些低维的图曾经影响了我们的理解,但是这些理解并不正确。事实上,如果你要创建一个神经网络,通常梯度为零的点并不是这个图中的局部最优点,实际上成本函数的零梯度点,通常是鞍点。
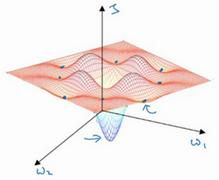
也就是在这个点,这里是W_1和W_2,高度即成本函数J的值。
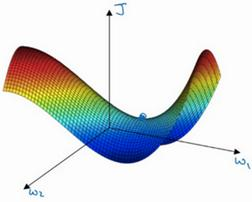
但是一个具有高维度空间的函数,如果梯度为0,那么在每个方向,它可能是凸函数,也可能是凹函数。如果你在2万维空间中,那么想要得到局部最优,所有的2万个方向都需要是这样,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7008
7008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









