










这项研究的论文来自PROMISE 2012,点击下载论文《DRETOM: developer recommendation based on topic models for bug resolution》
LDA自从2003年由David Blei(刚发现Andrew Ng竟然也是提出者之一)提出后就一直火的不行,特别在机器学习和文本挖掘领域被广泛研究和应用,造诣可圈可点。LDA能够从文本中学习出潜在的topics,挖掘文本的潜在结构。该模型认为在某个特定的语料集中,任意一篇doc都是由给定的N个topics中的若干个或全体构成。doc中的词取自特定的word-topic分布。使用LDA时我们不需要提供训练语料,也不需要对语料进行任何的预处理,我们要做就是设置4个参数:topic数N、迭代数、参数α和β。待算法执行完毕后,我们会得到N个topic,以及每一个主题下频繁共现的词集,用以表示该主题,下图是对Mozilla Firefox的Bug report集执行LDA后学校到的20个topic中的4个以及最能代表着4个topic的Top 10 words。(LDA的实现原理将在后续文章详细介绍)
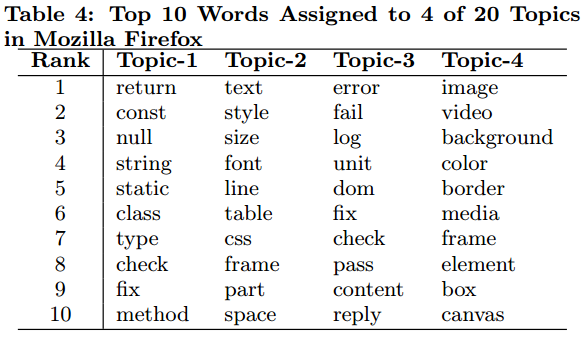
那么这篇文章为什么会想到用LDA来进行缺陷修复人的推荐呢?
首先需要注意的是这篇paper中的缺陷修复人和我先前文章《浅谈缺陷修复人预测(Bug Triaging)》提到的缺陷修复略有不同。本文把所有参与到某个Bug修复过程的开发者,包括实际修复人和提出修改意见的人,都作为这个bug合适的修复人。而之前的文章中提到的缺陷修复人仅表示bug的实际修复人。
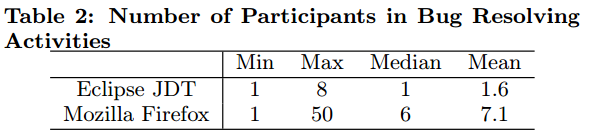
一个bug的修复是一个collaborative activity,许多开发者会在一起交流,给出修改意见,为Bug的修复做出自己的贡献。下面这张表给出的是对Eclipse JDT和Mozilla Firfox两个项目中参与Bug修复的人数统计。在Eclipse JDT中平均每个Bug约有2个人参与,而Mozilla Firfox中是7个。
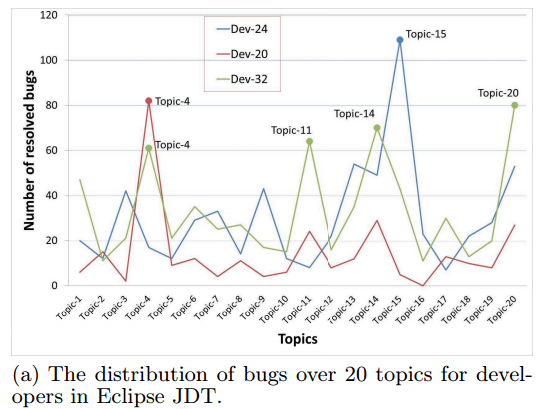
另外我们发现,每个开发者有自己的兴趣点和强项(这是不同,开发者可以对某个领域感兴趣,但并不意味就很在行,很牛叉)。换句话说开发者喜欢去修复跟自己兴趣或专攻方向相关的BUG。这里说的兴趣和专攻方向其实就是“主题”。为了证明这一点,本文的作者把Eclipse JDT的所有BUG借用LDA划分到20个topic中,然后统计了3个开发者DEV-24, DEV-20, DEV 32分别修复各个topic中Bug的数量,统计结果如下图所示。我们发现,DEV-24主要关注的是Topic-15上的BUG,DEV-20主要关注的是Topic-4上的BUG,而DEV-32主要关注的是Topic-4, topic-11, topic-14, topic-20上的BUG。
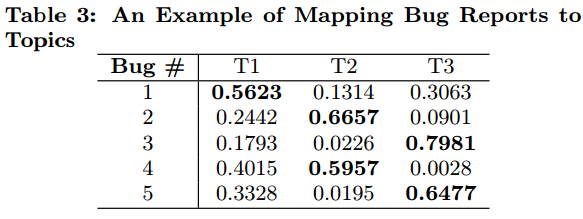
这里一个新的问题出现了,即作者是如何把Bug划分到不同主题的?要知道我们使用LDA建立了主题模型,也就是给出了20(本文中设置的topic数)个主题下的词集。那就好办了,我们只需要计算Bug report属于这个20个主题的概率,再取概率最大的那个topic和这个BUG建立映射关系就OK了。那归属概率怎么计算呢?最简单直接的方法,计算Bug Report和每个主题词集的cosin相似度,最后将20个相似度值归一化,搞定!!这里也举个例子,假设我们有3个主题,5个BUG,我们最终可以得到如下图所示的BUG-topic分布。
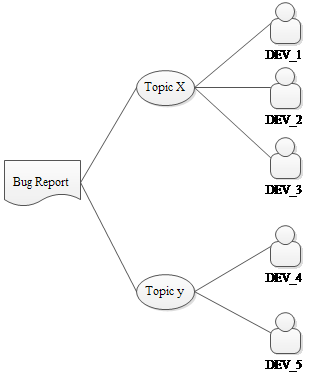
至此,基于主题模型的算法的基本思想就介绍完了,下面我们就需要将抽象的思想使用公式来具体表示出来。
给定一个BUG,我们需要预测每个developer适合修改该BUG的概率,我们可以用条件概率
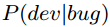 来表示。之前我们说将每个BUG之和概率最高的Topic进行映射,但不代表和其他topic就没有关系,同样的一个developer并不是关注了自己喜欢或专注的topic,跟其他topic就一点也没有关系。因此在计算最终概率的时候,所有的20个Topic都要考虑,计算公式如下图所示:
来表示。之前我们说将每个BUG之和概率最高的Topic进行映射,但不代表和其他topic就没有关系,同样的一个developer并不是关注了自己喜欢或专注的topic,跟其他topic就一点也没有关系。因此在计算最终概率的时候,所有的20个Topic都要考虑,计算公式如下图所示: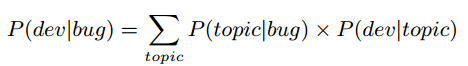
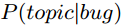 表示bug属于指定topic的概率,
表示bug属于指定topic的概率,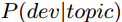 表示dev修改该topic的BUG的概率。有两部分组成,一部分是兴趣度,即dev对这个topic有多大兴趣,可以用这个topic中由该dev参与的BUG数占dev参与的总BUG数的比例度量,换句话说,dev修复的BUG中你这个topic到底占多少分量,占得的分量越重,说明越感兴趣,我们用
表示dev修改该topic的BUG的概率。有两部分组成,一部分是兴趣度,即dev对这个topic有多大兴趣,可以用这个topic中由该dev参与的BUG数占dev参与的总BUG数的比例度量,换句话说,dev修复的BUG中你这个topic到底占多少分量,占得的分量越重,说明越感兴趣,我们用 ;另一部分是专业度,即dev在这个topic上权不权威,这里用topic中有dev参数的BUG数占topic中BUG总数的比例来度量,也就是说在这个topic中dev修复BUG占比越高,说明dev在这个topic上越权威,我们用
;另一部分是专业度,即dev在这个topic上权不权威,这里用topic中有dev参数的BUG数占topic中BUG总数的比例来度量,也就是说在这个topic中dev修复BUG占比越高,说明dev在这个topic上越权威,我们用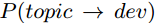 来表示。
来表示。
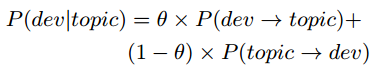
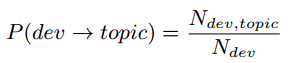
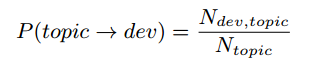
上式中使用差值参数θ来平衡兴趣度和专业度。在使用中要根据实际情况进行调整,没有一个经验值可供参考。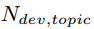
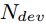
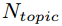
至此应用LDA主题模型来进行缺陷修复人推荐的方法介绍结束。至于最终的实验结果和评价指标,有兴趣的童鞋可以详读Paper。














 2732
2732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









