









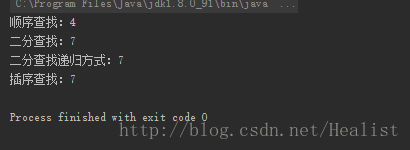
顺序查找、二分查找(非递归)、二分查找(递归)、插值查找:
public class Search {
int SequenceSearch(int[] arr, int value) {
for(int i=0; i<arr.length; i++) {
if(arr[i] == value) {
return i;
}
}
return -1;
}
int BinarySearch(int[] arr, int value) {
int low, high, mid;
low = 0;
high = arr.length-1;
while (low <= high) {
mid = (low + high)/2;
if(arr[mid] == value) {
return mid;
}
else if(arr[mid] > value) {
high = mid - 1;
}
else if(arr[mid] < value) {
low = mid + 1;
}
}
return -1;
}
int BinarySearchStack(int[] arr, int value, int low, int high) {
int mid = low + (high - low)/2;
if(arr[mid] == value) {
return mid;
}
else if(arr[mid] > value) {
return BinarySearchStack(arr, value, low, mid-1);
}
else if(arr[mid] < value) {
return BinarySearchStack(arr, value, mid+1, high);
}
return -1;
}
//插值查找其实与二分主要差别在于公式,每次不是二分了,是根据公式取的更贴近的一个值
int Interpolation(int[] arr, int value, int low, int high) {
int mid = low+(value-arr[low])/(arr[high]-arr[low])*(high-low);
if(arr[mid]==value)
return mid;
else if(arr[mid]>value)
return Interpolation(arr, value, low, mid-1);
else if(arr[mid]<value)
return Interpolation(arr, value, mid+1, high);
return -1;
}
public static void main(String[] args) {
Search search = new Search();
int[] arr = {20, 14, 25, 11, 6, 2, 5, 19, 35, 42, 55};
System.out.println("顺序查找:" + search.SequenceSearch(arr, 6));
int[] arr2 = {8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 20};
System.out.println("二分查找:" + search.BinarySearch(arr2, 15));
System.out.println("二分查找递归方式:" + search.BinarySearchStack(arr2, 15, 0, arr2.length-1));
System.out.println("插序查找:" + search.Interpolation(arr2, 15, 0, arr2.length-1));
}
}结果:
斐波那契查找:
1、斐波那契查找也叫做黄金分割法查找,它也是根据折半查找算法来进行修改和改进的。
2、对于斐波那契数列:1、1、2、3、5、8、13、21、34、55、89……(也可以从0开始),前后两个数字的比值随着数列的增加,越来越接近黄金比值0.618。比如这里的89,把它想象成整个有序表的元素个数,而89是由前面的两个斐波那契数34和55相加之后的和,也就是说把元素个数为89的有序表分成由前55个数据元素组成的前半段和由后34个数据元素组成的后半段,那么前半段元素个数和整个有序表长度的比值就接近黄金比值0.618,假如要查找的元素在前半段,那么继续按照斐波那契数列来看,55 = 34 + 21,所以继续把前半段分成前34个数据元素的前半段和后21个元素的后半段,继续查找,如此反复,直到查找成功或失败,这样就把斐波那契数列应用到查找算法中了。如下图:
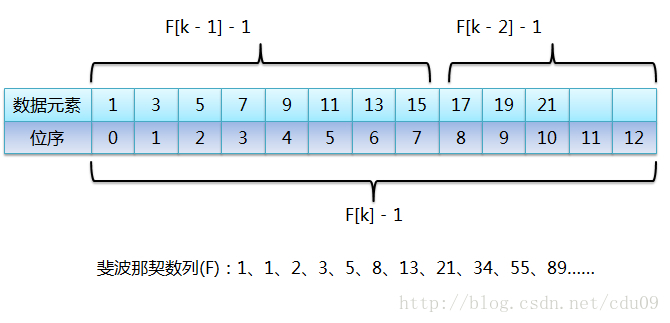
从图中可以看出,当有序表的元素个数不是斐波那契数列中的某个数字时,需要把有序表的元素个数长度补齐,让它成为斐波那契数列中的一个数值,当然把原有序表截断肯定是不可能的,不然还怎么查找。然后图中标识每次取斐波那契数列中的某个值时(F[k]),都会进行-1操作,这是因为有序表数组位序从0开始的,纯粹是为了迎合位序从0开始。所以用迭代实现斐波那契查找算法如下:
public class Search {
public static int[] fibonacci() {
int[] f = new int[20];
int i = 0;
f[0] = 1;
f[1] = 1;
for (i = 2; i < 20; i++) {
f[i] = f[i - 1] + f[i - 2];
}
return f;
}
public static int fibonacciSearch(int[] data, int key) {
int low = 0;
int high = data.length - 1;
int mid = 0;
// 斐波那契分割数值下标
int k = 0;
// 序列元素个数
int i = 0;
// 获取斐波那契数列
int[] f = fibonacci();
// 获取斐波那契分割数值下标
while (data.length > f[k] - 1) {
k++;
}
// 创建临时数组
int[] temp = new int[f[k] - 1];
for (int j = 0; j < data.length; j++) {
temp[j] = data[j];
}
// 序列补充至f[k]个元素
// 补充的元素值为最后一个元素的值
for (i = data.length; i < f[k] - 1; i++) {
temp[i] = temp[high];
}
for (int j : temp) {
System.out.print(j + " ");
}
System.out.println();
while (low <= high) {
// low:起始位置
// 前半部分有f[k-1]个元素,由于下标从0开始
// 则-1 获取 黄金分割位置元素的下标
mid = low + f[k - 1] - 1;
if (temp[mid] > key) {
// 查找前半部分,高位指针移动
high = mid - 1;
// (全部元素) = (前半部分)+(后半部分)
// f[k] = f[k-1] + f[k-1]
// 因为前半部分有f[k-1]个元素,所以 k = k-1
k = k - 1;
} else if (temp[mid] < key) {
// 查找后半部分,高位指针移动
low = mid + 1;
// (全部元素) = (前半部分)+(后半部分)
// f[k] = f[k-1] + f[k-1]
// 因为后半部分有f[k-1]个元素,所以 k = k-2
k = k - 2;
} else {
// 如果为真则找到相应的位置
if (mid <= high) {
return mid;
} else {
// 出现这种情况是查找到补充的元素
// 而补充的元素与high位置的元素一样
return high;
}
}
}
return -1;
}
public static void main(String[] args) {
Search search = new Search();
int[] data = { 1, 5, 15, 22, 25, 31, 39, 42, 47, 49, 59, 68, 88 };
int value = 39;
int position = fibonacciSearch(data, value);
System.out.println("值" + value + "的元素位置为:" + position);
}
}运行结果: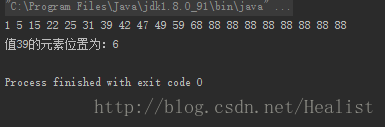
哈希查找
哈希查找是通过计算数据元素的存储地址进行查找的一种方法。O(1)的查找,即所谓的秒杀。哈希查找的本质是先将数据映射成它的哈希值。哈希查找的核心是构造一个哈希函数,它将原来直观、整洁的数据映射为看上去似乎是随机的一些整数。
哈希查找的操作步骤:
1) 用给定的哈希函数构造哈希表;
2) 根据选择的冲突处理方法解决地址冲突;
3) 在哈希表的基础上执行哈希查找。
建立哈希表操作步骤:
1) step1 取数据元素的关键字key,计算其哈希函数值(地址)。若该地址对应的存储空间还没有被占用,则将该元素存入;否则执行step2解决冲突。
2) step2 根据选择的冲突处理方法,计算关键字key的下一个存储地址。若下一个存储地址仍被占用,则继续执行step2,直到找到能用的存储地址为止。
哈希查找步骤为:
1) Step1 对给定k值,计算哈希地址 Di=H(k);若HST为空,则查找失败;若HST=k,则查找成功;否则,执行step2(处理冲突)。
2) Step2 重复计算处理冲突的下一个存储地址 Dk=R(Dk-1),直到HST[Dk]为空,或HST[Dk]=k为止。若HST[Dk]=K,则查找成功,否则查找失败。
比如说:”5“是一个要保存的数,然后我丢给哈希函数,哈希函数给我返回一个”2”,那么此时的”5“和“2”就建立一种对应关系,这种关系就是所谓的“哈希关系”,在实际应用中也就形成了”2“是key,”5“是value。
那么有的朋友就会问如何做哈希,首先做哈希必须要遵守两点原则:
①: key尽可能的分散,也就是我丢一个“6”和“5”给你,你都返回一个“2”,那么这样的哈希函数不尽完美。
②:哈希函数尽可能的简单,也就是说丢一个“6”给你,你哈希函数要搞1小时才能给我,这样也是不好的。
其实常用的做哈希的手法有“五种”:
第一种:”直接定址法“。
很容易理解,key=Value+C;这个“C”是常量。Value+C其实就是一个简单的哈希函数。
第二种:“除法取余法”。
很容易理解, key=value%C;解释同上。
第三种:“数字分析法”。
这种蛮有意思,比如有一组value1=112233,value2=112633,value3=119033,
针对这样的数我们分析数中间两个数比较波动,其他数不变。那么我们取key的值就可以是
key1=22,key2=26,key3=90。
第四种:“平方取中法”。此处忽略,见名识意。
第五种:“折叠法”。
这种蛮有意思,比如value=135790,要求key是2位数的散列值。那么我们将value变为13+57+90=160,然后去掉高位“1”,此时key=60,哈哈,这就是他们的哈希关系,这样做的目的就是key与每一位value都相关,来做到“散列地址”尽可能分散的目地。
影响哈希查找效率的一个重要因素是哈希函数本身。当两个不同的数据元素的哈希值相同时,就会发生冲突。为减少发生冲突的可能性,哈希函数应该将数据尽可能分散地映射到哈希表的每一个表项中。
解决冲突的方法有以下两种:
(1) 开放地址法
如果两个数据元素的哈希值相同,则在哈希表中为后插入的数据元素另外选择一个表项。当程序查找哈希表时,如果没有在第一个对应的哈希表项中找到符合查找要求的数据元素,程序就会继续往后查找,直到找到一个符合查找要求的数据元素,或者遇到一个空的表项。
(2) 链地址法
将哈希值相同的数据元素存放在一个链表中,在查找哈希表的过程中,当查找到这个链表时,必须采用线性查找方法。
实现哈希函数为“除法取余法”,解决冲突为“开放地址线性探测法”,代码如下:
public class HashSearch {
public static void main(String[] args) {
//“除法取余法”
int hashLength = 13;
int [] array = { 13, 29, 27, 28, 26, 30, 38 };
//哈希表长度
int[] hash = new int[hashLength];
//创建hash
for (int i = 0; i < array.length; i++)
{
insertHash(hash, hashLength, array[i]);
}
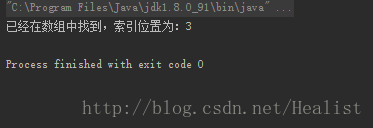
int result = searchHash(hash,hashLength, 29);
if (result != -1)
System.out.println("已经在数组中找到,索引位置为:" + result);
else
System.out.println("没有此原始");
}
/****
* Hash表检索数据
*
* @param hash
* @param hashLength
* @param key
* @return
*/
public static int searchHash(int[] hash, int hashLength, int key) {
// 哈希函数
int hashAddress = key % hashLength;
// 指定hashAdrress对应值存在但不是关键值,则用开放寻址法解决
while (hash[hashAddress] != 0 && hash[hashAddress] != key) {
hashAddress = (++hashAddress) % hashLength;
}
// 查找到了开放单元,表示查找失败
if (hash[hashAddress] == 0)
return -1;
return hashAddress;
}
/***
* 数据插入Hash表
*
* @param hash 哈希表
* @param hashLength
* @param data
*/
public static void insertHash(int[] hash, int hashLength, int data) {
// 哈希函数
int hashAddress = data % hashLength;
// 如果key存在,则说明已经被别人占用,此时必须解决冲突
while (hash[hashAddress] != 0) {
// 用开放寻址法找到
hashAddress = (++hashAddress) % hashLength;
}
// 将data存入字典中
hash[hashAddress] = data;
}
}运行结果:
本博客内容转发参考自:
查找算法之哈希查找
斐波那契查找(黄金分割法查找)















 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









