







一、背景
为了要及时获取当前新型冠状病毒疫情的相关数据,项目组需要构造一个爬虫跑批爬取数据。了解爬虫的朋友可能都比较熟悉,常用的爬虫技术包括Python中的requests+lxm+beautifulsoup,或者Python的爬虫框架scrapy框架等等,一般来说,采用Python爬虫入门比较简单,示例丰富,对于一般的网站、app、微信小程序等几乎都可以手到擒来(python爬取微信小程序(实战篇)、Python爬取微信小程序(Charles))。但是唯一一点比较麻烦的是,在相应的生产环境上可能并没有对应的服务器或者Python环境,一般都是Java应用分布式部署于Linux服务器上,而Linux会自带Python2版本的环境,对于如今的Python3不是很友好,所以本文采用Java完成一个简单的爬虫任务,并介绍一个Java编写的爬虫框架webmagic。过程看似简单,实则道路崎岖,更有webmagic的大坑。
代码demo参考GitHub:GitHub
二、简单的逻辑
此次要爬取的数据如下所示,网页链接为:https://ad.thsi.cn/2020/yiqing2020/index.html
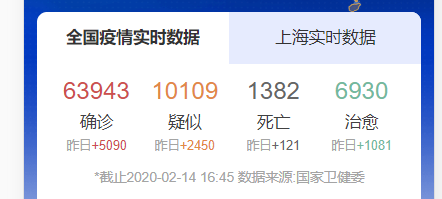
其中包括确诊人数及其增加数、疑似人数及其增加数、死亡人数及其增加数、治愈人数及其增加数、截止时间等九个数据。打开网页F12查看,发现数据结构其实比较简单,但是查看网页源代码后发现是这样:

说明数据是在js中延迟加载后渲染出来的,这时候就需要用到一个著名的web应用程序测试的工具selenium,在完成自动化测试、爬虫自动登录、动态解析网页时用处很大。
这里我们选择使用ChromeDriver来加载网页,等待1秒渲染结束后解析标签,获得数据。主要爬虫函数的代码比较简单,如下:
@Override
public void dataCrawler() {
// 设置chrome选项
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
// 建立selenium 驱动
WebDriver driver = new ChromeDriver(options);
// 目标地址
driver.get("https://ad.thsi.cn/2020/yiqing2020/index.html");
try {
// 延迟加载,保证JS数据正常加载
Thread.sleep(1000);
// 解析标签
WebElement webElement = driver.findElement(By.id("easter_egg"));
String str = webElement.getAttribute("outerHTML");
Html html = new Html(str);
// 确诊人数
String confirmNum = html.xpath("//*[@class='icon-item confirm']/div[1]/text()").get();
// 确诊较昨日新增人数
String confirmAddNum = html.xpath("//*[@class='icon-item confirm']/div[3]/span/text()").get();
// 疑似人数
String unconfirmNum = html.xpath("//*[@class='icon-item unconfirm']/div[1]/text()").get();
// 疑似较昨日新增人数
String unconfirmAddNum = html.xpath("//*[@class='icon-item unconfirm']/div[3]/span/text()").get();
// 死亡人数
String deadNum = html.xpath("//*[@class='icon-item dead']/div[1]/text()").get();
// 死亡较昨日新增人数
String deadAddNum = html.xpath("//*[@class='icon-item dead']/div[3]/span/text()").get();
// 治愈人数
String cureNum = html.xpath("//*[@class='icon-item cure']/div[1]/text()").get();
// 治愈较昨日新增人数
String cureAddNum = html.xpath("//*[@class='icon-item cure']/div[3]/span/text()").get();
// 更新时间
String updateTime = html.xpath("//*[@class='data-from']/text()").get();
// 判断解析数据是否为空,为空的话redis中的数据不做更新
if (StringUtils.isEmpty(confirmNum) || StringUtils.isEmpty(confirmAddNum) || StringUtils.isEmpty(unconfirmNum) ||
StringUtils.isEmpty(unconfirmAddNum) || StringUtils.isEmpty(deadNum) || StringUtils.isEmpty(deadAddNum) ||
StringUtils.isEmpty(cureNum) || StringUtils.isEmpty(cureAddNum) || StringUtils.isEmpty(updateTime)) {
_logger.error("数据解析异常!存在空值!");
} else {
Map<String, Object> map = new HashMap<>();
map.put("confirmNum", confirmNum);
map.put("confirmAddNum", confirmAddNum);
map.put("unconfirmNum", unconfirmNum);
map.put("unconfirmAddNum", unconfirmAddNum);
map.put("deadNum", deadNum);
map.put("deadAddNum", deadAddNum);
map.put("cureNum", cureNum);
map.put("cureAddNum", cureAddNum);
map.put("updateTime", updateTime);
JSONObject jsonObject = new JSONObject(map);
//
saveDataToCommonServiceRedis(jsonObject.toString());
}
} catch (Exception e) {
_logger.error("疫情数据爬虫跑批任务,数据解析异常!异常信息:", e);
} finally {
//
driver.close();
}
}
由于是maven项目,在pom文件中加载的包如下:
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-api</artifactId>
<version>3.14.0</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chrome-driver</artifactId>
<version>3.14.0</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-api</artifactId>
<version>3.14.0</version>
</dependency>
<!-- webmagic -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
爬取的算法也很好理解。首先设置ChromeOptions,及Chrome浏览器的配置,这里设置为不打开浏览器访问页面( options.addArguments("--headless")),其次建立selenium的驱动,用以访问目标网址,然后使用延迟加载,使当前线程休眠1秒,目的是保证js数据正常加载结束后可以正常解析标签。个人认为不论是爬取静态网页还是动态加载的数据,最好都延迟加载,确保js加载的一些文本、图片等都可以正常拿到标签结构。拿到数据后,获取这一部分的标签字符串,转为HTML,再使用xpath解析即可。
纵观整个过程,其实并不复杂,思路很清晰,实现的方式也与Python中的爬虫方式十分类似。以上是基本且简单的Java爬虫的实现,但是在刚开始做的时候却走了很多弯路,原因是在研究Java爬虫框架webmagic与已有的spring项目怎么结合?
三、与现有框架结合
Webmagic爬虫框架本身结构并不是十分复杂,结构如下图所示,共分为四个部分。
Downloader:负责请求url获取访问的数据(html页面、json等)、
PageProcessor:解析Downloader获取的数据、
Pipeline:PageProcessor解析出的数据由Pipeline来进行保存或者说叫持久化、
Scheduler:调度器通常负责url去重,或者保存url队列,PageProcessor解析出的url可以加入Scheduler队列,用于下一次的爬取。
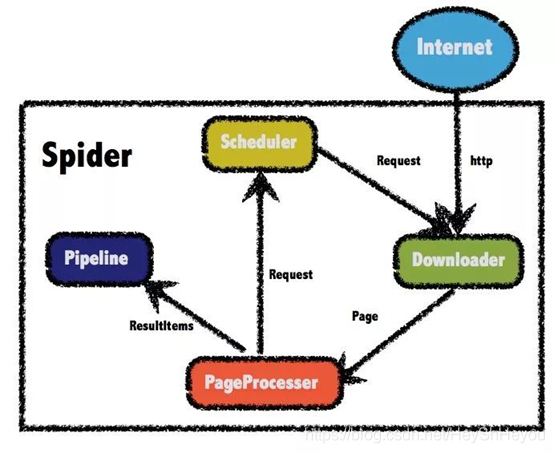
Webmagic框架与scrapy框架十分相似,组成部分的功能几乎完全相同。在使用的时候,只要实现PageProcessor 接口,即可启动爬虫任务。
如果在新建spider爬虫实例的时候添加了pipeline,即:
Spider.create(new EpidemicDataCrawlerController())
.addUrl("https://ncov.dxy.cn/ncovh5/view/pneumonia")
.thread(1)
.addPipeline(new EpidemicDataPipeLineController())
.run();在重写的process(Page page)方法中可通过
page.putField("data", data);方式将数据传送到指定的pipeline中,指定的pipeline接收如下:
page.getResultItems().get("data")到这里看似很正常,但是与spring框架结合的时候却存在一些很“诡异”的问题,例如,使用注解的方式注入实例,在初始化的时候实例对象是存在的,但是到了process()方法或pipeline中,却无法拿到实例对象,如下所示:
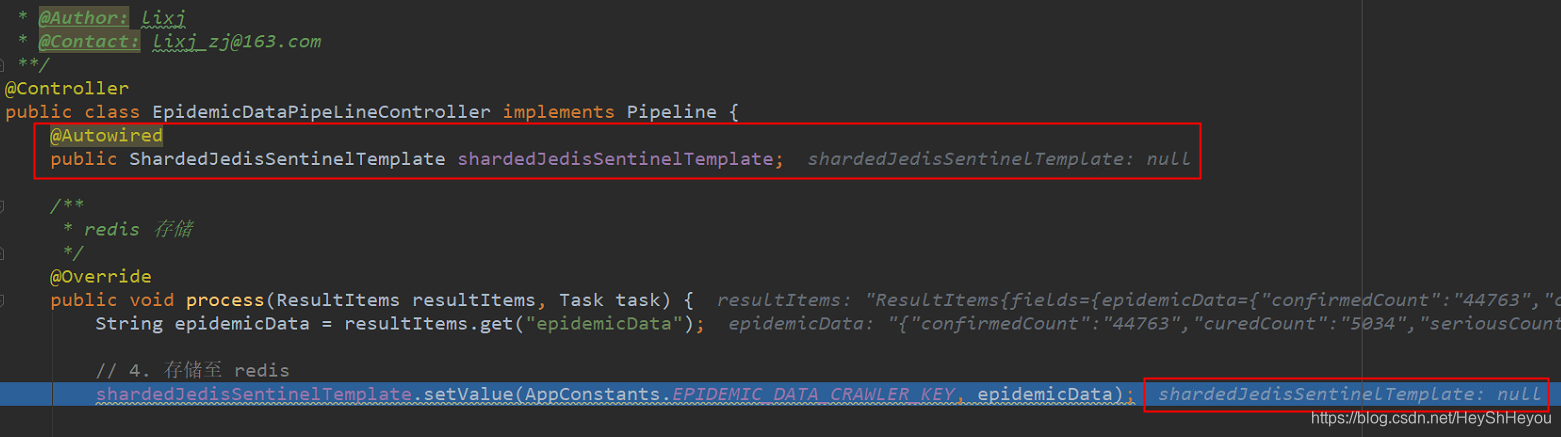
在process中已经解析出了数据,理论上来说可以通过系统初始化时已经注入好的bean对象,调用其方法将数据进行持久化操作。但是在此时可以看到redis实例是为null,通过单步调试可以发现初始的时候是有实例对象的,究其原因,本人认为,在spring框架中,已有的实例对象在系统初始化运行后已经被注入,但是在webmagic框架中调用时,却无法找到该对象具体的实现,所以最终在调用的时候对象显示为null,报空指针异常。
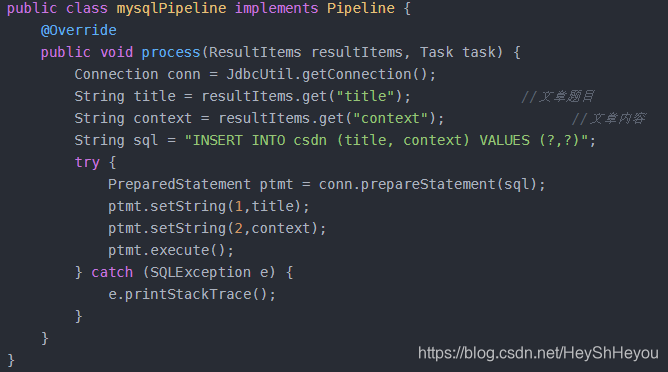
除了bean对象外,自定义的Dao在使用的时候也是为null,在看了官网的示例之后,发现在WebMagic已经提供的几个Pipeline中,都是打印到控台、持久化到文件保存等,唯一一个将结果保存到MySQL中的jobhunter项目却在集成已有的项目中无法复现,网上有人的实现方式如下,通过直连数据库工具类存储数据到MySQL,但是本人采用注解的方式调用bean对象的方法却未能实现数据的持久化。所以,本人最终放弃了webmagic的框架与已有系统的结合,只是用的webmagic库中的一个HTML的解析类完成了第一部分的爬虫代码。
四、总结与反思
Webmagic框架本身是一款入门简单、使用方便的爬虫框架,基本的需求与任务大都可以完成,但是在与公司已有的系统结合中,需要尝试一下是否兼容,并不断通过单步调试找出问题的最终原因,才能更好的使用新的技能。
五、参考链接
http://webmagic.io/docs/zh/posts/ch6-custom-componenet/pipeline.html
https://blog.csdn.net/qq_41061437/article/details/85287803














 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









