







视频镜头检测
最近CCF BDCI也搞得差不多了,理一理
推荐阅读:浙大的一个PPT报告
什么是视频镜头检测(shot detection)
Shot边界检测(Shot boundary detection ,SBD)指在视频中自动检测镜头的边界,是视频分析,视频索引,视频摘要,视频搜索和其他基于内容的视频操作的基本的预处理步骤。自动SBD是2001至2007年TRECVID比赛中的一项重要内容,现在视频镜头检测的技术都是比较成熟的技术了。
视频流数据中最小的数据单位是‘镜头’,所以视频分割的的目的是将视频分割成一个个视频镜头,而不是单一的帧。镜头的里面就是包含的就当前场景的一个帧的序列。
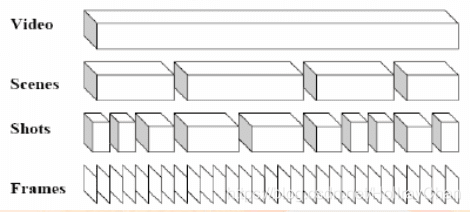
如何镜头检测的流程图
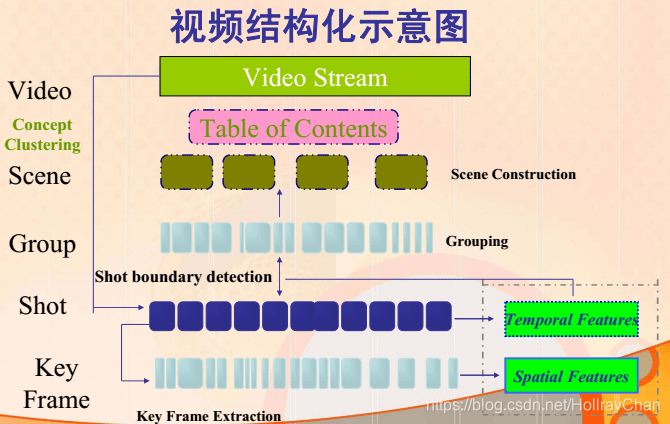
常见的方法包括:
Machine Learning 机器学习的方法
colour histograms(Superscript number denotes number of bins used)颜色直方图的方法
Flash:针对闪光使用了特殊的方法。
LVals:在进行帧间比较的时候使用了亮度值。
Cmpr:operated only in the compressed (MPEG-1) domain (Cmpr).
AThr:使用了自适应的阈值法。
MCmp:使用了运动补偿。
Edgs:使用了边缘检测。
STmp:运用了时空特征。
代码实现
方法有很多,在github中搜索关键词:shot boundary detection,一些比价好的实现结果。
全卷积神经网络的实现
全卷积神经网络的实现版本2
基于opencv-python的实现
基于opencv-c++的实现
因为时间紧迫,楼主主要调试了基于K-Means聚类的镜头检测,直接上代码,分好的镜头将存在shot的list中。
import cv2
import numpy as np
from functools import reduce
from sklearn.cluster import KMeans
def bhattacharyya_ruler(hist1, hist2):
row = len(hist1)
col = len(hist1[0])
row2 = len(hist2)
if (len(hist2) !=row or len(hist2[0]) != col):
return False
#normalization each histogram
sum = 0
sum2 = 0
for i in range(row):
a1 = reduce(lambda x,y: x+y, hist1[i], 0)
a2 = reduce(lambda x,y:x+y, hist2[i],0)
sum += a1
sum2 += a2
for i in range(row):
hist1[i] = list(map(lambda a : float(a)/sum, hist1[i]))
hist2[i] = list(map(lambda a: float(a) / sum2, hist2[i]))
#measuring Bhattacharyya distance
dist = 0
for i in range(row):
for j in range(col):
dist += np.sqrt(hist1[i][j] * hist2[i][j])
return dist
if __name__ == "__main__":
file_addr = "video.mp4" #video path
cap = cv2.VideoCapture(file_addr)
#ROI window parameter
n_rows = 3
n_images_per_row = 3
fc = 0 #frame_counter
images = [] #frames
hist = [] #histograms
while cap.isOpened():
# Capture frame-by-frame
ret, frame = cap.read()
if not ret:
break
hueFrames = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV) #convert Hue value
height, width, ch = hueFrames.shape # find shape of frame and channel
#cv2.imshow('frame'+str(fc+1), frame)
roi_height = int(height / n_rows) #to divide 9 pieces find height value for each frame
roi_width = int(width / n_images_per_row) #to divide 9 pieces find width value for each frame
#ROI part
images.append([]) #first row frame_id, column raw piece_id
hist.append([]) #first row frame_id, column raw piece_id
for x in range(0, n_rows):
for y in range(0,n_images_per_row):
#i am splitting into 9 pieces of each frame and added to the images 2d matrix
#row defines frame_id and column defines piece_id
tmp_image=hueFrames[x*roi_height:(x+1)*roi_height, y*roi_width:(y+1)*roi_width]
images[fc].append(tmp_image)
# Display the resulting sub-frame and calc local histogram values
for i in range(0, n_rows*n_images_per_row):
hist[fc].append(cv2.calcHist([images[fc][i]], [0], None, [256], [0, 256]))
fc += 1#frame counter 1 up
if cv2.waitKey(1) & 0xFF == ord('q'):
break
dist = []
#calculate bhattacharya dist
for i in range(0,len(hist)-1):
dist.append(bhattacharyya_ruler(hist[i],hist[i+1]))
clt = KMeans(n_clusters=2)
clt.fit(dist) #calculate Kmeans
big_center = 1 #select which cluster includes shot frames
shots = [] #shots list. List will be include frame id
for i in range(0,len(clt.labels_)):
if (big_center == clt.labels_[i]):
#get differnt shots
shots.append(i+1)
cap.release()
cv2.destroyAllWindows()
源码:基于机器学习—聚类的镜头检测
待续未完














 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









