







这篇文章主要讲解有关文件操作的一些需要掌握的知识点。
文件有千千万万,但是在我们的程序设计当中,我们谈的文件一般有两种:
1)程序文件:包括源程序文件(后缀为.c),目标文件(windows环境后缀为.obj),可执行程序(windows环境后缀为.exe)。
2)数据文件:文件的内容不一定是程序,而是程序运行时读写的数据,比如程序运行需要从中读取数据的文件,或者输出内容的文件。
而在这里,我们主要提到的是数据文件。

1.文件名
我们知道,名字都是用来标识和区别事物的,那么文件名也是这样,是区别各个文件的标识。
一个文件名要包含 3 个部分:文件路径+文件名主干+文件后缀
如:C:\Windows\System32\drivers\etc.txt
其中 :C:\Windows\System32\drivers\ 是文件路径,etc 是文件名主干,txt 是文件名后缀。
当然了,各个平台的文件路径并不相同,以及为了方便起见文件标识通常别称为文件名
2.文件类型
根据数据的组织形式,数据文件被称为文本文件 或者二进制文件。
二进制文件:数据在内存中以二进制的形式存储,并不加转换的输出到外存。
文本文件 :要求在外存上以ASCII码的形式存储,需要在存储前转换,以ASCII字符的形式存储的文件。
那么一个数据在内存中是怎样存储的 呢?
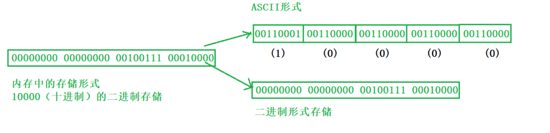
字符一律以ASCII形式存储,数值型数据既可以用ASCII形式存储,也可以使用二进制形式存储。
如有整数10000,如果以ASCII码的形式输出到磁盘,则磁盘中占用5个字节(每个字符一个字节)
而二进制形式输出,则在磁盘上只占4个字节(VS2019测试)。
如:
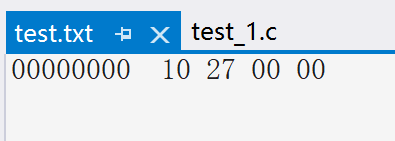
我们可以测试一番:

我们打开的时候要注意以二进制编辑器 来打开,你会发现出现了如下图显示的一串数字,其中它们是以十六进制现实的,转换一下,刚好是上图显示的那串二进制数字(注意VS采用的是小端储存模式)
3.数据流
数据流:
指程序于数据的交互是以流的形式进行的,包括输入流与输出流;
输入流:
程序从输入流读取数据源。数据源包括键盘,文件,网络等,即:将数据源读入到程序的外界通道。
输出流:
程序向输出流写入数据。将程序中的数据输出到外界(显示器,打印机,文件,网络,等)的通信通道。
采用数据流的目的:使得输入输出独立于设备,不关心数据源来自何方,也不管输出的目的地是何种设备。

4.文件缓冲区
缓冲区:
指在程序运行时,所提供的额外内存,可用来暂时存放做准备执行的数据。它可在创建、访问、删除静态数据上,大大提高运行速度(速度的提高程度有时甚至可高达几十倍),
为我们提供了极大的便捷,节省了大量的时间与精力
文件缓冲区:
ANSIC 标准采用“缓冲文件系统 ”处理的数据文件的,所谓缓冲文件系统是指系统自动地在内存中为程序中每一个正在使用的文件开辟一块“文件缓冲区”。
从内存向磁盘输出数据会先送到内存中的缓冲区,装满缓冲区后才一起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓冲区(充满缓冲区),
然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小根据C编译系统决定的。
如:

无论是输入输出,都先在缓冲区里存着,然后在进行输入输出。
5.文件指针
缓冲文件系统中,关键的概念是“文件类型指针”,简称“文件指针”。
每个被使用的文件都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名字,文件状态及文件当前的位置等)。
这些信息是保存在一个结构体变量中的。该结构体类型是有系统声明的,取名FILE。
我们可以来看在VS 2019中FILE的声明:
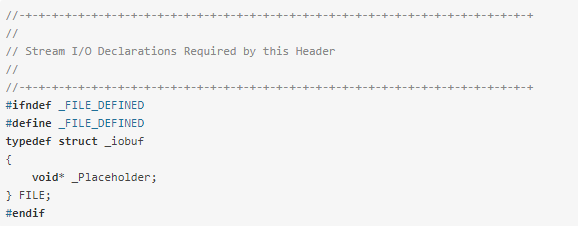
不同的C编译器的FILE类型包含的内容不完全相同,但是大同小异。
每当打开一个文件的时候,系统会根据文件的情况自动创建一个FILE结构的变量,并填充其中的信息,使用者不必关心细节。
一般都是通过一个FILE的指针来维护这个FILE结构的变量,这样使用起来更加方便。
如下:我们便创建了一个文件指针
FILE* pf;//文件指针变量
定义pf是一个指向FILE类型数据的指针变量。可以使pf指向某个文件的文件信息区(是一个结构体变量)。
通过该文件信息区中的信息就能够访问该文件。也就是说,通过文件指针变量能够找到与它关联的文件。
比如:

好了,今天的分享就到这里了,希望对大家有所帮助!
最后,特别推荐一个分享C/C++和算法的优质内容,学习交流,技术探讨,面试指导,简历修改...还有超多源码素材等学习资料,零基础的视频等着你!
还没关注的小伙伴,可以长按关注一下:















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









