







1、冒泡排序
- 冒泡排序只会操作相邻的两个数据。
- 每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。
- 一次冒泡会让至少一个元素移动到它应该在的位置,重复 n 次,就完成了 n 个数据的排序工作。
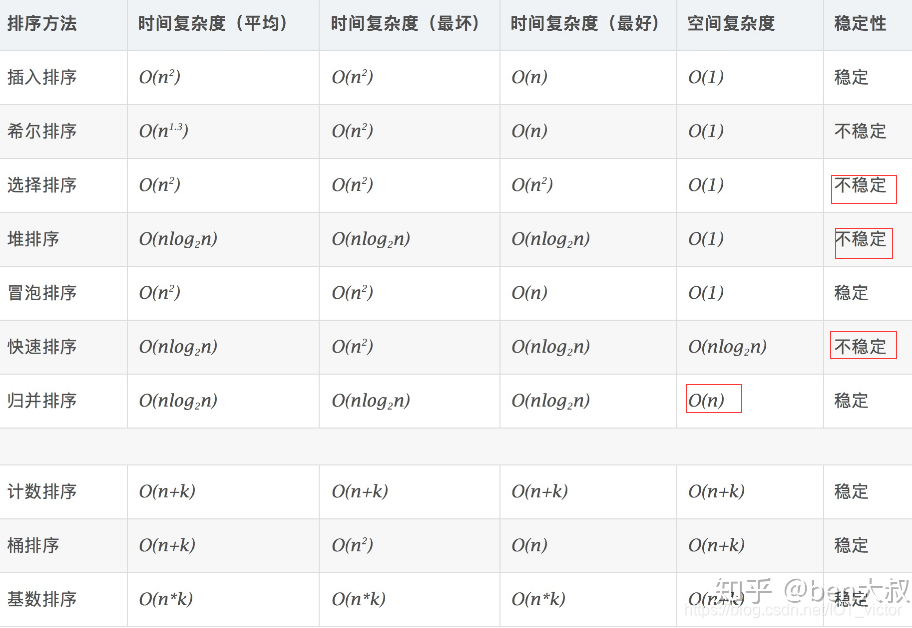
第一次冒泡操作的详细过程
经过一次冒泡操作之后,6 这个元素已经存储在正确的位置上。要想完成所有数据的排序,我们只要进行 6 次这样的冒泡操作就行了。

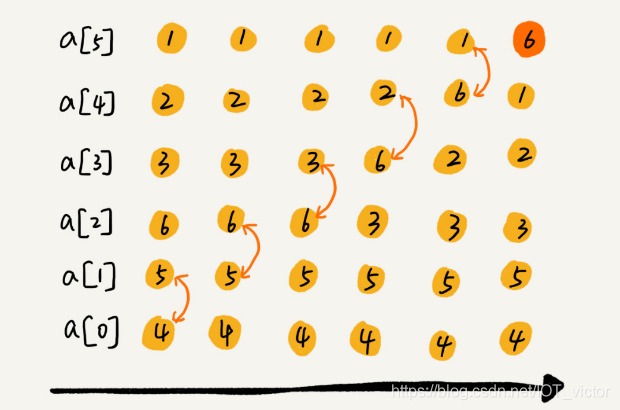
实际上,冒泡过程还可以优化。当某次冒泡操作已经没有数据交换时,说明已经达到完全有序,不用再继续执行后续的冒泡操作。下图中的另外一个例子,这里面给 6 个元素排序,只需要 4 次冒泡操作就可以了。
优化后的冒泡排序代码如下:
"""
优化的冒泡排序:
当某次冒泡操作已经没有数据交换时,说明已经达到完全有序,不用再继续执行后续的冒泡操作
"""
def bubble_sort(a):
'''
:param a: List[int]
'''
length = len(a)
if length <= 1:
return
for i in range(length):
made_swap = False
# 下标j + 1 最大为 length - 1
for j in range(length-1-i):
if a[j] > a[j+1]:
a[j], a[j+1] = a[j+1], a[j]
made_swap = True
# 优化:无数据交换,结束排序操作
if not made_swap:
break
return a
if __name__ == '__main__':
a = [7,1,4,3,6,5]
print(bubble_sort(a))
2、插入排序
首先,我们将数组中的数据分为两个区间,已排序区间和未排序区间。初始已排序区间只有一个元素,就是数组的第一个元素。插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。重复这个过程,直到未排序区间中元素为空,算法结束。
如图所示,要排序的数据是 4,5,6,1,3,2,其中左侧为已排序区间,右侧是未排序区间。
插入排序也包含两种操作,一种是元素的比较,一种是元素的移动。当我们需要将一个数据 a 插入到已排序区间时,需要拿 a 与已排序区间的元素依次比较大小,找到合适的插入位置。找到插入点之后,我们还需要将插入点之后的元素顺序往后移动一位,这样才能腾出位置给元素 a 插入。

代码如下:
"""
插入排序包含两种操作,一种是元素的比较,一种是元素的移动。
当我们需要将一个数据 a 插入到已排序区间时,需要拿 a 与已排序区间的元素依次比较大小,找到合适的插入位置。
找到插入点之后,我们还需要将插入点之后的元素顺序往后移动一位,这样才能腾出位置给元素 a 插入。
"""
def insertion_sort(a):
'''
:param a: List[int]
'''
length = len(a)
if length <= 1:
return
for i in range(1, length):
value = a[i] # 待插入
j = i - 1
# 查找插入位置,在前面的已排序区间,拿value与已排序区间的元素依次比较大小
while j >= 0 and a[j] > value:
# 数据向后移动
a[j+1] = a[j]
j -= 1
# 插入数据
a[j+1] = value
return a
if __name__ == '__main__':
a = [7,1,4,3,6,5]
print(insertion_sort(a))
3、选择排序
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
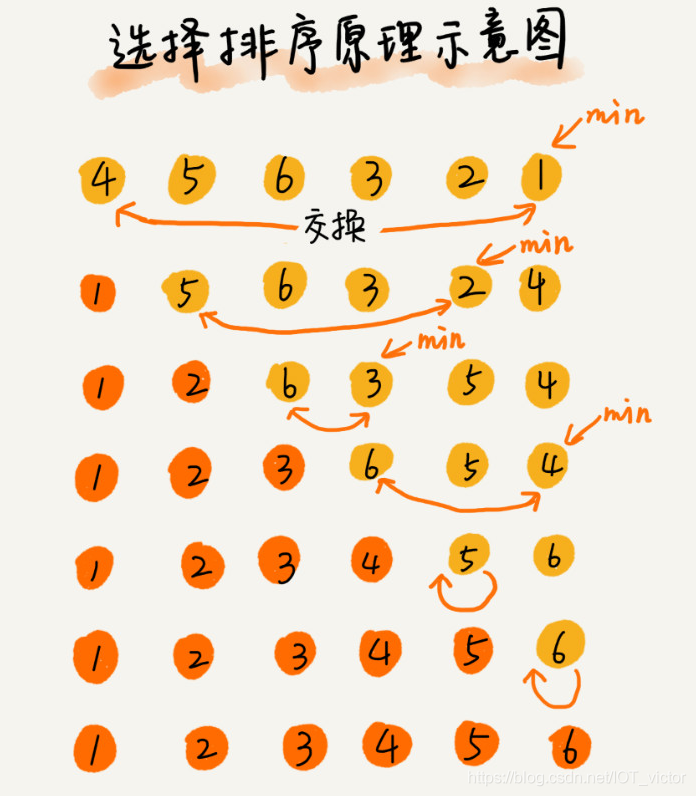
选择排序是一种不稳定的排序算法。从图中可以看出,选择排序每次都要找剩余未排序元素中的最小值,并和前面的元素交换位置,这样破坏了稳定性。
比如 5,8,5,2,9 这样一组数据,使用选择排序算法来排序的话,第一次找到最小元素 2,与第一个 5 交换位置,那第一个 5 和中间的 5 顺序就变了,所以就不稳定了。
正是因此,相对于冒泡排序和插入排序,选择排序就稍微逊色了。
代码如下:
def selection_sort(a):
length = len(a)
if length <= 1:
return
for i in range(length):
# i是每次已排序区间的末尾
min_index = i
min_val = a[i]
# 查找未排序区间中最小的元素
for j in range(i, length):
if a[j] < min_val:
# 未排序区间最小的元素
min_val = a[j]
min_index = j
a[i], a[min_index] = a[min_index], a[i]
return a
if __name__ == '__main__':
a = [7,1,4,3,6,5]
print(selection_sort(a))小结
1、冒泡排序和插入排序的时间复杂度相同,都是O(n^2),在实际的软件开发中,为什么更倾向于使用插入排序而不是冒泡排序算法呢?
答:
从代码实现上来看,冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要3个赋值操作,而插入排序只需要1个。用冒泡排序,需要 K 次交换操作,每次需要 3 个赋值语句,所以交换操作总耗时就是 3*K 单位时间。而插入排序中数据移动操作只需要 K 个单位时间。
所以在对相同数组进行排序时,冒泡排序的运行时间理论上要长于插入排序。
2、三种排序算法对比
冒泡、插入、选择排序都有一个共同点,将待排序数列分为已排序和未排序两部分。在未排序的部分中查找一个最值,放到已排序数列的恰当位置。
具体到代码层面,外层循环的变量用于分割已排序和未排序数,内层循环的变量用于在未排序数中查找。从思路上看,这三种算法其实是一样的,所以时间复杂度也相同。
3、逆序度 = 满有序度 - 有序度
拿冒泡排序的例子来说明。要排序的数组的初始状态是 4,5,6,3,2,1 ,其中,有序元素对有 (4,5) (4,6)(5,6),所以有序度是 3。n=6,所以排序完成之后终态的满有序度为 n*(n-1)/2=15。
比较和交换。每交换一次,有序度就加 1。不管算法怎么改进,交换次数总是确定的,即为逆序度,也就是n*(n-1)/2–初始有序度。此例中就是 15–3=12,要进行 12 次交换操作。
同理插入排序的移动操作的总次数,等于逆序度。














 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









