





飞算AI 3.2.0实战评测:10分钟搭建企业级RBAC权限系统
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
摘要
作为一名深耕企业级应用开发多年的技术人,我深知权限管理系统的重要性和复杂性。传统的RBAC(基于角色的访问控制)系统开发往往需要数周甚至数月的时间,涉及用户管理、角色定义、权限分配、资源控制等多个维度的复杂逻辑。然而,随着AI辅助开发工具的快速发展,这一切正在发生根本性的改变。
今天,我将带大家深度体验飞算AI 3.2.0版本的最新功能,通过一个完整的实战案例,展示如何在10分钟内搭建一个功能完整的企业级RBAC权限系统。这不仅仅是一次技术评测,更是对AI驱动开发模式的深度探索。
在这次实战中,我们将构建一个包含用户管理、角色管理、权限控制、资源访问等核心功能的权限系统。系统将支持多租户架构,具备细粒度的权限控制能力,并提供完整的API接口和前端管理界面。通过飞算AI的智能分析和代码生成能力,我们将见证从需求分析到代码实现的全流程自动化。
飞算AI 3.2.0版本在智能分析、自定义开发规范、引导式开发等方面都有显著提升。特别是其深度理解老项目的能力,让我们能够在现有系统基础上快速扩展权限功能。同时,AI开发智囊功能为复杂的权限设计提供了专业的建议和最佳实践指导。
通过这次实战评测,我们不仅要验证飞算AI的技术能力,更要探讨AI辅助开发在企业级应用中的实际价值。让我们一起踏上这段技术探索之旅,见证AI如何重新定义软件开发的效率边界。
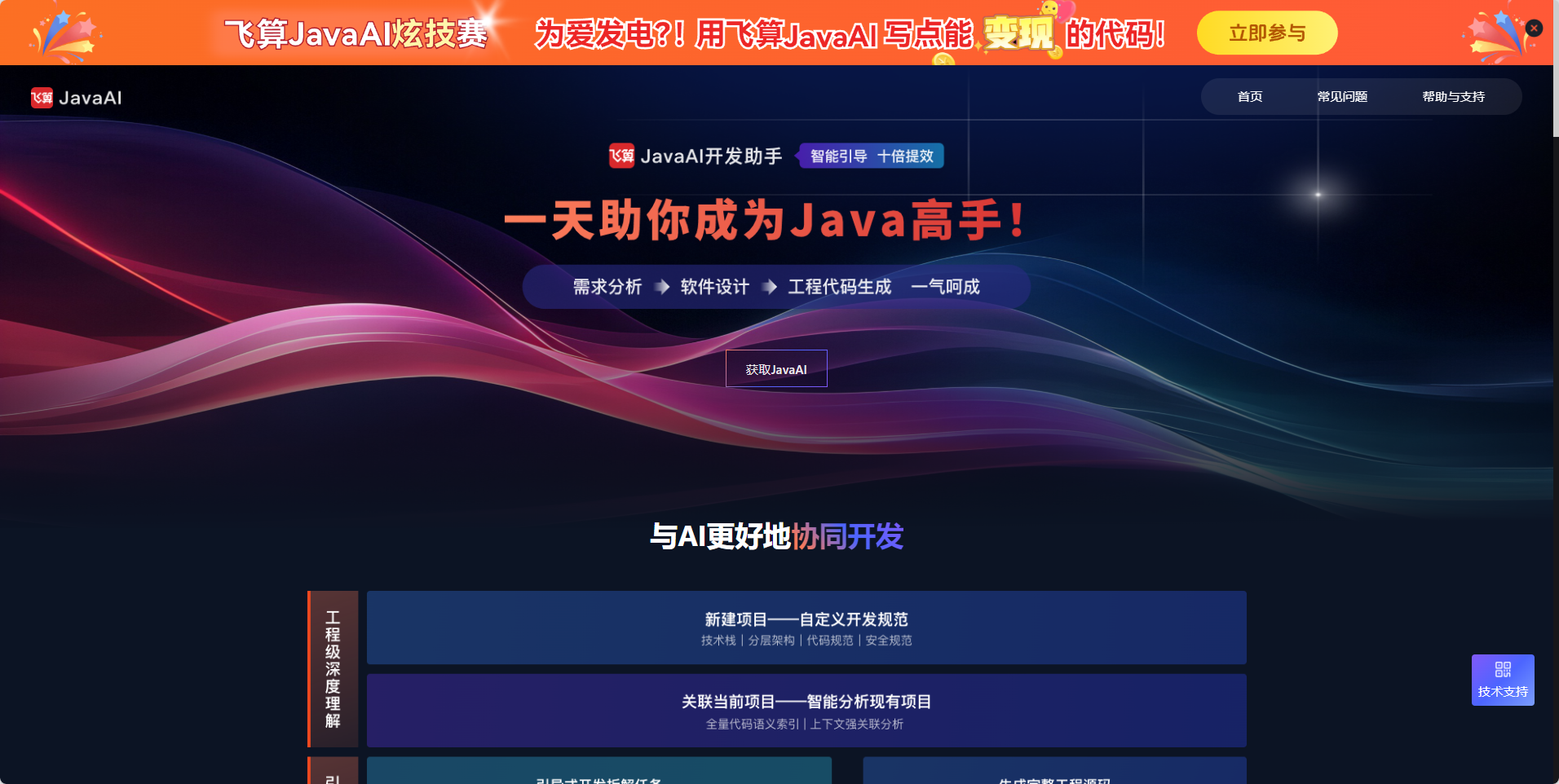
1. 飞算AI 3.2.0核心特性解析
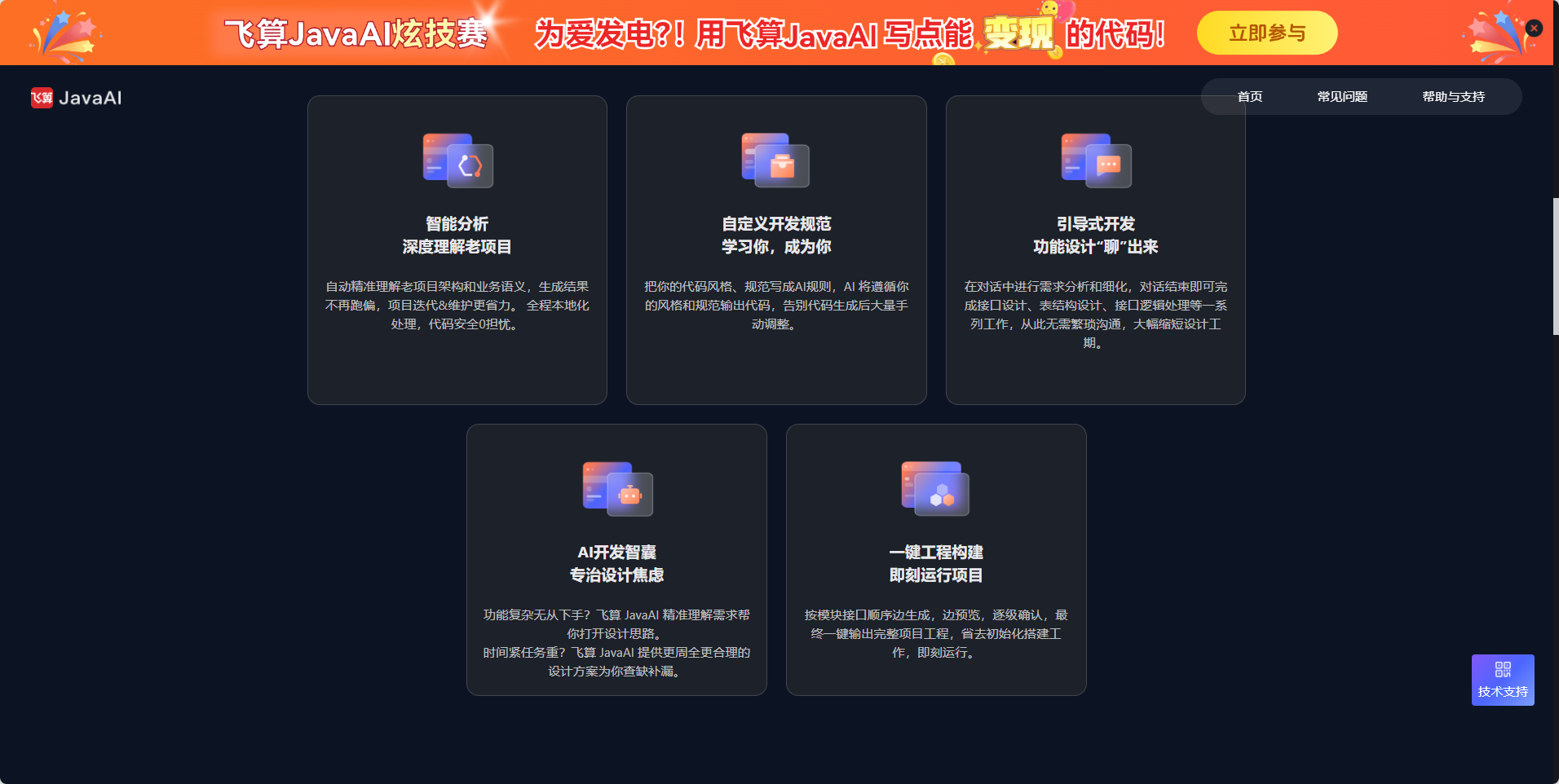
1.1 智能分析引擎升级
飞算AI 3.2.0在智能分析方面实现了质的飞跃。其深度理解老项目的能力让我印象深刻,能够自动识别项目架构模式、业务语义和代码风格。
// 飞算AI智能分析示例:自动识别Spring Boot项目结构
@RestController
@RequestMapping("/api/v1/users")
@Slf4j
public class UserController {
@Autowired
private UserService userService;
// AI自动识别RESTful API设计模式
@GetMapping("/{id}")
public ResponseEntity<UserDTO> getUserById(@PathVariable Long id) {
log.info("获取用户信息,ID: {}", id);
UserDTO user = userService.findById(id);
return ResponseEntity.ok(user);
}
}关键特性分析:
- 语义理解:AI能够理解业务逻辑和数据关系
- 架构识别:自动识别MVC、DDD等架构模式
- 代码风格学习:学习项目中的命名规范和编码习惯
1.2 自定义开发规范
这是3.2.0版本的一大亮点,AI可以学习并遵循你的代码风格和开发规范。
# 自定义开发规范配置示例
development_standards:
naming_convention:
class: PascalCase
method: camelCase
constant: UPPER_SNAKE_CASE
code_style:
max_line_length: 120
indent_size: 4
use_lombok: true
architecture_pattern:
controller_suffix: "Controller"
service_suffix: "Service"
repository_suffix: "Repository"
annotation_preferences:
validation: "@Valid"
transaction: "@Transactional"
cache: "@Cacheable"2. RBAC权限系统架构设计
2.1 系统架构概览
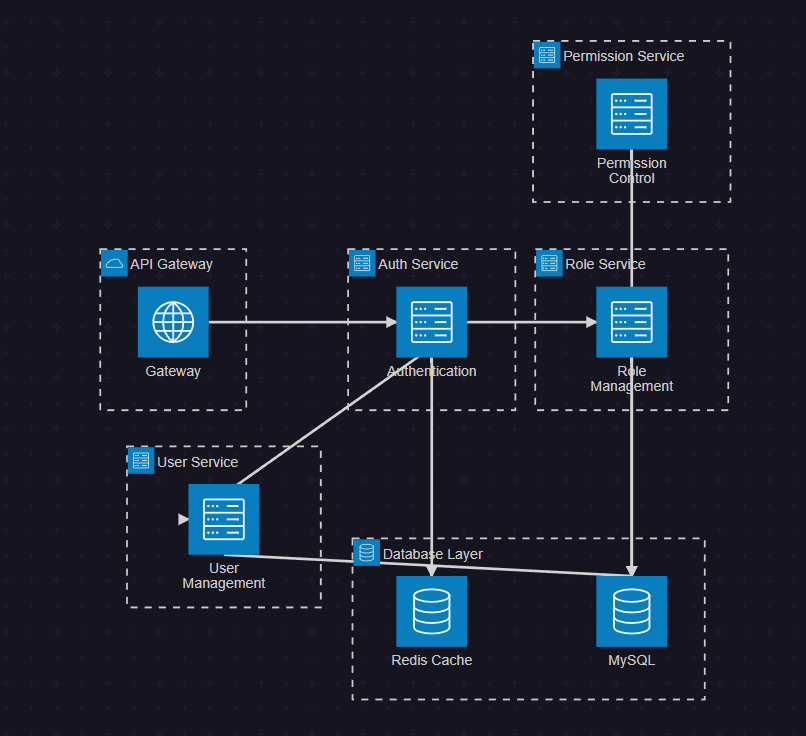
图1:RBAC权限系统架构图 - 展示系统整体架构和服务间关系
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











