




假定被排序的数据是由一组记录组成的表,而每条记录都是有若干数据项组成,其中有一项可以用来标识整个记录,那么称该项为关键字项,该数据项的值就成为关键字。关键字可以用作排序运算的依据。
所谓排序,就是要整理表中的记录,使之按关键字有序排列。
当待排序记录的关键字均不相同时,排序的结果是唯一的,否则,排序结果不一定是唯一的。
如果待排序的表中,存在有多个关键字相同的记录,经过排序后这些具有相同关键字的记录之间的相对次序保持不变,则称这种排序方法是稳定的;反之,称这种排序方法是不稳定的。注:排序算法是稳定性是针对所有的输入实例而言的,即是说,在所有可能的输入实例中,只要有一个实例使得算法不满足稳定性要求,则该算法就是不稳定的。
在排序过程中,若整个表都是放在内存中处理,排序时不涉及数据的内外存交换,则称之为内排序;反之,如果排序过程中要进行数据的内外存交换,则称之为外排序。
内排序适用于记录个数不是很多的小表,而外排序适用于记录个数很多,不能一次全部读入内存的大表。内排序是外排序的基础。
本文主要记录内排序。内排序方法可以分为五类:插入排序、选择排序、交换排序、归并排序、基数排序。
另外本文假定:按关键字升序排序,并且,以顺序表(数组)作为表的存储结构。关键字为int整型,且记录就是该关键字(即该关键字就是整条记录)。
插入排序
基本思想:每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子表中的适当位置,直到全部记录插入完成为止。
直接插入排序
假设待排序记录保存在一个数组R中[0...n-1],在排序的某一个中间时刻,R被分为有序区[0...i-1]和无序区[i...n-1],直接插入排序就是将无序区的第一个记录R[i]插入到有序区的适当位置上,使R[0...i]成为有序区。这种方法通常成为增量法,它使有序区每次增加一个记录。
void insertsortDirect(int rt[], int n)
{
int i,j,tmp;
for(i = 1; i < n; i ++)
{
tmp = rt[i];
j = i - 1;
while(j >= 0 && tmp < rt[j])
{
rt[j+1] = rt[j];
j--;
}
rt[j+1] = tmp;
}
}
二分插入排序
二分插入排序与直接插入排序相比,一个优化点就在于,在有序区查找插入位置的时候,采用了二分查找方法,减少了关键字的比较次数,节省了查找时间。
void insertsortBinary(int rt[], int n)
{
int i, j , low, high, mid, tmp;
for(i = 1; i < n; i++)
{
tmp = rt[i];
low = 0;
high = i - 1;
while(low <= high)
{
mid = (low + high)/2;
if(tmp < rt[mid])
high = mid - 1;
else
low = mid + 1;
}
for(j = i - 1; j >= high + 1; j--)
{
rt[j+1] = rt[j];
}
rt[j+1] = tmp;
}
}
希尔排序
希尔排序实际上是一种分组插入方法。基本思想是 取定一个增量序列,这个增量序列是一个递减序列,且必须以1为结束值。对增量序列中的每个值d,会把表分成的d个组,所有距离为d的倍数的记录会被分在同一个组中,在各组内进行直接插入排序。排序过程按照增量序列中的值从大到小依次进行,直到增量为1的增量值,此时,可以看做对整个表进行了一次直接插入排序。该排序方法的效率取决于增量序列的选取。
入参:incshell是希尔排序递增序列,必须以递增1结束;nshell是递增序列的个数
void insertsortShell(int rt[], int n, int incshell[], int nshell)
{
int i, j, tmp, gap;
while(nshell > 0)
{
gap = incshell[nshell - 1];
for(i = gap; i < n; i++)
{
tmp = rt[i];
j = i - gap;
while(j >= 0 && tmp < rt[j])
{
rt[j+gap] = rt[j];
j = j - gap;
}
rt[j+gap] = tmp;
}
nshell--;
}
}
交换排序
基本思想:两两比较待排序记录的关键字,若发现两个记录的顺序相反,就交换这两个记录,直到没有反序的记录为止。
冒泡排序
基本思想是通过无序区中相邻记录关键字间的比较和位置的交换,使关键字最小的记录如气泡一般逐渐往上“漂浮”直至冒出“水面”,即将关键字最小的记录放在无序区中的第一个首位。
整个算法从最下面的记录开始,在无序区中,对每两个相邻记录的关键字进行比较,且使关键字较小的记录换至关键字较大的记录之上,使得经过一趟冒泡之后,关键字最小的记录到达无序区的最上端。此时,最上端的这个关键字最小的记录被划入有序区。接着,在无序区重复上面的操作。直到无序区中只剩下一个记录。所以,最多进行n-1趟冒泡。
void swapsortBubble(int rt[], int n)
{
int i, j, exg, tmp;
for(i = 0; i < n-1; i++)
{
exg = 0;
for(j = n-1; j > i; j--)
{
if(rt[j] < rt[j-1])
{
tmp = rt[j];
rt[j] = rt[j-1];
rt[j-1] = tmp;
exg = 1;
}
}
if(exg == 0)
return;
}
}
快速排序
基本思想:在待排序的n个记录中任取一个记录(通常取第一个记录),把该记录放入适当位置后,数据序列被此记录划分成两部分。所有关键字比该记录关键字小的记录放置在前一部分,所有关键字比该记录关键字大的记录都放在后一部分,并把该记录排在这两部分的中间(称该记录归为),这个过程称作一趟快速排序。之后分别对划分后的两部分重复上述过程,直至每部分内都只有一个记录或为空为止。简言之,每趟排序使表的第一个元素放入适当位置,将表一分为二,对子表按照递归方式继续这种划分,直至划分的子表长度为0或者1。
一趟排序的划分过程是采用从两头向中间扫描的办法,同时交换与基准记录逆序的记录。
void sortQuick(int rt[], int s, int t)
{
int i = s, j = t, pivot = (s+t)/2;
int tmp;
if(s < t)
{
while(i != j)
{
while(j > i && rt[j] > pivot)
j--;
while(i < j && rt[i] < pivot)
i++;
if(i < j)
{
tmp = rt[i];
rt[i] = rt[j];
rt[j] = tmp;
}
}
sortQuick(rt, s, i-1);
sortQuick(rt, j+1, t);
}
}
void swapsortQuick(int rt[], int n)
{
sortQuick(rt, 0, n-1);
}
选择排序
基本思想:每一趟从待排序的记录中选出关键字最小的记录,顺序放在已经排好序子表的最后,直到全部记录排序完毕。由于选择排序方法每一趟总是从无序区中选出全局最小或者最大的关键字,所以,适合于从大量的记录中选择一部分排序记录。
直接选择排序
假设待排序记录保存在一个数组R中[0...n-1],在排序的某一个中间时刻,R被分为有序区[0...i-1]和无序区[i...n-1],一趟排序则是从当前无序区中选出关键字最小的记录R[k],将它与无序区中的第一个记录R[i]交换,使得R[0...i]和R[i+1...n-1]变为新的有序区和无序区。
每趟排序均使有序区增加了一个记录,且有序区中的记录的关键字均不大于无序区中记录的关键字,所以经过n-1趟排序后,整个表就是递增有序的。
void selectsortDirect(int rt[], int n)
{
int i, j, k, tmp;
for(i = 0; i < n-1; i++)
{
k = i;
for(j = i+1; j < n; j++)
{
if(rt[j] < rt[k])
k = j;
}
if(k != j)
{
tmp = rt[i];
rt[i] = rt[k];
rt[k] = tmp;
}
}
}
堆排序
堆排序是一种树形选择排序方法,它的特点是,在排序过程中,将R[0...n-1]看出是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系,在当前无序区中选择关键字最大或最小的记录。
这里采用的是大根堆,即每次挑选一个关键字最大的记录,然后与无序区中最后一个记录交换。交换后,无序区中的最后一个记录就被划入了有序区。
void heapsift(int rt[], int low, int high)
{
int i = low, j = 2*i;
int tmp = rt[i];
while(j <= high)
{
if(j < high && rt[j] < rt[j+1])
j++;
if(tmp < rt[j])
{
rt[i] = rt[j];
i = j;
j = 2*i;
}
else
break;
}
rt[i] = tmp;
}
void selectsortHeap(int rt[], int n)
{
int i, tmp;
for(i = n/2;i >= 1;i-- )
{
heapsift(rt, i, n);
}
for(i = n-1; i >= 2; i--)
{
tmp = rt[1];
rt[1] = rt[i];
rt[i] = tmp;
heapsift(rt, 1, i-1);
}
}
归并排序
归并排序就是多次将两个或者两个以上的有序表合并成一个新的有序表。最简单的归并是直接将两个有序的子表合并成一个有序的表,即二路归并。
void merge(int rt[], int low, int mid, int high)
{
int *rtp;
int i = low, j = mid+1, k = 0;
rtp = (int *)malloc((high - low + 1)*sizeof(int));
while(i <= mid && j <= high)
{
if(rt[i] <= rt[j])
{
rtp[k] = rt[i];
i++;
k++;
}
else
{
rtp[k] = rt[j];
j++;
k++;
}
}
while(i <= mid)
{
rtp[k] = rt[i];
i++;
k++;
}
while(j <= high)
{
rtp[k] = rt[j];
j++;
k++;
}
for(k = 0,i = low; i <= high; k++, i++)
{
rt[i] = rtp[k];
}
}
void mergesortDec(int rt[], int low, int high)
{
int mid;
if(low < high)
{
mid = (low + high)/2;
mergesortDec(rt, low, mid);
mergesortDec(rt, mid+1, high);
merge(rt, low, mid, high);
}
}
void mergesort(int rt[], int n)
{
mergesortDec(rt, 0, n-1);
}
基数排序
基数排序是通过“分发”和“收集”过程来实现排序,不需要进行关键字之间的比较,是一种借助于多关键字排序的思想对单关键字进行排序的方法。
一般地,记录R[i]的关键字key是由d位数字组成,每一位都在区间[0, r)内,其中,r为基数。eg,二进制的基数r为2,十进制的基数r为10.
基数排序有两种:最低位优先(LSD)和最高位优先(MSD)。最低位优先的过程是:先按最低位的值对记录进行排序,在此基础上,再按次低位进行排序,依次类推。由低位向高位,每趟都是根据关键字的一位并在前一趟的基础上对所有记录进行排序,直至最高位,则完成了基数排序的整个过程。
假设r为基数,记录rec是由d元数组组成,那么,排序过程中讲用到r个队列,用来分配和收集数据。对d元数组的每一位,从低位到高位,依次做“分配”和“收集”,即完成一次排序过程。
分配:开始时,将r个队列清空,根据d元数组的对应位,将记录挂到对应的队列上
收集:将r个队列中的记录依次收尾相连,得到新的记录序列,从而组成新的线性表。
下面的实现参考http://blog.csdn.net/wangzhiyu1980/article/details/7039445
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct Recnode_s
{
int value;
int base;
}RecNode;
int processData(RecNode* pList, int len, int weight)
{
int nValue = 1;
int i=0;
int nFlag = 0;
for (i=0; i< weight; i++)
{
nValue *= 10;
}
for (i=0; i < len; i++)
{
if (weight == 1)
{
(pList+i)->base = (pList+i)->value % nValue;
nFlag = 1;
}
else
{
if ((pList+i)->value >= 0)
(pList+i)->base = -10;
else
(pList+i)->base = -11;
if ((((pList+i)->value < 0)&&((pList+i)->value*(-1) > (nValue/10)))
|| (((pList+i)->value > 0) && ((pList+i)->value > (nValue/10))))
{
(pList+i)->base = ((pList+i)->value%nValue)/(nValue/10);
nFlag = 1;
}
}
}
return nFlag;
}
void radixsort(int arr[], int len)
{
int i = 0;
int j = 0;
int nCnt = 0;
int nWeight = 1;
RecNode* pData = (RecNode*)malloc(len*sizeof(RecNode));
RecNode* pTmpList = (RecNode*)malloc(len*sizeof(RecNode));
for (i = 0; i < len; i++)
{
(pData+i)->value = arr[i];
(pData+i)->base = -10;
}
while(processData(pData, len, nWeight))
{
nCnt = 0;
nWeight++;
for (j = -11; j < 10; j++)
{
for (i=0; i < len; i++)
{
if ((pData+i)->base == j)
{
(pTmpList+nCnt)->value = (pData+i)->value;
nCnt++;
}
}
}
memcpy(pData, pTmpList, sizeof(RecNode)*len);
}
// finished the sort, re-copy the result
for (i=0; i < len; i++)
{
arr[i] = (pData+i)->value;
}
free(pData);
free(pTmpList);
}
内排序性能比较
由于直接输入文本的方式不太好实现下列表格,所以,只有在excel中写好后,截图,直接上传图片了。
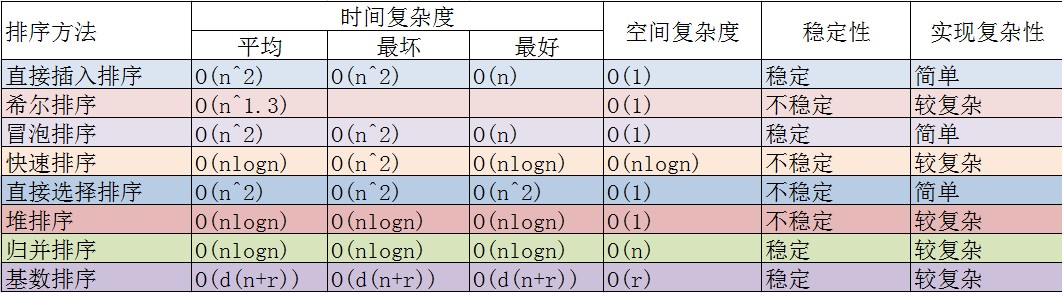
内排序方法选择
没有哪一种方法是绝对好的,每一种方法都有其优缺点,适合于不同的环境。在实际应用中,应该根据具体情况做出选择。
选择合适的排序方法应该综合考虑各种因素:
- 问题规模
- 每个记录的规模
- 关键字的结构及其初始状态
- 对稳定性的要求
- 语言工具的条件
- 存储结构
- 时间和空间复杂度
建议:
- 若问题规模较小,可采用直接插入排序或者直接选择排序。当记录规模较小时,直接插入排序较好;否则,因为直接选择排序移动的记录数少于直接插入排序,应选择直接选择排序为宜。
- 若文件初始状态基本有序,则应选择直接插入、冒泡或随机的快速排序为宜。
- 若问题规模较大,则应采用复杂度较小的排序算法:快速排序、堆排序、归并排序。但,只有归并排序是稳定的。
- 若两个有序表,要将它们合并成一个有序表,最好的方法是归并排序。
- 若问题规模很大,且记录的关键字位数较少、可以分解时,采用基数排序较好。基数排序只适用于像字符串和整数这类有明显结构特征的关键字,而关键字的范围属于某个无穷集合时并无法使用基数排序,只能借助于关键字比较的方法来排序。
- 当从大规模的数据中获取较少的前N个或者最后N个记录时,选择排序是较好的选择。

















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









